The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTFeeding Pascal: GDDR5X
An ongoing problem for every generation of GPUs is the matter of memory bandwidth. As graphics is an embarrassingly parallel problem, it scales out with additional ALUs – and consequently Moore’s Law – relatively well. Each successive generation of GPUs are wider and higher clocked, consuming more data than ever before.
The problem for GPUs is that while their performance tracks Moore’s Law well, the same cannot be said for DRAM. To be sure, DRAM has gotten faster over the years as well, but it hasn’t improved at nearly the same pace as GPUs, and physical limitations ensure that this will continue to be the case. So with every generation, GPU vendors need to be craftier and craftier about how they get more memory bandwidth, and in turn how they use that memory bandwidth.
To help address this problem, Pascal brings to the table two new memory-centric features. The first of which is support for the newer GDDR5X memory standard, which looks to address the memory bandwidth problem from the supply side.

By this point GDDR5 has been with us for a surprisingly long period of time – AMD first implemented it on the Radeon HD 4870 in 2008 – and it has been taken to higher clockspeeds than originally intended. Today’s GeForce GTX 1070 and Radeon RX 480 cards ship with 8Gbps GDDR5, a faster transfer rate than the originally envisioned limit of 7Gbps. That GPU manufacturers and DRAM makers have been able to push GDDR5 so high is a testament to their abilities, but at the same time the technology is clearly reaching its apex (at least for reasonable levels of power consumption)
As a result there has been a great deal of interest in the memory technologies that would succeed GDDR5. At the high end, last year AMD became the first vendor to implement version 1 of High Bandwidth Memory, a technology that is a significant departure from traditional DRAM and uses an ultra-wide 4096-bit memory bus to provide enormous amounts of bandwidth. Not to be outdone, NVIDIA has adopted HBM2 for their HPC-centric GP100 GPU, using it to deliver 720GB/sec of bandwidth for Pascal P100.
While from a technical level HBM is truly fantastic next-generation technology – it uses cutting edge technology throughput, from TSV die-stacking to silicon interposers that connect the DRAM stacks to the processor – its downside is that all of this next-generation technology is still expensive to implement. Precise figures aren’t publicly available, but the silicon interposer is more expensive than a relatively simple PCB, and connecting DRAM dies through TSVs and stacking them is more complex than laying down BGA DRAM packages on a PCB. For NVIDIA, a more cost-effective solution was desired for GP104.
That solution came from Micron and the JEDEC in the form of GDDR5X. A sort of half-generation extension of traditional GDDR5, GDDR5X further increases the amount of memory bandwidth available from GDDR5 through a combination of a faster memory bus coupled with wider memory operations to read and write more data from DRAM per clock. And though it’s not without its own costs such as designing new memory controllers and boards that can accommodate the tighter requirements of the GDDR5X memory bus, GDDR5X offers a step in performance between the relatively cheap and slow GDDR5, and relatively fast and expensive HBM2.
