NVIDIA Tegra X1 Preview & Architecture Analysis
by Joshua Ho & Ryan Smith on January 5, 2015 1:00 AM EST- Posted in
- SoCs
- Arm
- Project Denver
- Mobile
- 20nm
- GPUs
- Tablets
- NVIDIA
- Cortex A57
- Tegra X1
Tegra X1's GPU: Maxwell for Mobile
Going into today’s announcement of the Tegra X1, while NVIDIA’s choice of CPU had been something of a wildcard, the GPU was a known variable. As announced back at GTC 2014, Erista – which we now know as Tegra X1 – would be a future Tegra product with a Maxwell GPU.
Maxwell of course already launched on the PC desktop as a discrete GPU last year in the Maxwell 1 based GM107 and Maxwell 2 based GM204. However despite this otherwise typical GPU launch sequence, Maxwell marks a significant shift in GPU development for NVIDIA that is only now coming to completion with the launch of the X1. Starting with Maxwell, NVIDIA has embarked on a “mobile first” design strategy for their GPUs; unlike Tegra K1 and its Kepler GPU, Maxwell was designed for Tegra from the start rather than being ported after the fact.
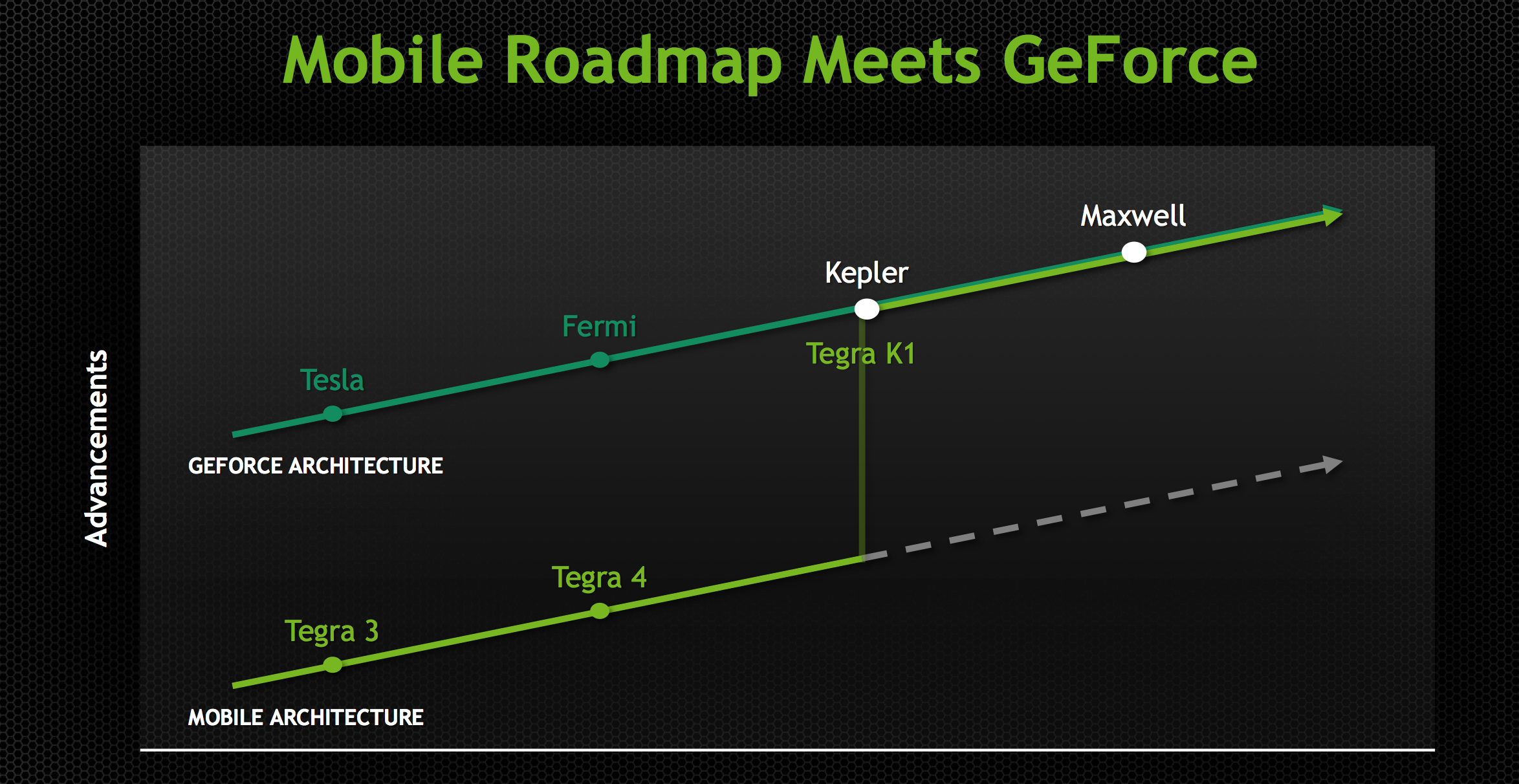
