ARM A53/A57/T760 investigated - Samsung Galaxy Note 4 Exynos Review
by Andrei Frumusanu & Ryan Smith on February 10, 2015 7:30 AM ESTCortex A53 - Architecture
As the owners and creators of the ARM instruction set architecture, ARM (the company) is in an interesting place with regards to both CPU and ISA development. Unlike any other ISA architect, ARM both designs CPUs off of their ISA and licenses that ISA out to other companies as well, creating a marketplace where ARM is both a master and a competitor all at once. From a financial perspective ARM wins either way – architecture licensees pay royalties as well as CPU licensees – but it means that ARM’s CPU designs are by no means a shoe-in, especially at the lucrative high-end of the market.
At the same time the forward-looking nature of ARM’s licensing business means that we get to see their hand well before anyone else’s, as ARM’s licensing model is based around announcing their in-house Cortex CPU designs years in advance to attract customers. Quite often we will know what ARM’s CPU designs are months (or years) before we know what their competition will be. Case in point, for ARMv8 ARM announced their Cortex A53 and Cortex A57 designs over 2 years ago, meaning that although the A53 and A57 product designations are well known, it’s only now that we truly get to see the fruits of ARM’s labor in the consumer market.
At the small end of ARM’s ARMv8 processor lineup is the A53. The successor to the A7, the A53 embodies the same incredibly low power, small die size, and moderate performance goals of the A7 while extending the architecture to 64-bits, as well as working in some further performance improvements. A7 was popular on its own in lower-end Android devices, and for A53 we expect the situation to be much the same. However for the purpose of Exynos, its calling will be as the LITTLE half of its big.LITTLE configuration to drive the SoC during low-performance circumstances.

As with A7, A53 is an in-order design, which in some ways makes it the more interesting of the two ARMv8 designs out of ARM. While A57 gets a comparatively huge die size and power budget to implement high performance features, A53 gets little power, little die size, and ultimately has to get whatever performance it can out of in-order execution. With out-of-order execution being prohibitively expensive in die space and power for A53, this puts ARM in the position of trying to optimize an in-order design as far as they can, explicitly without making the jump to Out-of-Order Execution (OoOE).
Peter Greenhalgh, lead architect of the A53, had a few words to say on the design goals of A53 while taking questions as a guest late last year in a Q&A session here at AnandTech:
Cortex-A53 has the same pipeline length as Cortex-A7 so I would expect to see similar frequencies when implemented on the same process geometry. Within the same pipeline length the design team focused on increasing dual-issue, in-order performance as far as we possibly could. This involved symmetric dual-issue of most of the instruction set, more forwarding paths in the data-paths, reduced issue latency, larger and more associative TLB, vastly increased conditional and indirect branch prediction resources, and expanded instruction and data prefetching. The result of all these changes is an increase in SPECInt-2000 performance from 0.35-SPEC/MHz on Cortex-A7 to 0.50-SPEC/MHz on Cortex-A53. This should provide a noticeable performance uplift on the next generation of smartphones using Cortex-A53.
At its core, the A53 retains the same execution characteristics of the A7. This means we’re looking at a dual-issue in-order CPU with a nice and short 8-stage pipeline. This is coupled with a variable amount of both L1 data cache and L1 instruction cache, ranging from 8KB to 64KB each. L2 cache meanwhile is optional and similarly variable from 128KB to 2MB – Exynos 5433 uses 512KB 256K of the stuff – with there being a single, wide interface between the entire collection of A53 cores and the L2 cache, allowing each core to access the L2 in sequence.
| ARM CPU Core Comparison | ||||||
| Cortex-A7 | Cortex-A53 | |||||
| ARM ISA | ARMv7 (32-bit) | ARMv8 (32/64-bit) | ||||
| Issue Width | 2 micro-ops | 2 micro-ops | ||||
| Pipeline Length | 8 | 8 | ||||
| Integer Add | 2 | 2 | ||||
| Integer Mul | 1 | 1 | ||||
| Load/Store Units | 1 | 1 | ||||
| Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 1x64-bit | 1x64-bit | ||||
| L1 Cache | 8KB-64KB I$ + 8KB-64KB D$ | 8KB-64KB I$ + 8KB-64KB D$ | ||||
| L2 Cache | 128KB - 1MB (Optional) | 128KB - 2MB (Optional) | ||||
For A53, ARM has opted to focus on improving the processor at every stage in order to improve the performance of its dual-issue design. Of these changes, the biggest changes are in the dual-issue capabilities of the processor itself, along with changes to branch prediction.
In the case of dual-issue capabilities, ARM has increased the types of operations that can be issued from the second instruction slot, slot-1. With A7 slot-0 was full-featured while slot-1 could only issue branch and integer data; now for A53, slot-1 can also issue load-stores and FP/NEON operations, bringing it up to parity with slot-0. This means that as far as dual-issue conditions go, A53 should now only be limited by available execution units and whether the next operation can safely be co-issued.
