AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Video & Movies: The Video Codec Engine, UVD3, & Steady Video 2.0
When Intel introduced the Sandy Bridge architecture one of their big additions was Quick Sync, their name for their hardware H.264 encoder. By combining a specialized fixed function encoder with some GPU-based processing Intel was able to create a small, highly efficient H.264 encoder that had quality that was as good as or better than AMD and NVIDIA’s GPU based encoders that at the same time was 2x to 4x faster and consumed a fraction of the power. Quick Sync made real-time H.264 encoding practical on even low-power devices, and made GPU encoding redundant at the time. AMD of course isn’t one to sit idle, and they have been hard at work at their own implementation of that technology: the Video Codec Engine (VCE).
The introduction of VCE brings up a very interesting point for discussing the organization of AMD. As both a CPU and a GPU company the line between the two divisions and their technologies often blurs, and Fusion has practically made this mandatory. When AMD wants to implement a feature, is it a GPU feature, a CPU feature, or perhaps it’s both? Intel implemented Quick Sync as a CPU company, but does that mean hardware H.264 encoders are a CPU feature? AMD says no. Hardware H.264 encoders are a GPU feature.
As such VCE is being added to the mix from the GPU side, meaning it shows up first here on the Southern Islands series. Fundamentally VCE is very similar to Quick Sync – it’s based on what you can accomplish with the addition of a fixed function encoder – but AMD takes the concept much further to take full advantage of what the compute side of GCN can do. In “Full Mode” VCE behaves exactly like Quick Sync, in which virtually every step of the H.264 encoding process is handled by fixed function hardware. Just like Quick Sync Full Mode is fast and energy efficient. But it doesn’t make significant use of the rest of the GPU.
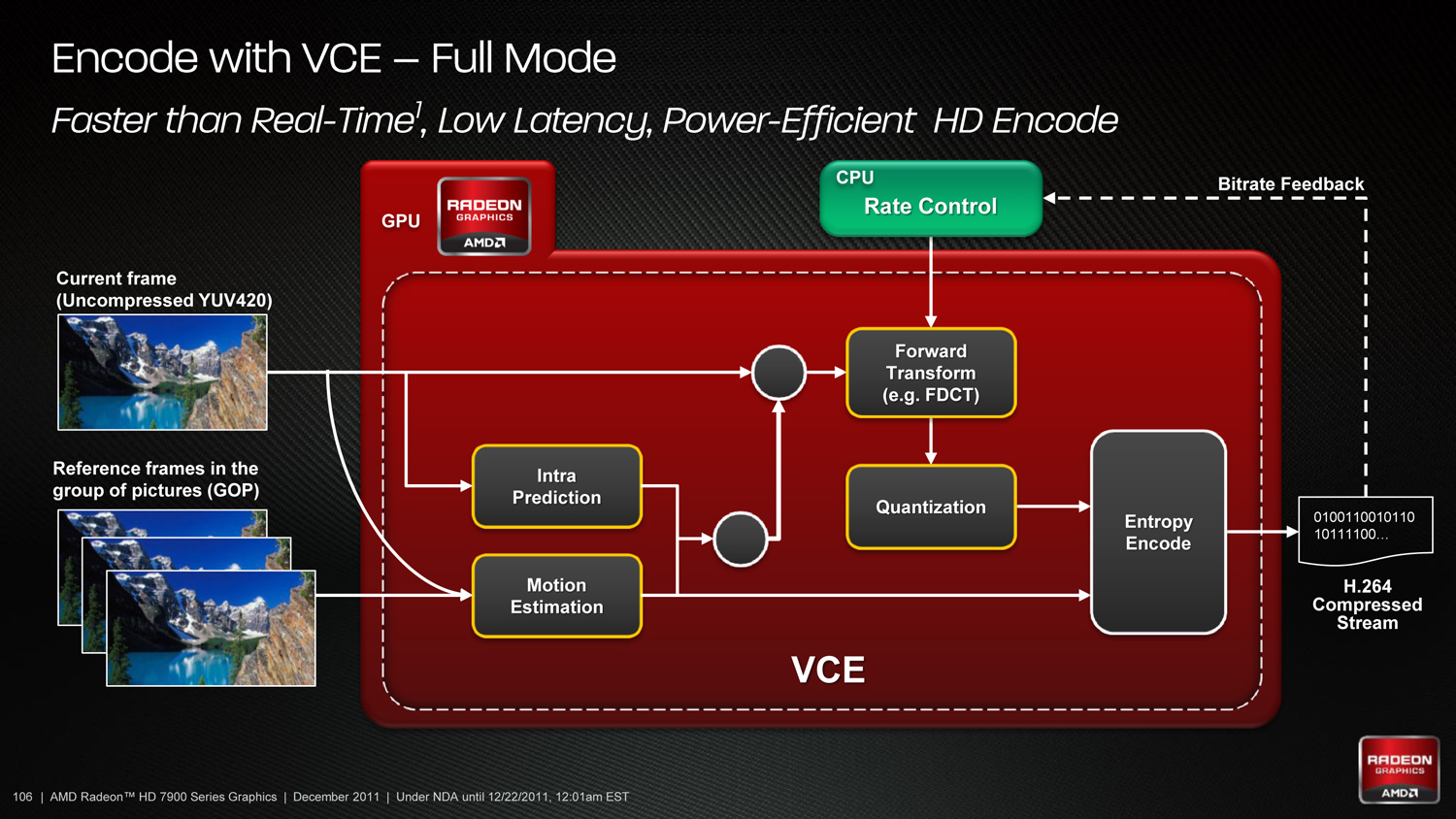