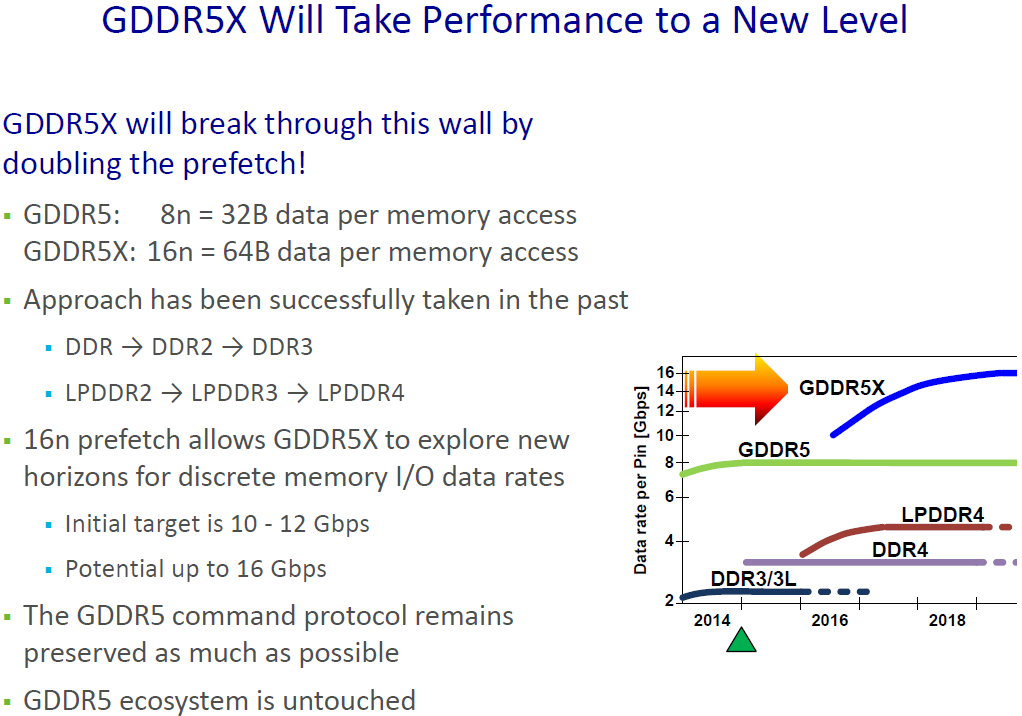
Relative to GDDR5, the significant breakthrough on GDDR5X is the implementation of Quad Data Rate (QDR) signaling on the memory bus. Whereas GDDR5’s memory bus would transfer data twice per write clock (WCK) via DDR, GDDR5X extends this to four transfers per clock. All other things held equal, this allows GDDR5X to transfer twice as much data per clock as GDDR5.
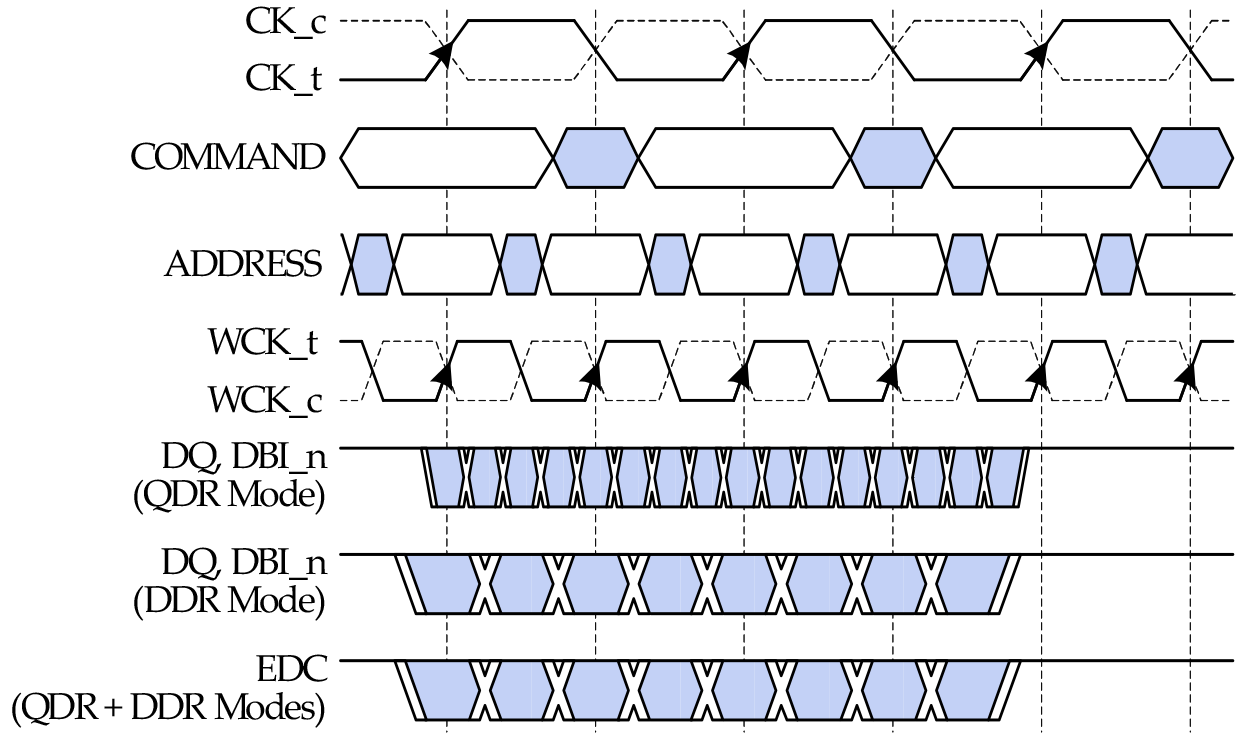
QDR itself is not a new innovation – Intel implemented a quad pumped bus 15 years ago for the Pentium 4 with AGTL+ – but this is the first time it has been implemented in a common JEDEC memory standard. The history of PC memory standards is itself quite a tale, and I suspect that the fact we’re only seeing a form of QDR now is related to patents. But regardless, here we are.
Going hand-in-hand with the improved transfer rate of the GDDR5X memory bus, GDDR5X also once again increases the size of read/write operations, as the core clockspeed of GDDR5X chips is only a fraction of the bus speed. GDDR5X uses a 16n prefetch, which is twice the size of GDDR5’s 8n prefetch. This translates to 64B reads/writes, meaning that GDDR5X memory chips are actually fetching (or writing) data in blocks of 64 bytes, and then transmitting it over multiple cycles of the memory bus. As discussed earlier, this change in the prefetch size is why the memory controller organization of GP104 is 8x32b instead of 4x64b like GM204, as each memory controller can now read and write 64B segments of data via a single memory channel.