Meanwhile for branch prediction, ARM has worked on beefing up A53’s branch unit to improve the hit rate and otherwise reduce the time wasted on mispredicted branches. Here A53 gains new conditional and indirect predictors, with the conditional predictor being a 6Kbit gshare predictor, while the indirect predictor can hold 256-entries with path history.
Elsewhere, when it comes to power, the A53 has an optional new ability to better switch between power states. The new architecture adds new retention states that are able to power-gate individual blocks of the CPU core, such as for example the NEON unit, and provide lower latency power-gating idle states.
As far as performance goes, ARM tells us that A53 can match A9 in performance at equivalent clock speeds. Given just how fast A9 is and just how small A53 is, to be able to match A9’s performance while undercutting it in die size and power consumption in this manner would be a feather in ARM’s cap, and an impressive follow-up to the A8-like performance of A7.
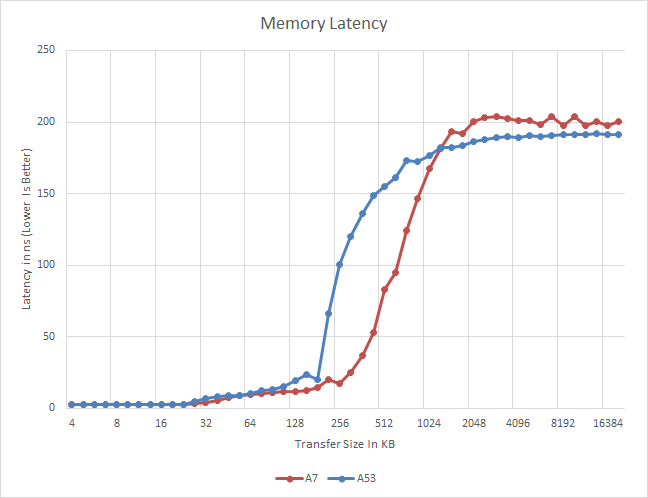
Meanwhile a quick look at some of our synthetic tests finds that the A53 cores in the Exynos 5433 are doing unusually poorly in latency compared the A7 cores, despite the fact that both parts have 512KB 256K of L2 cache. We have other reasons to believe the 5433 has 512KB of L2 cache for the A53 cores,* but looking at this you wouldn't think so, as latency shoots up much earlier, making it seem as if the chip has only 256KB of cache.
* Correction 24/03/2015: Our initial info of 512K L2 cache on the A53 cluster was incorrect and has henceforth been edited to 256K as published by Samsung. (Source)
Given the new information, it looks like the A53 is behaving as it should and the anomaly we saw in the data is actually a proper representation of the real-world scenario.
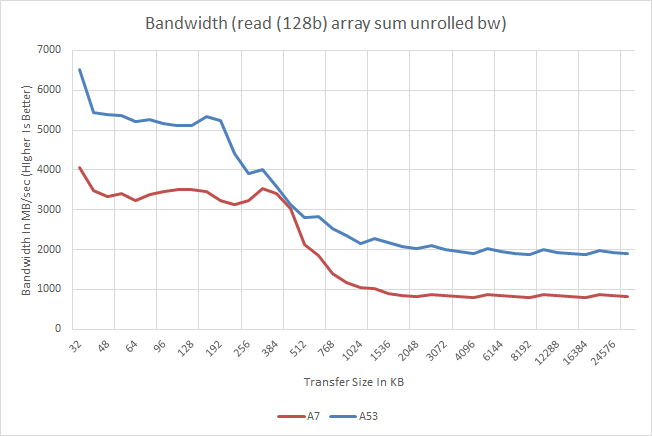
Switching from latency to read bandwidth, we find an interesting outcome for the A53 in the Exynos 5433: memory bandwidth, a lot of it. Truth be told I'm still scratching my head at this one; it's not clear whether this is a result of the dual-issue improvements, something Samsung did for 5433, both, or something else entirely. But the A53 cores in the 5433 have roughly twice as much memory bandwidth as the A7 cores in 5430. This is the case both inside the cache areas and outside to main memory, which points to some greater factor at work here.
Finally, it’s interesting to note at this point that after taking care of the dual-issue bottlenecks on A53, ARM has come very close to pushing a dual-issue in-order design as far as they can go. With most instructions executing in 1 cycle, A53 executes as wide a variety of instructions as quickly as it can, and consequently improving branch prediction is one of the few avenues left for further improving performance. This may partially explain why ARM has already announced the A57’s successor for a couple of years down the line – A72 – but has not announced an A53 successor. Short of going wider or OoOE, I would be curious to see what ARM does after A53.








