The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTFavored Core
For Broadwell-E, the last generation of Intel’s HEDT platform, we were introduced to the term ‘Favored Core’, which was given the title of Turbo Boost Max 3.0. The idea here is that each piece of silicon that comes off of the production line is different (which is then binned to match to a SKU), but within a piece of silicon the cores themselves will have different frequency and voltage characteristics. The one core that is determined to be the best is called the ‘Favored Core’, and when Intel’s Windows 10 driver and software were in place, single threaded workloads were moved to this favored core to run faster.
In theory, it was good – a step above the generic Turbo Boost 2.0 and offered an extra 100-200 MHz for single threaded applications. In practice, it was flawed: motherboard manufacturers didn’t support it, or they had it disabled in the BIOS by default. Users had to install the drivers and software as well – without the combination of all of these at work, the favored core feature didn’t work at all.

Intel is changing the feature for Skylake-X, with an upgrade and for ease-of-use. The driver and software are now part of Windows updates, so users will get them automatically (if you don’t want it, you have to disable it manually). With Skylake-X, instead of one core being the favored core, there are two cores in this family. As a result, two apps can be run at the higher frequency, or one app that needs two cores can participate.
Speed Shift
In Skylake-S, the processor has been designed in a way that with the right commands, the OS can hand control of the frequency and voltage back to the processor. Intel called this technology 'Speed Shift'. We’ve discussed Speed Shift before in the Skylake architecture analysis, and it now comes to Skylake-X. One of the requirements for Speed Shift is that it requires operating system support to be able to hand over control of the processor performance to the CPU, and Intel has had to work with Microsoft in order to get this functionality enabled in Windows 10.
Compared to Speed Step / P-state transitions, Intel's new Speed Shift terminology changes the game by having the operating system relinquish some or all control of the P-States, and handing that control off to the processor. This has a couple of noticeable benefits. First, it is much faster for the processor to control the ramp up and down in frequency, compared to OS control. Second, the processor has much finer control over its states, allowing it to choose the most optimum performance level for a given task, and therefore using less energy as a result. Specific jumps in frequency are reduced to around 1ms with Speed Shift's CPU control from 20-30 ms on OS control, and going from an efficient power state to maximum performance can be done in around 35 ms, compared to around 100 ms with the legacy implementation. As seen in the images below, neither technology can jump from low to high instantly, because to maintain data coherency through frequency/voltage changes there is an element of gradient as data is realigned.