Overall GDDR5X is planned to offer enough bandwidth for at least the next couple of years. The current sole supplier of GDDR5X, Micron, is initially developing GDDR5X from 10 to 12Gbps, and the JEDEC has been talking about taking that to 14Gbps. Longer term, Micron thinks the technology can hit 16Gbps, which would be a true doubling of GDDR5’s current top speed of 8Gbps. With that said, even with a larger 384-bit memory bus (ala GM200) this would only slightly surpass what kind of bandwidth HBM2 offers today, reinforcing the fact that GDDR5X will fill the gap between traditional GDDR5 and HBM2.
Meanwhile when it comes to power consumption and power efficiency, GDDR5X will turn back the clock, at least a bit. Thanks in large part to a lower operating voltage of 1.35v, circuit design changes, and a smaller manufacturing node for the DRAM itself, 10Gbps GDDR5X only requires as much power as 7Gbps GDDR5. This means that relative to GTX 980, GTX 1080’s faster GDDR5X is essentially “free” from a power perspective, not consuming any more power than before, according to NVIDIA.
That said, while this gets NVIDIA more bandwidth for the same power – 43% more, in fact – NVIDIA has now put themselves back to where they were with GTX 980. GDDR5X can scale higher in frequency, but doing so will almost certainly further increase power consumption. As a result they are still going to have to carefully work around growing memory power consumption if they continue down the GDDR5X path for future, faster cards.

On a final specification note, GDDR5X also introduces non-power-of-two memory chip capacities such as 12Gb. These aren’t being used for GTX 1080 – which uses 8Gb chips – but I wouldn’t be surprised if we see these used down the line. The atypical sizing would allow NVIDIA to offer additional memory capacities without resorting to asymmetrical memory configurations as is currently the case, all the while avoiding the bandwidth limitations that can result from that.
