AMD Launches Opteron 6300 series with "Piledriver" cores
by Johan De Gelas on November 5, 2012 12:00 PM EST- Posted in
- IT Computing
- CPUs
- AMD
- Opteron
- Abu Dhabi
- Piledriver
Performance According to AMD
For the first time in Opteron history, AMD was not able to provide us with samples before the launch. We are working with them to make sure we can show our independent benchmarks. Until then we have to work with what we AMD has published.
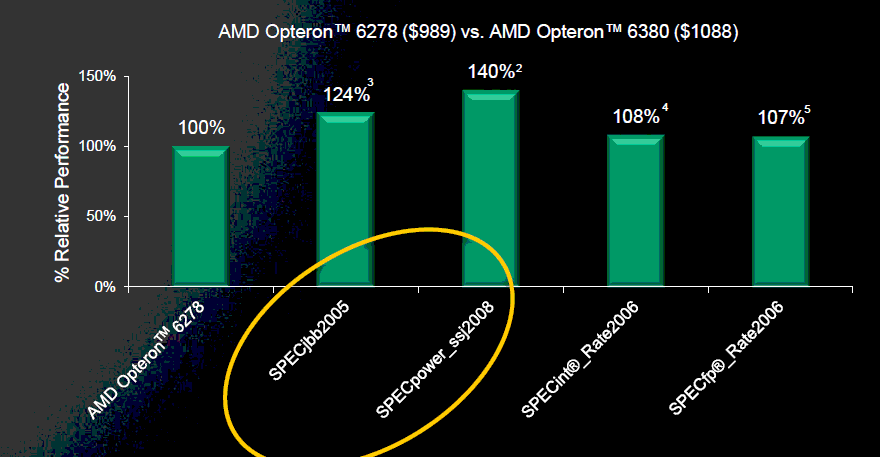
The clock speed advantage of the 6380 at 2.5GHz is 4%, so the SPEC CPU tests show that Piledriver is about 4% more effficient per clock when we focus on high IPC, low MLP benchmarks. However, as we have shown in previous articles, server applications behave very differently from SPEC CPU benchmarks.
AMD claims 24% higher performance in the Java benchmark SPECJBB, but that is an inflatable benchmark. We do not want to dismiss the benchmark result immediately, but AMD does not disclose the JVM settings. The following settings were disclosed:
The Opteron 6380 based server:
77.9W at Active Idle, 308W and 1,636,298 ssj_ops at 100% of target load, and 4,040 overall ssj_ops/watt using 2 x AMD Opteron™ processors Model 6380 in Supermicro 1022G-NTF server, 64GB (8 x 8GB DDR3-1600) memory, Supermicro PWS-563-1H20 power supply, 240GB SATA disk drive, Microsoft® Windows Server® 2008 R2 x64 Enterprise Edition.
The Opteron 6278 based server:
82.6W at Active Idle, 320W and 1,233,423 ssj_ops at 100% of target load, and 2,892 overall ssj_ops/watt using 2 x AMD Opteron™ processors Model 6278 in Supermicro 1022G-NTF server, 64GB (8 x 8GB DDR3-1600) memory, Supermicro PWS-563-1H20 power supply, 240GB SATA disk drive, Microsoft® Windows Server® 2008 R2 x64 Enterprise Edition.
It is very likely that some new JVM performance boosting tricks contribute more to the performance increase than better processor performance. Most of those JVM tricks are unacceptable in a real-world Java application, so we fear that the SPECJBB results tell us very little. As just one example, AMD uses 16 JVMs on 32 integer cores to obtain the SPECJBB results. That means that each JVM is running on one module, minimizing the coherency traffic and optimizing the cache hits. Of course everybody that posts these SPECJBB scores uses these kinds of very unrealistic settings, but it also means that we can deduce very little about the real performance increase that the Piledriver cores offer.
The power numbers of the SPECPower_ssj2008 benchmarks make us somewhat optimistic though. The 40% increase in performance/watt is clearly not the result of JVM performance tricks alone. The idle and maximum power numbers also confirm that the Opteron 6300 is quite a bit more efficient in server loads than the 6200. We estimate that the new Opteron offers a 20% (or better) higher performance/watt ratio in the real world. Let us wrap up with a look at the SKUs and prices.








