NVIDIA Publishes Statement on GeForce GTX 970 Memory Allocation
by Ryan Smith on January 24, 2015 8:00 PM EST
On our forums and elsewhere over the past couple of weeks there has been quite a bit of chatter on the subject of VRAM allocation on the GeForce GTX 970. To quickly summarize a more complex issue, various GTX 970 owners had observed that the GTX 970 was prone to topping out its reported VRAM allocation at 3.5GB rather than 4GB, and that meanwhile the GTX 980 was reaching 4GB allocated in similar circumstances. This unusual outcome was at odds with what we know about the cards and the underlying GM204 GPU, as NVIDIA’s specifications state that the GTX 980 and GTX 970 have identical memory configurations: 4GB of 7GHz GDDR5 on a 256-bit bus, split amongst 4 ROP/memory controller partitions. In other words, there was no known reason that the GTX 970 and GTX 980 should be behaving differently when it comes to memory allocation.
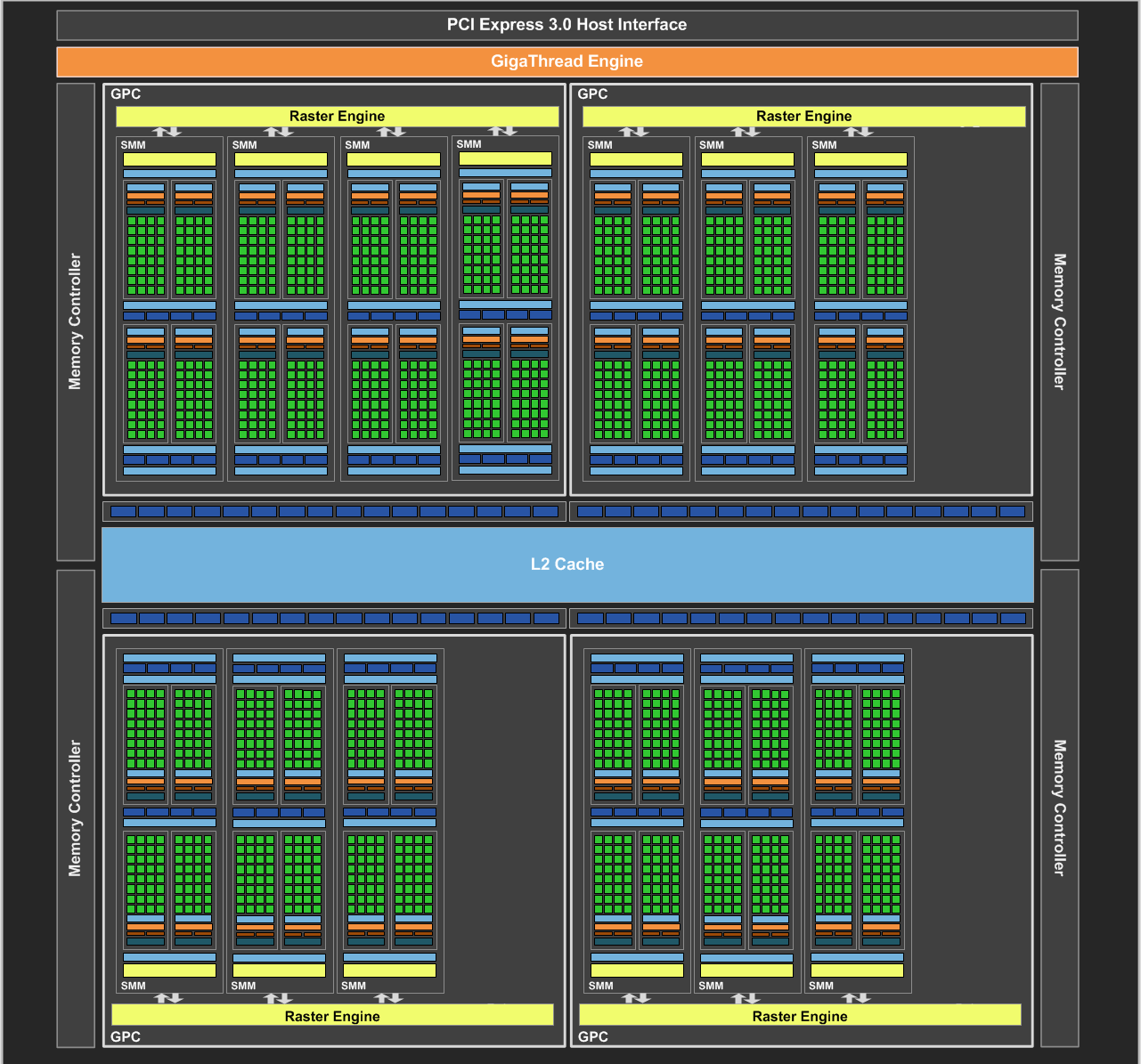
GTX 970 Logical Diagram
GTX 970 Memory Allocation (Image Courtesy error-id10t of Overclock.net Forums)
Since then there has been some further investigation into the matter using various tools written in CUDA in order to try to systematically confirm this phenomena and to pinpoint what is going on. Those tests seemingly confirm the issue – the GTX 970 has something unusual going on after 3.5GB VRAM allocation – but they have not come any closer in explaining just what is going on.