The ability to quickly ramp up performance is done to increase overall responsiveness of the system, rather than linger at lower frequencies waiting for OS to pass commands through a translation layer. Speed Shift cannot increase absolute maximum performance, but on short workloads that require a brief burst of performance, it can make a big difference in how quickly that task gets done. Ultimately, much of what we do falls more into this category, such as web browsing or office work. As an example, web browsing is all about getting the page loaded quickly, and then getting the processor back down to idle.
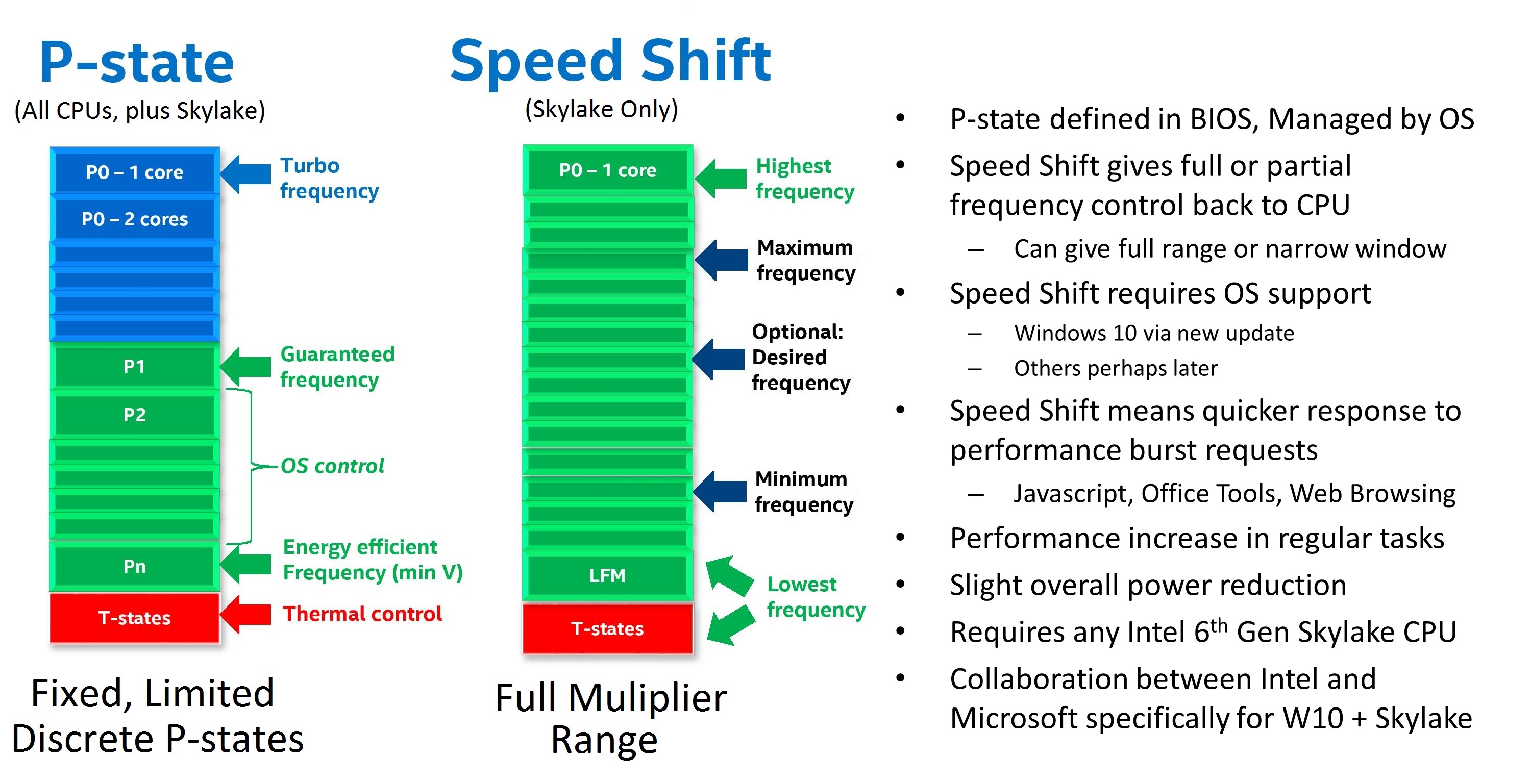
Again, Speed Shift is something that needs to be enabled on all levels - CPU, OS, driver, and motherboard BIOS. It has come to light that some motherboard manufacturers are disabling Speed Shift on desktops by default, negating the feature. In the BIOS is it labeled either as Speed Shift or Hardware P-States, and sometimes even has non-descript options. Unfortunately, a combination of this and other issues has led to a small problem on X299 motherboards.
X299 Motherboards
When we started testing for this review, the main instructions we were given was that when changing between Skylake-X and Kaby Lake-X processors, be sure to remove AC power and hold the reset BIOS button for 30 seconds. This comes down to an issue with supporting both sets of CPUs at once: Skylake-X features some form of integrated voltage regulator (somewhat like the FIVR on Broadwell), whereas Kaby Lake-X is more motherboard controlled. As a result, some of the voltages going in to the CPU, if configured incorrectly, can cause damage. This is where I say I broke a CPU: our Kaby Lake-X Core i7 died on the test bed. We are told that in the future there should be a way to switch between the two without having this issue, but there are some other issues as well.
After speaking with a number of journalists in my close circle, it was clear that some of the GPU testing was not reflective of where the processors sat in the product stack. Some results were 25-50% worse than we expected for Skylake-X (Kaby Lake-X seemingly unaffected), scoring disastrously low frame rates. This was worrying.
Speaking with the motherboard manufacturers, it's coming down to a few issues: managing the mesh frequency (and if the mesh frequency has a turbo), controlling turbo modes, and controlling features like Speed Shift. 'Controlling' in this case can mean boosting voltages to support it better, overriding the default behavior for 'performance' which works on some tests but not others, or disabling the feature completely.