Hybrid Mode is where AMD takes things a step further, by throwing the compute resources of the GPU back into the mix. In Hybrid Mode only Entropy Encode is handled by fixed function hardware (this being a highly serial process that was ill suited to a GPU) with all the other steps being handled by the flexible hardware of the GPU. The end goal of Hybrid Mode is that as these other steps are well suited to being done on a GPU, Hybrid Mode will be much faster than even the highly optimized fixed function hardware of Full Mode. Full Mode is already faster than real time – Hybrid Mode should be faster yet.
With VCE AMD is also targeting Quick Sync’s weaknesses regardless of the mode used. Quick Sync has limited tuning capabilities which impacts the quality of the resulting encode. AMD is going to offer more tuning capabilities to allow for a wider range of compression quality. We don’t expect that it will be up to the quality standards of X264 and other pure-software encoders that can generate archival quality encodes, but if AMD is right it should be closer to archival quality than Quick Sync was.
The catch right now is that VCE is so new that we can’t test it. The hardware is there and we’re told it works, but the software support for it is lacking as none of AMD’s partners have added support for it yet. On the positive side this means we’ll be able to test it in-depth once the software is ready as opposed to quickly testing it in time for this review, however the downside is that we cannot comment on the speed or quality at this time. Though with the 7970 not launching until next year, there’s time for software support to be worked out before the first Southern Islands card ever goes on sale.
Moving on, while encoding has been significantly overhauled decoding will remain largely the same. AMD doesn’t refer to the Universal Video Decoder on Tahiti as UVD3, but the specifications match UVD3 as we’ve seen on Cayman so we believe it to be the same decoder. The quality may have been slightly improved as AMD is telling us they’ve scored 200 on HQV 2.0 – the last time we scored them they were at 197 – but HQV is a partially subjective benchmark.