Finally, more or less the entire technical press has been pushing NVIDIA on the issue, and this morning they have released a statement on the matter, which we are republishing in full:
The GeForce GTX 970 is equipped with 4GB of dedicated graphics memory. However the 970 has a different configuration of SMs than the 980, and fewer crossbar resources to the memory system. To optimally manage memory traffic in this configuration, we segment graphics memory into a 3.5GB section and a 0.5GB section. The GPU has higher priority access to the 3.5GB section. When a game needs less than 3.5GB of video memory per draw command then it will only access the first partition, and 3rd party applications that measure memory usage will report 3.5GB of memory in use on GTX 970, but may report more for GTX 980 if there is more memory used by other commands. When a game requires more than 3.5GB of memory then we use both segments.
We understand there have been some questions about how the GTX 970 will perform when it accesses the 0.5GB memory segment. The best way to test that is to look at game performance. Compare a GTX 980 to a 970 on a game that uses less than 3.5GB. Then turn up the settings so the game needs more than 3.5GB and compare 980 and 970 performance again.
Here’s an example of some performance data:
GeForce GTX 970 Performance Settings GTX980 GTX970 Shadows of Mordor
<3.5GB setting = 2688x1512 Very High
72fps
60fps
>3.5GB setting = 3456x1944
55fps (-24%)
45fps (-25%)
Battlefield 4
<3.5GB setting = 3840x2160 2xMSAA
36fps
30fps
>3.5GB setting = 3840x2160 135% res
19fps (-47%)
15fps (-50%)
Call of Duty: Advanced Warfare
<3.5GB setting = 3840x2160 FSMAA T2x, Supersampling off
82fps
71fps
>3.5GB setting = 3840x2160 FSMAA T2x, Supersampling on
48fps (-41%)
40fps (-44%)
On GTX 980, Shadows of Mordor drops about 24% on GTX 980 and 25% on GTX 970, a 1% difference. On Battlefield 4, the drop is 47% on GTX 980 and 50% on GTX 970, a 3% difference. On CoD: AW, the drop is 41% on GTX 980 and 44% on GTX 970, a 3% difference. As you can see, there is very little change in the performance of the GTX 970 relative to GTX 980 on these games when it is using the 0.5GB segment.
Before going any further, it’s probably best to explain the nature of the message itself before discussing the content. As is almost always the case when issuing blanket technical statements to the wider press, NVIDIA has opted for a simpler, high level message that’s light on technical details in order to make the content of the message accessible to more users. For NVIDIA and their customer base this makes all the sense in the world (and we don’t resent them for it), but it goes without saying that “fewer crossbar resources to the memory system” does not come close to fully explaining the issue at hand, why it’s happening, and how in detail NVIDIA is handling VRAM allocation. Meanwhile for technical users and technical press such as ourselves we would like more information, and while we can’t speak for NVIDIA, rarely is NVIDIA’s first statement their last statement in these matters, so we do not believe this is the last we will hear on the subject.
In any case, NVIDIA’s statement affirms that the GTX 970 does materially differ from the GTX 980. Despite the outward appearance of identical memory subsystems, there is an important difference here that makes a 512MB partition of VRAM less performant or otherwise decoupled from the other 3.5GB.
Being a high level statement, NVIDIA’s focus is on the performance ramifications – mainly, that there generally aren’t any – and while we’re not prepared to affirm or deny NVIDIA’s claims, it’s clear that this only scratches the surface. VRAM allocation is a multi-variable process; drivers, applications, APIs, and OSes all play a part here, and just because VRAM is allocated doesn’t necessarily mean it’s in use, or that it’s being used in a performance-critical situation. Using VRAM for an application-level resource cache and actively loading 4GB of resources per frame are two very different scenarios, for example, and would certainly be impacted differently by NVIDIA’s split memory partitions.
For the moment with so few answers in hand we’re not going to spend too much time trying to guess what it is NVIDIA has done, but from NVIDIA’s statement it’s clear that there’s some additional investigating left to do. If nothing else, what we’ve learned today is that we know less than we thought we did, and that’s never a satisfying answer. To that end we’ll keep digging, and once we have the answers we need we’ll be back with a deeper answer on how the GTX 970’s memory subsystem works and how it influences the performance of the card.