By going mobile-first NVIDIA has been able to reap a few benefits. On the Tegra side in particular, mobile-first means that NVIDIA’s latest and greatest GPUs are appearing in SoCs earlier than ever before – the gap between Maxwell 1 and Tegra X1 is only roughly a year, versus nearly two years for Kepler in Tegra K1. But it also means that NVIDIA is integrating deep power optimizations into their GPU architectures at an earlier stage, which for their desktop GPUs has resulted chart-topping power efficiency, and these benefits are meant to cascade down to Tegra as well.
Tegra X1 then is the first SoC to be developed under this new strategy, and for NVIDIA this is a very big deal. From a feature standpoint NVIDIA gets to further build on their already impressive K1 feature set with some of Maxwell’s new features, and meanwhile from a power standpoint NVIDIA wants to build the best A57 SoC on the market. With everyone else implementing (roughly) the same CPU, the GPU stands to be a differentiator and this is where NVIDIA believes their GPU expertise translates into a significant advantage.
Diving into the X1’s GPU then, what we have is a Tegra-focused version of Maxwell 2. Compared to Kepler before it, Maxwell 2 introduced a slew of new features into the NVIDIA GPU architecture, including 3rd generation delta color compression, streamlined SMMs with greater efficiency per CUDA core, and graphics features