NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
The graph below is one of transistor count, not die size. Inevitably, on the same manufacturing process, a significantly higher transistor count translates into a larger die size. But for the purposes of this article, all I need to show you is a representation of transistor count.
![]()
See that big circle on the right? That's Fermi. NVIDIA's next-generation architecture.
NVIDIA astonished us with GT200 tipping the scales at 1.4 billion transistors. Fermi is more than twice that at 3 billion. And literally, that's what Fermi is - more than twice a GT200.
At the high level the specs are simple. Fermi has a 384-bit GDDR5 memory interface and 512 cores. That's more than twice the processing power of GT200 but, just like RV870 (Cypress), it's not twice the memory bandwidth.
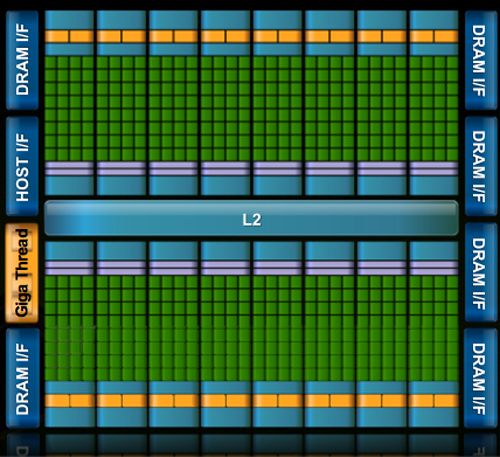
The architecture goes much further than that, but NVIDIA believes that AMD has shown its cards (literally) and is very confident that Fermi will be faster. The questions are at what price and when.
The price is a valid concern. Fermi is a 40nm GPU just like RV870 but it has a 40% higher transistor count. Both are built at TSMC, so you can expect that Fermi will cost NVIDIA more to make than ATI's Radeon HD 5870.
Then timing is just as valid, because while Fermi currently exists on paper, it's not a product yet. Fermi is late. Clock speeds, configurations and price points have yet to be finalized. NVIDIA just recently got working chips back and it's going to be at least two months before I see the first samples. Widespread availability won't be until at least Q1 2010.
I asked two people at NVIDIA why Fermi is late; NVIDIA's VP of Product Marketing, Ujesh Desai and NVIDIA's VP of GPU Engineering, Jonah Alben. Ujesh responded: because designing GPUs this big is "fucking hard".
Jonah elaborated, as I will attempt to do here today.








415 Comments
View All Comments
hazarama - Saturday, October 3, 2009 - link
"Do you see any sign of commercial software support? Anybody Nvidia can point to and say "they are porting $important_app to openCL"? I haven't heard a mention. That pretty much puts Nvidia's GPU computing schemes solely in the realm of academia"Maybe you should check out Snow Leopard ..
samspqr - Friday, October 2, 2009 - link
Well, I do HPC for a living, and I think it's too early to push GPU computing so hard because I've tried to use it, and gave up because it required too much effort (and I didn't know exactly how much I would gain in my particular applications).I've also tried to promote GPU computing among some peers who are even more hardcore HPC users, and they didn't pick it up either.
If even your typical physicist is scared by the complexity of the tool, it's too early.
(as I'm told, there was a time when similar efforts were needed in order to use the mathematical coprocessor...)
Yojimbo - Sunday, October 4, 2009 - link
>>If even your typical physicist is scared by the complexity of the >>tool, it's too early.This sounds good but it's not accurate. Physicists are interested in physics and most are not too keen on learning some new programing technique unless it is obvious that it will make a big difference for them. Even then, adoption is likely to be slow due to inertia. Nvidia is trying to break that inertia by pushing gpu computing. First they need to put the hardware in place and then they need to convince people to use it and put the software in place. They don't expect it to work like a switch. If they think the tools are in place to make it viable, then how is the time to push, because it will ALWAYS require a lot of effort when making the switch.
jessicafae - Saturday, October 3, 2009 - link
Fantastic article.I do bioinformatics / HPC and in our field too we have had several good GPU ports for a handful for algorithms, but nothing so great to drive us to add massive amounts of GPU racks to our clusters. With OpenCL coming available this year, the programming model is dramatically improved and we will see a lot more research and prototypes of code being ported to OpenCL.
I feel we are still in the research phase of GPU computing for HPC (workstations, a few GPU racks, lots of software development work). I am guessing it will be 2+ years till GPU/stream/OpenCL algorithms warrant wide-spread adoption of GPUs in clusters. I think a telling example is the RIKEN 12petaflop supercomputer which is switching to a complete scalar processor approach (100,000 Sparc64 VIIIfx chips with 800,000 cores)
http://www.fujitsu.com/global/news/pr/archives/mon...">http://www.fujitsu.com/global/news/pr/archives/mon...
Thatguy97 - Thursday, May 28, 2015 - link
oh fermi how i miss ya hot underperforming ass