93 Comments
View All Comments
zmeul - Saturday, January 24, 2015 - link
I'm no expert, but this sounds really bad for nVidia because it looks like the issue was known and knowingly hidden from the customersMonkeyPaw - Saturday, January 24, 2015 - link
It's not that bad, and people won't hold any long term grudge. Intel has launched several CPUs and chipsets over the years that have actually failed to perform a certain advertised feature, but that feature was usually secondary and the product was still very good. It's all about what you get in real world performance for the money you spend. Who cares how the 970 uses its RAM if the performance is what you expected.Non nVidia user.
zmeul - Saturday, January 24, 2015 - link
non nVidia user either, and I have been a Radeon user for the last 14 years until I got to 7870Ghz ED - dead; replaced with 280X - unstable out of the box; replaced with 2nd 280X - extremely unstable and currently in RMAthey way I see it, sadly this industry has gone to s**t; they need to pause for as long as they need, fix whatever they need to fix and resume delivery of solid products
insurrect2010 - Saturday, January 24, 2015 - link
In agreement with you.This is shocking on nvidia's part. Remember nvidia and 'bumpgate' ? Where they were responsible for thousands and thousands of defective gpu parts in laptops. That took a lawsuit and years and years to get them to take responsibility. Finally last year they had to settle and pay out damages for their defective hardware.
Nice to hear anandtech will be doing research on this. Believing anything nvidia says abou the matter is foolishness personified without 3rd party testing and verification. If the issue is as substantial for performance as we've been seeing in tests not from nvidia then they have every reason to try and hide and cloud the issue to avoid the cost of fixing it for end-users.
It's early yet and more investigations are needed on the flawed hardware in all GTX 970 cards.
Scratchpop - Saturday, January 24, 2015 - link
Hear hear! lost a laptop to a dead nvidia gpu in that fiqsco. all following the forum investigations on AT and OCN have seen the shocking performance loss when the VRAM flaw of the 970 manifests. we're sure to learn more as further tests occur and the full extent of nvidias mistake in 970 design is demonstrated. hopes are for gtx 970 users not needing to pursue a recall on these faulty cards.Samus - Sunday, January 25, 2015 - link
What's sad is HP, the largest OEM to use NVidia components, took the brunt of the customer fallout in those bad laptops. Sure, the cooling systems weren't great but they met NVidia's TDP requirements, which were flawed, and it's still unclear if TSMC even made the chips to QA. Most customers don't even know or care who NVidia is, they just know their HP laptop broke, millions of them, and HP lost customers.NeatOman - Sunday, January 25, 2015 - link
I used to repair them all the time (reflow) and it was a mic between the chip set that also carried the GPU not being able to report overheating so the fan would not ramp up, only when the CPU became warm (the fan would turn off if the CPU was at idle which caused it for the most part) and they used a rubber faom thermal pad to disapate heat from the chipset because of the amount of flex that the system displayed.The Intel boards didn't have this problem because the chipset had a much weaker GPU inside of it making it possible for disapate all the heat through the motherboard its self.
Nvidia and HP both messed up.
NeatOman - Sunday, January 25, 2015 - link
Sorry, I used text to speach on my phone lol. I meant to say *it was that the fan didn't respind to the chipset heating up that also carried the GPUAlexvrb - Sunday, January 25, 2015 - link
HP didn't really mess up, and the Nvidia chipsets in question didn't experience conditions more adverse than their models competing ATI and Intel components. They kept everything within Nvidia-specified conditions and they still failed left and right. If Nvidia had demanded they be kept cooler, or spec'd them for lower clocks (and thus reducing both current draw and heat) then it wouldn't have been such an unmitigated disaster.Furthermore it was ONLY a matter of heat and power draw. Heat accelerated the problem greatly, but even discrete GPUs with the same bump/pad and underfill materials were not immune to the problem. There's a reason it's called bumpgate and not fangate or thermalgate. Ramping up the fans sooner/faster/etc and otherwise boosting cooling is a band-aid and does not address the underlying problem. If you knew about the issue you could apply a BIOS update for many models that ramps up the fan more often (and sooner) but that mostly just delayed the inevitable. I lost a laptop to it, myself.
Just search "nvidia bumpgate" and you'll see what I'm talking about. High-lead bumps connected to eutectic pads? Wrong underfill materials? Uneven power draw causing some bumps to carry too much current? Yes, yes, and yes. They later started repackaging chips with different materials used for bumps and underfill, and manufacturers were more aggressive with cooling, and failures were vastly reduced.
Alexvrb - Sunday, January 25, 2015 - link
Ack, meant to say "Furthermore it wasn't ONLY a matter of head and power draw". That whole paragraph doesn't make sense if it was only heat and power. Sorry.