22 Comments
View All Comments
Notperk - Monday, November 5, 2012 - link
Wouldn't it be better to compare these CPUs to Intel's E7 series enterprise server CPUs? I ask this, because of how technically an Opteron 6386 SE is two CPUs in one. Therefore, two of these would actually be four CPUs and would be a direct competitor (at least in terms of class) to four E7-4870s. If you went even further, four of those Opterons would be a competitor to eight E7-8870s. I understand that, performance wise, these are more similar to the E5s, but it just makes more sense to me to place them higher as enterprise server CPUs.MrSpadge - Monday, November 5, 2012 - link
It's actually the other way around: there may be 2 dies inside each CPU, but even combined they get less work done than the Intel chips in most situations. However, comparing a 4-socket Opti system with a 2-socket Intel system, which cost approximately the same to purchase, can get very interesting: massive memory capacity and bandwidth, lot's of threads for integer throughput and quite a few FPUs. With the drawback of much higher running costs through electricity costs, of course.leexgx - Tuesday, November 6, 2012 - link
Happy that the reviewer correctly got the module/cores right (as the Integer cores are more like hyper threading but not)in any case should compare the amd modules count to intel cpu cores
(amd should be marketing them the same way, 4 module cpus with core assist, that are slower or the same as an phenom x4 real world use, its like saying an i7 is an 8 core cpu when its about the same speed of an i5 that lacks HT)
RicardoNeuer - Thursday, November 8, 2012 - link
my co-worker's mother makes $60 an hour on the computer. She has been out of work for nine months but last month her pay was $13948 just working on the computer for a few hours. Read more on this(Click on menu Home more information)
http://goo.gl/v6dOM
thebluephoenix - Tuesday, November 6, 2012 - link
E7 is nehalem, old technology. E5-2687W and E5-2690 are actual competition (~Double 2600K vs ~Double FX-8350)JohanAnandtech - Tuesday, November 6, 2012 - link
Minor nitpick: E7 is Westmere, improved Nehalem.http://www.anandtech.com/show/4285/westmereex-inte...
But E5 is indeed the real competition. E7 is less about performance/Watt, but more about RAS and high scalability (corecounts of 40, up to 80 threads)
alpha754293 - Monday, November 5, 2012 - link
I don't know if I would say that. Course, I'm biased because I'm somewhat in HPC. But I think that the HPC will also give an idea of how well (or how poorly) a highly multi-threaded/multi-processor capable/aware application is going to perform.In some HPC cases, having more integer cores is probably going to be WORSE since it's still fighting for FPU resources. And that running it on more processors isn't always necessarily better either (higher intercore communication traffic).
MrSpadge - Monday, November 5, 2012 - link
If you compare a 4-socket Opti to a 2-socket Intel (comparable purchase cost) you can get massive memory bandwidth, which might be enough to tip the scale in Optis favor in some HPC applications. They need to profit from many cores and require this bandwdith, though.Personally for genereal HPC jobs I prefer less cores with higher IPC and clock speed (i.e. Intel), as they're more generally useful.
alpha754293 - Friday, November 9, 2012 - link
I can tell you from experience that it really depends on the type of HPC workload.For FEA, if you can store the large matrices in the massive amount of memory that the Opterons can handle (upto 512 GB for a quad-socket system) - it can potentially help*.
*You have to disable swap so that you don't get bottlenecked by the swap I/O performance.
Then you'd really be able to rock 'n roll being able to solve the matrices entirely in-core.
For molecular dynamics though - it's not really that memory intensive (compared to structural mechanics FEA) but it's CPU intensive.
For CFD, that's also very CPU intensive.
And even then it also depends too on how the solvers are written and what you're doing.
CFD - you need to pass the pressure, velocity, and basically the information/state information about the fluid parcel from one cell to another; so if you partition the model at the junction and you need to transfer information from one cell on one core on one socket to another core sitting on another CPU sitting in another physical socket - then it's memory I/O limited. And most commercial CFD codes that I know of that enables MPI/MPP processing - they actually do somewhat of a local remesh at the partition boundaries so they actually create extra elements just to facilitate the data information transfer/exchange (and to make sure that the data/information is stable).
So there's a LOT that goes into it.
Same with crash safety simulations and explicit dynamics structural mechanics (like LS-DYNA) because that's an energy solver, so what happens to one element will influence what happens at your current element and that in turn will influence what happens at the next element. And for LS-DYNA, *MPP_DECOMPOSITION_<OPTION> can further tell how you want the problem to be broken down specifically (and you can do some pretty neat stuff with it) in order to make the MPI/MPP solver even more efficient.
If you have a problem where what happens with one doesn't really have that much of an impact on another element (such as fatigue analysis - done at the finite element level) - you can process all of the elements individually, so having lots of cores means you can run it at lot faster.
But for problems where there's a lot of "bi-directional" data/communication (hypersonic flow/shock wave for example) - then I THINK (if I remember correctly), the communication penalty is something like O(n^2) or O(n^3). So the CS side to an HPC problem is trying to optimize between these two. Run as many cores as possible, with as little communication as possible (so it doesn't slow you down), as fast as possible, as independently possible, and pass ONLY the information you NEED to pass along, WHEN you need to pass it along and try and do as much of it in-core as possible.
And then to throw a wrench into that whole thing - the physics of the simulations basically is a freakin' hurricane on that whole parade (the physics makes a lot of that either very difficult or near impossible or outright impossible).
JohanAnandtech - Monday, November 5, 2012 - link
I would not even dream of writing that! HPC software can be so much more fun than other enterprise software: no worries about backup or complex High Availability setups. No just focussing on performance and enjoying the power of your newest chip.I was talking about the HPC benchmarks that AMD reports. Not all HPC benchmarks can be recompiled and not all of them will show such good results with FMA. Those are very interesting, but they only give a very limited view.
For the rest: I agree with you.