We were still getting new BIOSes two days before launch, right when I need to fly half-way across the world to cover other events. Even retesting the latest BIOS we had for the boards we had, there still seems to be an underlying issue with either the games or the power management involved. This isn't necessarily a code optimization issue for the games themselves: the base microarchitecture on the CPU is still the same with a slight cache adjustment, so if a Skylake-X starts performing below an old Sandy Bridge Core i3, it's not on the game.
We're still waiting to hear for BIOS updates, or reasons why this is the case. Some games are affected a lot, others not at all. Any game we are testing which ends up being GPU limited is unaffected, showing that this is a CPU issue.








264 Comments
View All Comments
mat9v - Tuesday, June 20, 2017 - link
To play it safe, invest in the Core i9-7900X today.To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.
Then the conclusion should have been - wait for fixed platform. I'm not even suggesting choosing Ryzen as it performs slower but encouraging buying flawed (for now) platform?
mat9v - Tuesday, June 20, 2017 - link
Please then correct tables on 1st page comparing Ryzen and 7820X and 7800X to state that Intel has 24 lines as they leave 24 for PCIEx slots and 4 is reserved for DMI 3.0If you strip Ryzen lines to only show those available for PCIEx do so for Intel too.
Ryan Smith - Wednesday, June 21, 2017 - link
The tables are correct. The i7 7800 series have 28 PCIe lanes from the CPU for general use, and another 4 DMI lanes for the chipset.PeterCordes - Tuesday, June 20, 2017 - link
Nice article, thanks for the details on the microarchitectural changes, especially to execution units and cache. This explains memory bandwidth vs. working-set size results I observed a couple months ago on Google Compute Engine's Skylake-Xeon VMs with ~55MB of L3: The L2-L3 transition was well beyond 256kB. I had assumed Intel wouldn't use a different L3 cache design for SKX vs. SKL, but large L2 doesn't make much sense with an inclusive L3 of 2 or 2.5MB per core.Anyway, some corrections for page3: The allocation queue (IDQ) is in Skylake-S is always 64 uops, with or without HT. For example, I looked at the `lsd.uops` performance counter in a loop with 97 uops on my i7-6700k. For 97 billion counts of uops_issued.any, I got exactly 0 counts of lsd.uops, with the system otherwise idle. (And I looked at cpu_clk_unhalted.one_thread_active to make sure it was really operating in non-HT mode the majority of the time it was executing.) Also, IIRC, Intel's optimization manual explicitly states that the IDQ is always 64 entries in Skylake.
The scheduler (aka RS or Reservation Station) is 97 unfused-domain uops in Skylake, up from 60 in Haswell. The 180int / 168fp numbers you give are the int / fp register-file sizes. They are sized more like the ROB (224 fused-domain uops, up from 192 in Haswell), not the scheduler, since like the ROB, they have to hold onto values until retirement, not just until execution. See also http://blog.stuffedcow.net/2013/05/measuring-rob-c... for when the PRF size vs. the ROB is the limit on the out-of-order window. See also http://www.realworldtech.com/haswell-cpu/6/ for a nice block diagram of the whole pipeline.
SKL-S DIVPS *latency* is 11 cycles, not 3. The *throughput* is one per 3 cycles for 128-bit vectors, or one per 5 cycles for 256b vectors, according to Agner Fog's table. I forget if I've tested that myself. So are you saying that SKL-SP has one per 5 cycle throughput for 128-bit vectors? What's the throughput for 256b and 512b vectors?
-----
It's really confusing the way you keep saying "AVX unit" or "AVX-512 unit" when I think you mean "512b FMA unit". It sounds like vector-integer, shuffle, and pretty much everything other than FMA will have true 512b execution units. If that's correct, then video codecs like x264/x265 should run the same on LCC vs. HCC silicon (other than differences in mesh interconnect latency), because they're integer-only, not using any vector-FP multiply/add/FMA.
-------
> This should allow programmers to separate control flow from data flow...