135 Comments
View All Comments
MrSpadge - Tuesday, February 10, 2015 - link
Excellent work, guys! But let me point out something:1. Your Geekbench numbers show spectacular gains for the A53. They're actually so good that the multi-threading speed-up almost always exceeds the number of cores (judging by eye, have not run the numbers). For A7 the speedup factor is a bit less than 4, right where it should be. It certainly looks like the big cores were kicking in, at least partly.
2. You wonder that power scales sub-linearly with more cores being used. Actually this is just what one would expect in the case of non-ideal multi-thread scaling (as the A7 shows in Geekbench). The load of all ccores may be the same, percentage-wise, but when running many threads these are competing for L2 cache and memory bandwidth. There will be additional wait times under full load (otherwise the memory subsystem is vastly oversized), so each core is busy but working a little less hard.
3. The lower performance per W of the A53: this may well be true. But if the big cores did interfere, it could certainly explain the significantly increased power draw.
4. You hope for A53 at 1.5 - 1.7 GHz. I agree for CPUs which use only A53's. But as little cores this is not necessary. If you push a design to higher frequencies at the same technology node you always pay in terms of power efficiency (unless you start bad / unoptimized). Better let the little cores do what they're best at: be efficient.
... I'm off to the next page :)
MrS
Andrei Frumusanu - Tuesday, February 10, 2015 - link
Regarding your concerns on the big cores turning on: They did not. I made sure that they're always offline in the little testing. As to why GeekBench scaled like that, I can't answer.jjj - Tuesday, February 10, 2015 - link
Geekbanch scales like that sometimes, TR looked at this phone last week and they notice the Shield tab scaling better than 4x in some tests.For the A53 better scaling over A7 maybe it's the memory subsystem? No clue how heavy GB is on it but the A53 does have more memory BW and maybe faster NAND (you don't have storage tests for the Alpha ).
MrSpadge - Tuesday, February 10, 2015 - link
Sometimes one gets such results if the MT code path uses newer libraries to get multi threading, but also introduce other optimizations the tester is not aware of. Or they have to rewrite code/algorithm to make it multi-threaded and thereby create a more efficient version "by accident". I don't know if any of this applies to GB, though.tipoo - Tuesday, February 10, 2015 - link
It's done that before, I think the cache is almost certainly involved. Maybe it has good cache reusability for multicore in its testing.SydneyBlue120d - Tuesday, February 10, 2015 - link
Excellent article, thanks a lot for that.I'd like to dig deeper about why Samsung is ruining the wonderful Wolfson DAC, I remember that even the legendary François Simond shared the issue with Samsung Developers without getting a response, maybe You will be able to have a response :) Also, I remember an audio quality test suite, why didn't You use it in this review? Thanks a lot.
Andrei Frumusanu - Tuesday, February 10, 2015 - link
We realized testing audio without having the proper equipment is a futile exercise and does not really portray audio quality of a device. Only Chris has the professional equipment to objectively test audio, such as done in the iPhone6 review: http://www.anandtech.com/show/8554/the-iphone-6-re...PC Perv - Tuesday, February 10, 2015 - link
Thank you so much for ditching SunSpider, and thank you for explaining why. It has gone way too long.PC Perv - Tuesday, February 10, 2015 - link
I know you are trying to be nice to your colleague and give them a benefit of doubt, but to mercilessly critical eyes of mine your colleagues (Joshua Ho & Brandon Chester) have shown and time and time again they are not qualified to review Android products. I hope Mr. Frumusanu and Mr. Smith will take charge of this area in the future and limit those two to Apple product reviews.I would love to read quality reviews and analysis like this instead of their tamper tantrum.
PC Perv - Tuesday, February 10, 2015 - link
For example, in the comment section here,http://www.anandtech.com/comments/8795/understandi...
[Q]The increase in brightness for AMOLEDs at 80% APL rather than 100% APL is not very significant, and changing testing to accommodate AMOLED's idiosyncrasies doesn't seem like a good idea either. To put it in perspective, even if I had tested the Nexus 6 at 80% APL in the review my conclusion about the brightness being sub-par would have been exactly the same.[/Q]
That is what Brandon Chest had to say about brightness of the Nexus 6's screen. So arrogant, so biased. But according to the scientific data provided by this article (pg. 10), APL can indeed make a huge difference in AMOLED screen's brightness, given power target. For example, at display power target is 1W, 70% APL will raise the brightness by approximately 40%. At 50% APL, max brightness practically doubles.
I was appalled by the disparaging and arrogant attitude by Brandon Chester when it comes to correctly evaluating Android devices. He also made similarly nonsensical "arguments" in his tablet recommendation article for the holidays.