such as conservative rasterization, volumetric tiled resources, and multi-frame anti-aliasing. All of these features are making their way into Tegra X1, and for brevity’s sake rather than rehashing all of this we’ll defer to our deep dive on the Maxwell 2 architecture from the launch of the GeForce GTX 980.
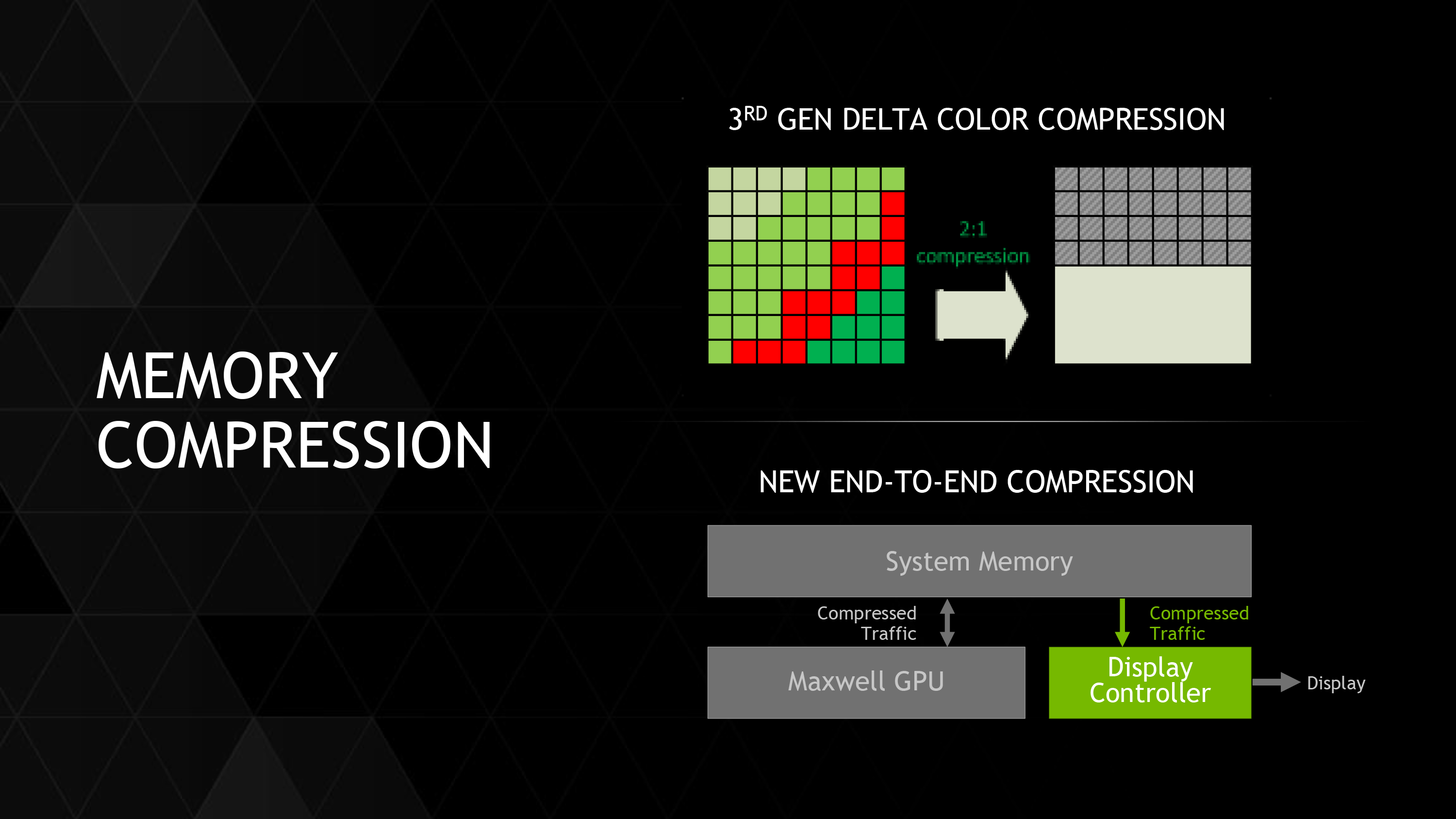
For X1 in particular, while every element helps, NVIDIA’s memory bandwidth and overall efficiency increases are going to be among the most important of these improvements since they address two of the biggest performance bottlenecks facing SoC-class GPUs. In the case of memory bandwidth optimizations, memory bandwidth has long been a bottleneck at higher performance levels and resolutions, and while it’s a solvable problem, the general solution is to build a wider (96-bit or 128-bit) memory bus, which is very effective but also drives up the cost and complexity of the SoC and the supporting hardware. In this case NVIDIA is sticking to a 64-bit memory bus, so memory compression is very important for NVIDIA to help drive X1. This coupled with a generous increase in memory bandwidth from the move to LPDDR4 helps to ensure that X1’s more powerful GPU won’t immediately get starved at the memory stage.