SIMD conditional operations without AVX512 are already done branchlessly (I think that's what you mean by separate from control-flow) by masking the input and/or output. e.g. to conditionally add some elements of a vector, AND the input with a vector of all-one or all-zero elements (as produced by CMPPS or PGMPEQD, for example). Adding all-zeros is a no-op (the additive identity).
Mask registers and support for doing it as part of another operation makes it much more efficient, potentially making it a win to vectorize things that otherwise wouldn't be. But it's not a new capability; you can do the same thing with boolean vectors and SSE/AVX VPBLENDVPS.
PeterCordes - Tuesday, June 20, 2017 - link
Speed Shift / Hardware P-State is not Windows-specific, but this article kind of reads as if it is.Your article doesn't mention any other OSes, so nothing it says is actually wrong: I'm sure it did require Intel's collaboration with MS to get support into Win10. The bullet-point in the image that says "Collaboration between Intel and Microsoft specifically for W10 + Skylake" may be going too far, though. That definitely implies that it only works on Win10, which is incorrect.
Linux has supported it for a while. "HWP enabled" in your kernel log means the kernel has handed off P-state selection to the hardware. (Since Linux is open-source, Intel contributed most of the code for this through the regular channels, like they do for lots of other drivers.)
dmesg | grep intel_pstate
[ 1.040265] intel_pstate: Intel P-state driver initializing
[ 1.040924] intel_pstate: HWP enabled
The hardware exposes a knob that controls the tradeoff between power and performance, called Energy Performance Preference or EPP. Len Brown@Intel's Linux patch notes give a pretty good description of it (and how it's different from a similar knob for controlling turbo usage in previous uarches), as well as describing how to use it from Linux. https://patchwork.kernel.org/patch/9723427/.
# CPU features related to HWP, on an i7-6700k running Linux 4.11 on bare metal
fgrep -m1 flags /proc/cpuinfo | grep -o 'hwp[_a-z]*'
hwp
hwp_notify
hwp_act_window
hwp_epp
I find the simplest way to see what speed your cores are running is to just `grep MHz /proc/cpuinfo`. (It does accurately reflect the current situation; Linux finds out what the hardware is actually doing).
IDK about OS X support, but I assume Apple has got it sorted out by now, almost 2 years after SKL launch.
Arbie - Wednesday, June 21, 2017 - link
There are folks for whom every last compute cycle really matters to their job. They have to buy the technical best. If that's Intel, so be it.For those dealing more with 'want' than 'need', a lot of this debate misses an important fact. The only reason Intel is suddenly vomiting cores, defecating feature sizes, and pre-announcing more lakes than Wisonsin is... AMD. Despite its chronic financial weakness that company has, incredibly, come from waaaay behind and given us real competition again. In this ultra-high stakes investment game, can they do that twice? Maybe not. And Intel has shown us what to expect if they have no competitor. In this limited-supplier market it's not just about who has the hottest product - it's also about whom we should reward with our money, and about keeping vital players in the game.
I suggest - if you can, buy AMD. They have earned our support and it's in our best interests to do so. I've always gone with Intel but have lately come to see this bigger picture. It motivated me to buy an 1800X and I will also buy Vega.
Rabnor - Wednesday, June 21, 2017 - link
To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.You have to spend that $400+ on a good motherboard & aio cooler.
Are you sold by Intel, anandtech?
Synviks - Thursday, June 22, 2017 - link
For some extra comparison: running Cinebench R15 on my 14c 2.7ghz Haswell Xeon, with turbo to 3ghz on all cores, my score is 2010.Pretty impressive performance gain if they can shave off 4 cores and end up with higher performance.
Pri - Thursday, June 22, 2017 - link
On the first page you wrote this:Similarly, the 6-core Core i7-7820X at $599 goes up against the 8-core $499 Ryzen 7 1800X.
The Core i7 7820X was mistakenly written as a 6-core processor when it is in-fact an 8-core processor.
Kind Regards.
Gigabytes - Thursday, June 22, 2017 - link
Okay, here is what I learned from this article. Gaming performance sucks and you will be able to cook a pizza inside your case. Did I miss anything?Oh, one thing missing.
Play it SMART and wait to see the Ripper in action before buy your new Intel toaster oven.