Moving on to implementation details, GP104 brings with it a new memory controller design to support GDDR5X. As intended with the specification, this controller design is backwards compatible with traditional GDDR5, and will allow NVIDIA to support both memory standards. At this point NVIDIA hasn’t talked about what kinds of memory speeds their new controller can ultimately hit, but the cropped signal analysis diagram published in their slide deck shows a very tight eye. Given the fact that NVIDIA’s new memory controller can operate at 8Gbps in GDDR5 mode, I would be surprised if we don’t see at least 12Gbps GDDR5X by the tail-end of Pascal’s lifecycle.
But perhaps the bigger challenge is on the board side of matters, where NVIDIA and their partners needed to develop PCBs capable of handling the tighter signaling requirements of the GDDR5X memory bus. At this point video cards are moving 10Gbps/pin over a non-differential bus, which is itself a significant accomplishment. And keep in mind that in the long run, the JEDEC and Micron want to push this higher still.
To that end it somewhat undersells the whole process to just say that GDDR5X required “tighter signaling requirements”, but it’s an apt description. There is no single technology in place on the physical trace side to make this happen; it’s just a lot of precision, intensive work into ensuring that the traces and the junctions between the PCB, the chip, and the die all retain the required signal integrity. With a 256-bit wide bus we’re not looking at something too wide compared to the 384 and 512-bit buses uses on larger GPUs, so the task is somewhat simpler in that respect, but it’s still quite a bit of effort to minimize the crosstalk and other phenomena that degrade the signal, and which GDDR5X has little tolerance for.
As it stands I suspect we have not yet seen the full ramifications of the tighter bus requirements, and we probably won’t for cards that use the reference board or the memory design lifted from the reference board. For stability reasons, data buses are usually overengineered, and it’s likely the GDDR5X memory itself that’s holding back overclocking. Things will likely get more interesting if and when GDDR5X filters its way down to cheaper cards, where keeping costs in check and eking out higher margins becomes more important. Alternatively, as NVIDIA’s partners get more comfortable with the tech and its requirements, it’ll be interesting to see where we end up with the ultra-high-end overclocking cards –the Kingpins, Lightnings, Matrices, etc – and whether all of the major partners can keep up in that race.








200 Comments
View All Comments
Ryan Smith - Wednesday, July 20, 2016 - link
To follow: GTX 1060 Review (hopefully Friday), RX 480 Architecture Writeup/Review, and at some point RX 470 and RX 460 are still due.Chillin1248 - Wednesday, July 20, 2016 - link
Nice, don't worry about the rushers. There are plenty of day one reviewers, but few go into depth the way that makes it interesting.retrospooty - Wednesday, July 20, 2016 - link
Agreed, this is a good review, as the video card reviews here usually are... Agreed about rushing as well. A lot of sites have less thorough stuff out in 1-2 days... I am guessing that Ryan and the others at Anandtech have regular day jobs and doing these reviews and articles is done on their own time. If that is the case, 2 months seems right. If I am incorrect in that assumption and this is a full time job, then they should be coming out with articles alot faster.JoshHo - Wednesday, July 20, 2016 - link
Currently for mobile the only full time editor is Matt Humrick.AndrewJacksonZA - Wednesday, July 20, 2016 - link
Thank you Ryan. I look forward to more and reliable information about the 470 and especially the 460.prophet001 - Wednesday, July 20, 2016 - link
Hi All, I was just wondering if it's worth it to get the FE 1080 or just go with the regular one. Does the stock fan setup offer better thermals than the blower setup?Teknobug - Wednesday, July 20, 2016 - link
FE is a ripoffImSpartacus - Wednesday, July 20, 2016 - link
It's literally just the reference card. It's not a bad reference design, but it's generally considered a poor value for enthusiasts.HomeworldFound - Wednesday, July 20, 2016 - link
A reference design is very useful if you're watercooling though.trab - Wednesday, July 20, 2016 - link
Depends if your custom board has any actual changes, it may just be the reference board with a custom cooler, so it would make no difference. Of course it would also be cheaper to boot.