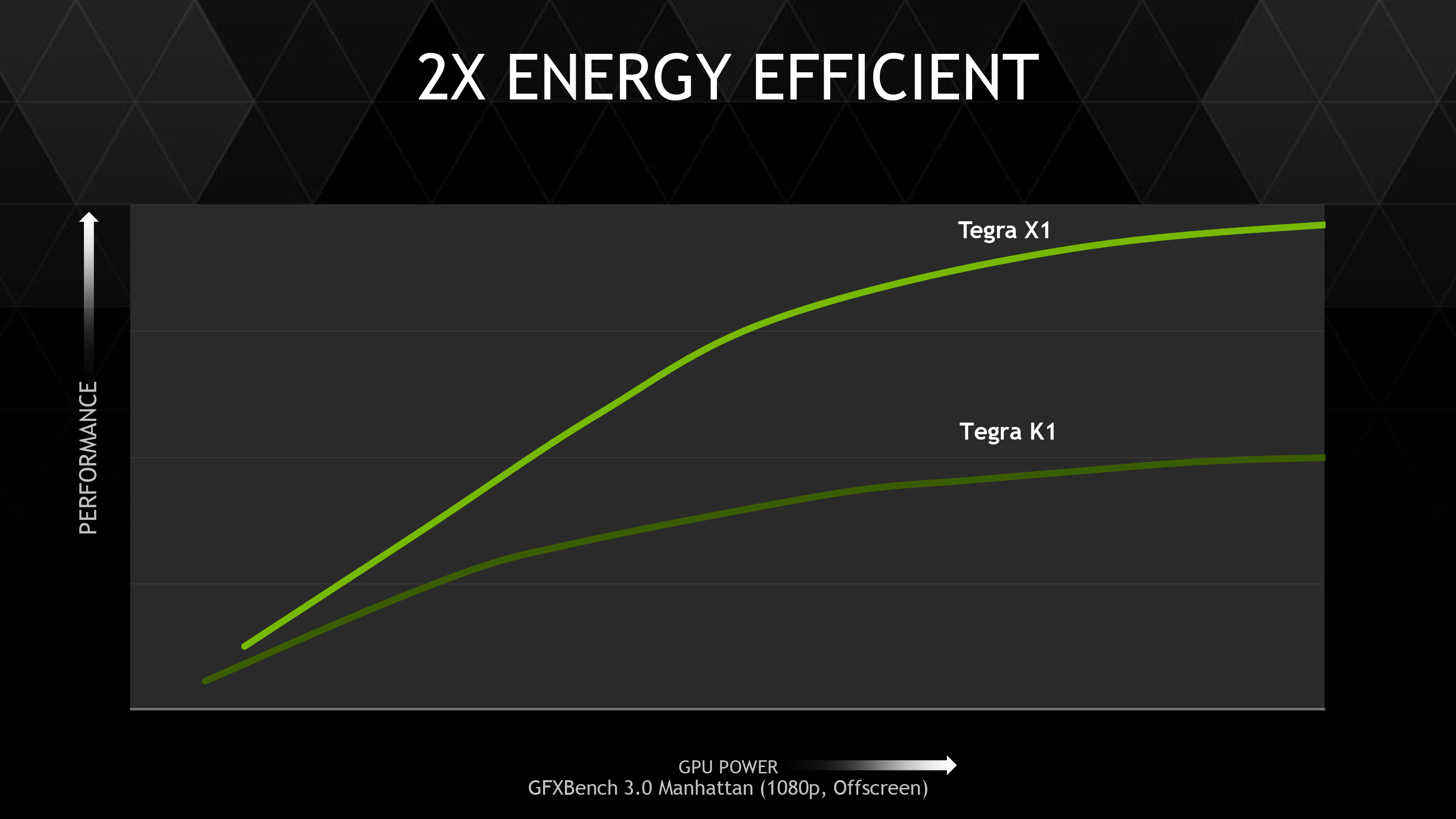
Meanwhile just about everything about SoC TDP that can be said has been said. TDP is a limiting factor in all modern mobile devices, which means deceased power consumption directly translates into increased performance, especially under sustained loads. Coupled with TSMC’s 20nm SoC process, Maxwell’s power optimizations will further improve NVIDIA’s SoC GPU performance.
Double Speed FP16
Last but certainly not least however, X1 will also be launching with a new mobile-centric GPU feature not found on desktop Maxwell. For X1 NVIDIA is implanting what they call “double speed FP16” support in their CUDA cores, which is to say that they are implementing support for higher performance FP16 operations in limited circumstances.
As with Kepler and Fermi before it, Maxwell only features dedicated FP32 and FP64 CUDA cores, and this is still the same for X1. However in recognition of how important FP16 performance is, NVIDIA is changing how they are handling FP16 operations for X1. On K1 FP16 operations were simply promoted to FP32 operations and run on the FP32 CUDA cores; but for X1, FP16 operations can in certain cases be packed together as a single Vec2 and issued over a single FP32 CUDA core.