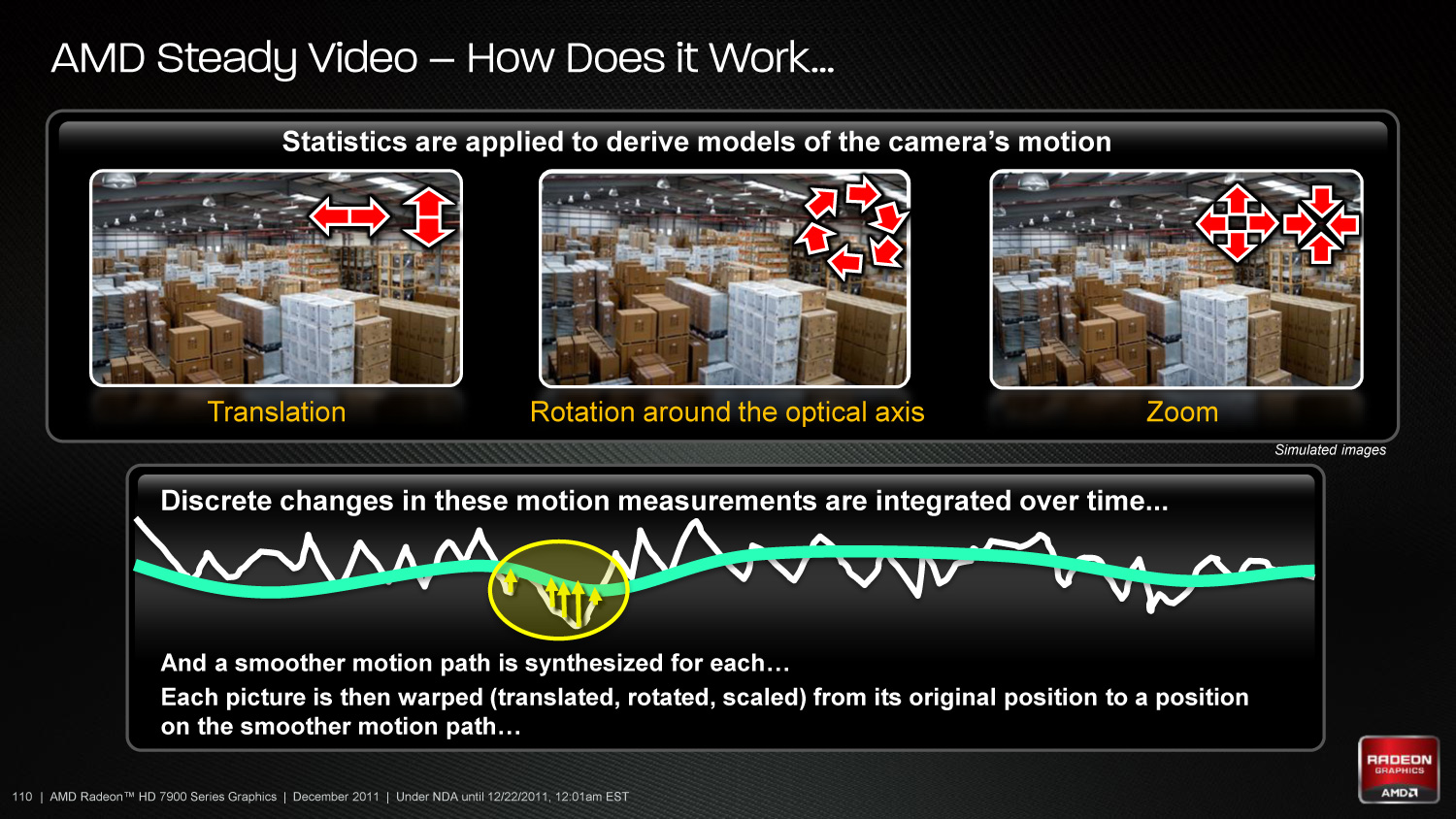
Finally, with Southern Islands AMD is introducing Steady Video 2.0, thesuccessor to Steady Video that was introduced with the Llano APU last year. Steady Video 2.0 adds support for interlaced and letter/pillar boxed content, along with a general increase in the effectiveness of the steadying effect. What makes this particularly interesting is that Steady Video implements a new GCN architecture instruction, Quad Sum of Absolute Differences (QSAD), which combines regular SAD operations with alignment operations into a single instruction. As a result AMD can now execute SADs at a much higher rate so long as they can be organized into QSADs, which is one of the principle reasons that AMD was able to improve Steady Video as it’s a SAD-heavy operation. QSAD extends to more than just Steady Video (AMD noted that it’s also good for other image analysis operations), but Steady Video is going to be the premiere use for it.








292 Comments
View All Comments
SlyNine - Friday, December 23, 2011 - link
Not really, If Nvidia didn't handicap the CPU version of physx so bad than I'd be fine with it, But Nvidia purposely made the CPU version of phsyx worse totally gimped.CeriseCogburn - Thursday, March 8, 2012 - link
I agree, but that's the way it guy. The amd fans don't care what they and their reviewers pull, and frankly the reviewers would recieve death threats if they didn't comply with amd fanboy demands....So when nvidia had ambient occlusion active for several generations back in a driver add, we were suddenly screamed at that shadows in games suck.... because of course amd didn't have that feature...
That's how the whole thing is set up - amd must be the abused underdog, nvidia must be the evil mis-implementer, until of course amd gets and actual win, or even any win even with 10% IQ performance cheat solidly in place, and any other things like failed AA, poor tessellation performance, no PhysX, etc, etc, etc...