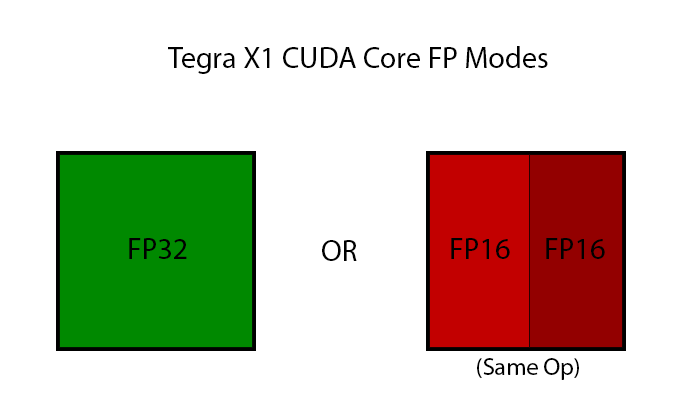
There are several special cases here, but in a nutshell NVIDIA can pack together FP16 operations as long as they’re the same operation, e.g. both FP16s are undergoing addition, multiplication, etc. Fused multiply-add (FMA/MADD) is also a supported operation here, which is important for how frequently it is used and is necessary to extract the maximum throughput out of the CUDA cores.
In this respect NVIDIA is playing a bit of catch up to the competition, and overall it’s hard to escape the fact that this solution is a bit hack-ish, but credit where credit is due to NVIDIA for at least recognizing and responding to what their competition has been doing. Both ARM and Imagination have FP16 capabilities on their current generation parts (be it dedicated FP16 units or better ALU decomposition), and even AMD is going this route for GCN 1.2. So even if it only works for a few types of operations, this should help ensure NVIDIA doesn’t run past the competition on FP32 only to fall behind on FP16.
So why are FP16 operations so important? The short answer is for a few reasons. FP16 operations are heavily used in Android’s display compositor due to the simplistic (low-precision) nature of the work and the power savings, and FP16 operations are also used in mobile games at certain points. More critical to NVIDIA’s goals however, FP16 can also be leveraged for computer vision applications such as image recognition, which NVIDIA needs for their DRIVE PX platform (more on that later). In both of these cases FP16 does present its own limitations – 16-bits just isn’t very many bits to hold a floating point number – but there are enough cases where it’s still precise enough that it’s worth the time and effort to build in the ability to process it quickly.
Tegra X1 GPU By The Numbers
Now that we’ve covered the X1’s GPU from a feature perspective, let’s take a look the GPU from a functional unit/specification perspective.

Overall the X1’s GPU is composed of 2 Maxwell SMMs inside a single GPC, for a total of 256 CUDA cores. This compares very favorably to the single SMX in K1, as it means certain per-SMM/SMX resources such as the geometry and texture units have been doubled. Furthermore Maxwell’s more efficient CUDA cores means that X1 is capable of further extending its lead over Kepler, as we’ve already seen in the desktop space.
| NVIDIA Tegra GPU Specification Comparison | ||||
| K1 | X1 | |||
| CUDA Cores | 192 | 256 | ||
| Texture Units | 8 | 16 | ||
| ROPs | 4 | 16 | ||
| GPU Clock | ~950MHz | ~1000MHz | ||
| Memory Clock | 930MHz (LPDDR3) | 1600MHz (LPDDR4) | ||
| Memory Bus Width | 64-bit | 64-bit | ||
| FP16 Peak | 365 GFLOPS | 1024 GFLOPS | ||
| FP32 Peak | 365 GFLOPS | 512 GFLOPS | ||
| Architecture | Kepler | Maxwell | ||
| Manufacturing Process | TSMC 28nm | TSMC 20nm SoC | ||
Meanwhile outside of the CUDA cores NVIDIA has also made an interesting move in X1’s ROP configuration. At 16 ROPs the X1 has four times the ROPs of K1, and is consequently comparatively ROP heavy. This is as many ROPs as is on a GM107 GPU, for example. With that said, due to NVIDIA’s overall performance goals and their desire to drive 4K displays at 60Hz, there is a definite need to go ROP-heavy to make sure they can push the necessary amount of pixels. This also goes hand-in-hand with NVIDIA’s memory bandwidth improvements (efficiency and actual) which will make it much easier to feed those ROPs. This also puts the ROP:memory controller ratio at 16:1, the same ratio as on NVIDIA’s desktop Maxwell parts.