We just must hate nvidia for being better and of course it's all nvidia's fault as they are keeping the poor red radeon down....
If amd radeon has " a perfectly circular algorithm " and it does absolutely nothing and even worse in all games, it is to be praised as an advantage anyway.... and that is still happening to this very day... we ignore shimmer until now, when amd 79xx has a fix for it.... etc..
Dude, that's the way it is man....
Nvidia is the evil, and they're keeping the radeon down...
They throw around money too ( that's unfair as well - and evil ...)
See?
So just pretend anything radeon cannot do that nvidia can doesn't count and is bad, and then make certain nvidia is cut down to radeon level, IQ cheat, no PhysX, AA not turned on, Tesselation turned down, default driver hacks left in place for amd, etc....
Then be sure to cheer when some price perf calc ignoring all the above shows a higher and or lower and card to have a few cents advantage... no free game included, no eyefinity cables... etc.
Just dude... amd = good / nvidia=evil ...
Cool ?
shin0bi272 - Thursday, December 22, 2011 - link
Since I cant edit my comments I have to post this in a second comment instead.According to the released info, Nvidia’s Next Gen flagship GK-100/GK-112 chip which will feature a total f 1024 Shaders (Cuda Cores), 128 texture units (TMUs), 64 ROP’s and a 512-bit GDDR5 Memory interface. The 28nm Next Gen beast would outperform the current Dual chip Geforce GTX590 GPU.
shaboinkin - Thursday, December 22, 2011 - link
Can someone tell me why GPUs tend to have much more transistors than a CPU? I never knew why.Boushh - Thursday, December 22, 2011 - link
Basically it has to do with the difference between programs (= CPU instructions) and graphics (= pixels):A program consists of CPU intructions, many of these instructions depend on output from the previous instruction, Therefore adding more pipelines that can work on the instructions doen't realy work.
A picture consists of pixels, these can be processed in parrallel. So if you double the number of pipelines (= pixels you can work on at the same time), you double the performance.
Therefore CPU's don't have that many transistors. In fact, most transistors in a CPU are in the cache memory not in the actual CPU cores. And GPU's do.
Of course this is hust a simple explenation, the through is much much more complex ;-)
Boushh - Thursday, December 22, 2011 - link
That last line should read:'Of course this is just a simple explanation, the reality is much much more complex'
Reminds me to yet again vote for an EDIT button !!!! Maybe as a christmas present ? PLEASE !!!
shaboinkin - Thursday, December 22, 2011 - link
Interesting...Do you know of a site that goes into the finer details?
Mishera - Wednesday, December 28, 2011 - link
If you're looking for something to specifically answer you question the checking different tech sites. I think realworldtech addressed tis to a degree. Jon Stokes at arstechnica from what I heard wrote some pretty good articles on chip design as well. But if it's a question on chip architecture, reading some textbooks is your best bet. I asked a similar question in the forums before and got some great responses just check my posts.I add to what Boushh said in that for the type of information they process, it's beneficial to have more performance (and not just for graphics). That's why Amd has been pushing to integrate the gpu into the CPU. That's also to a degree show the different philosophy right now between intel and Amd in multicore computing (or the difference between Amd's new gpu architecture vs their previous one).
What it comes down to is optimizing chip design to make use of programs, vice versa. There really is now absolute when dealing with this.
MrSpadge - Thursday, December 22, 2011 - link
It's not like - as stated several times in the article - AMD is wrong about the power target of the HD7970, if they mean the PowerTune limit. Think of it as "the card is built to handle this much heat, and is guaranteed not to exceed it". That doesn't forbid drawing less power. And that's exactly what the HD6970 does: it's got the same "power target", but it uses less of its power budget than the HD7970.Like CPUs, whose real world power consumption is often much less than the TDP.
MrS
Ryan Smith - Thursday, December 22, 2011 - link
PowerTune is a hard cap on power consumption. Given a sufficient workload (i.e. FurMark or OCCT), you can make the card try to consume more power than it is allowed, at which point PowerTune kicks in. Or to put this another way, PowerTune doesn't kick in unless the card is at its limit.PowerTune kicked in for both the 6970 and 7970. In which case both cards should have be limited to 250W.