Finally, let’s talk about clockspeeds and expected performance. While NVIDIA is not officially publishing the GPU clockspeeds for the X1, based on their performance figures it’s easy to figure out. With NVIDIA’s quoted (and promoted) 1 TFLOPs FP16 performance figure for the X1, the clockspeed works out to a full 1GHz for the GPU (1GHz * 2 FP 16 * 2 FMA * 256 = 1 TFLOPs).
This is basically a desktop-class clockspeed, and it goes without saying that is a very aggressive GPU clockspeed for an SoC-class part. We’re going to have to see what design wins X1 lands and what the devices are like, but right now it’s reasonable to expect that mobile devices will only burst here for short periods of time at best. However NVIDIA’s fixed platform DRIVE devices are another story; those can conceivably be powered and cooled well enough that the X1’s GPU can hit and sustain these clockspeeds.








194 Comments
View All Comments
eanazag - Wednesday, January 7, 2015 - link
I'm not totally sure why all the NV and Apple back and forth. I see this as an Apple competitive chip for Android tablets. Why would Apple jump the Imag. Tech ship? At release time they have had the best GPU in a SOC for their iPads. ImgTech has been good for Apple iteration over iteration.May Apple be interested in licensing some IP from NV? Maybe. Apple does a lot of custom work and has a desire to remain in the lead on the mobile SOC front at device release.
lucam - Wednesday, January 7, 2015 - link
Old news, after 2 years nobody knows what happened since then.mpeniak - Thursday, January 8, 2015 - link
Totally!!!jwcalla - Monday, January 5, 2015 - link
It seems like Denver was a huge investment that has produced virtually no fruit so far.Time to market seemed to be NVIDIA's problem with Tegra in the past so it does make sense to get Maxwell out the door ASAP.
syxbit - Monday, January 5, 2015 - link
Exactly. Denver has been a massive disappointment. It really needs to be on 20nm. At 28nm performance is too inconsistent, and throttles too much.I just find it funny how arrogant Nvidia is. They're always boasting and boasting with these announcements, and yet by the time they ship, they're rarely leading (or in the case of the K1, they're leading, but in literally only 1 shipping device).
djboxbaba - Monday, January 5, 2015 - link
Yes! How can they keep going about this on a yearly basis, disappointment after disappointment from NVidia in the mobile sector.Krysto - Monday, January 5, 2015 - link
Denver needs to be at 16nm. And we might still see it, at the end of the year/early next year if Nvidia releases the X1 on 20nm, and then X2 (I really hope they don't release another "X1", like they did this year with K1, making things very confusing) with Denver and on 16nm.name99 - Monday, January 5, 2015 - link
Unlikely that nV will release 16FF this year or early next year. Apple has likely booked all 16FF capacity for the next year or so, just like they did with 20nm. nV (and Qualcomm and everyone else) with get 16FF when Apple has satisfied the world's iPhone 6S and iPad 2015 demands...GC2:CS - Monday, January 5, 2015 - link
Yep.Like on the presentation, boasting about how Tegra K1 is still the best mobile chip (despite A8X matching it at significally lower power (which they don't have a graph for)) despite being released a "year before", while A8X has been released just "now". (While taking nVidia's logic A8X was "released" just few hours after K1 because imagination had annonced Series 6XT GPU's at CES 2014).
Yojimbo - Monday, January 5, 2015 - link
Tegra K1 is a 28nm part and the A8X is a 20nm device. The Shield tablet did launch 3 months before the iPad Air 2. Apple has a huge advantage in time to market. They can leverage the latest manufacturing technologies, and they don't have to demonstrate a product and secure design wins. Even though the shield tablet is an NVIDIA design, I doubt they have such tight control of their suppliers as Apple has, and they can't leverage the same high-volume orders. Apple designs a chip and designs a known product around that chip while the chip is being designed, and they can count on it selling in high volume. So you are making an unfair comparison of what NVIDIA is able to do and of the strength of the underlying architecture. If you want to compare the Series 6XT GPU architecture with K1's GPU architecture I think it should be done on the same manufacturing technology.