Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC

Last week, Soft Machines announced that their 'VISC' architecture was available for licensing, following the announcement of the original concepts over a year ago. VISC, in a nutshell, is designed as a solution to improving the number of instructions per clock a single thread can process in a given time, which potentially makes it a very interesting design in an era where IPC gains are harder and harder to realize.
The concepts behind their new ‘VISC’ architecture, which splits the workload of a single linear thread across multiple cores, are intriguing and exciting. But as with any new fundamental change in computer processing, subject to a large barrage of questions. We were invited to a presentation and call with the President and Chief Technical Officer Mohammed Abdallah and the VP Marketing and Business Mark Casey, and I put a number of questions on the lips of analysts to them.
Identifying Single Thread Performance Bottlenecks
Any discussion about processor performance over the last couple of decades has involved several factors, including getting better performance through an increased power budget, a higher frequency, extracting instruction level parallelism (ILP), getting better at minimizing delays through better branch prediction, or adding more cores and improving thread level parallelism (TLP). Each of these methods have varying degrees of success at increasing performance – long-time readers will remember the Pentium 4 days of hitting a frequency and power wall which then switched the focus to efficiency. Some tasks, like graphics, are inherently parallel and can take advantage of multiple hundreds or thousands of cores, or the software can be optimized. However, the nature of most software code and instructions is that they are single threaded by nature, and their performance relies on how fast the instructions can be processed within a single thread.
The main way of increasing performance, or in this case the instructions per unit frequency (instructions per clock, or IPC), is to expand the CPU architecture to allow more commands to be processed at once. Moving from a 3-wide out-of-order architecture to a 5-wide out-of-order architecture theoretically allows for a 66% increase in instruction throughput if (and only if) the code is sufficiently dense enough to extract those operations, and the other features in the architecture can ensure all the operations are fed every clock cycle.
The problem with moving to a wider architecture is typically power and design complexity. As shown by various chip designs over the years, the wider the architecture the more silicon has to be set aside for assets like buffers, re-order windows and caching. If there is a silicon budget and enough power headroom, we see designs like the six-wide Intel Skylake cores or the seven wide NVIDIA Denver cores able to extract peak performance when code is written that matches the hardware. However the potential downside of a wide architecture is that it remains inefficient for sets of instructions that only need a 2-wide or a 3-wide architecture. Alternatively, if multiple programs or threads want to use the hardware, then a single core is inaccessible to additional threads while the first thread is still in use (though this can be avoided somewhat by simultaneous multithreading or SMT which will let another thread have access when the first has encountered a stall such as waiting for L1/L2 memory).
As a result, modern designs also include a number of cores to handle the multile thread/multiple program scenario. Generally speaking this works well, especially with high-performance cores, but it becomes a bit of an issue itself when much of the world’s hardware is actually composed of many cores that have poor single threaded performance. Older Core 2 / Conroe systems, basic Bulldozer, or ARM Cortex-A7 designs are (still) widely used and often ship with multiple cores to allow for multiple programs at once. And while they can scale up with additional threads to the number of cores they offer, if any single or lightly-threaded software needs more performance, those extra cores are not used or are only minimally beneficial overall.
This brings us to Soft Machines, whose VISC architecture aims to change this.
Meet VISC
I should start by saying that despite the similarities to other architectural names, VISC is not an acronym. I asked directly and it is merely a noun for the purposes of trademarking. People can interpret it as a ‘virtual instruction set computing’ or something similar, but the company doesn’t apply any acronym to the letters.
But a virtual instruction set is a good description here. For the most part, processor architectures were traditionally built around either CISC (complex) or RISC (reduced) instruction sets and execution models, while more modern designs (e.g. Intel Core) are increasingly a mix, or so-called ‘CRISC’ design. The difference between CISC and RISC boils down to the fact that simpler designs can be more power efficient, but complex designs can do more complicated things in fewer cycles, all the while CRISC essentially meets the two paradigms in the middle in an attempt to gain the benefits of both, though not without inheriting some of the drawbacks as well. VISC, for lack of a better description, is a RISC design using a custom instruction set over a translation layer which allows a single thread of operations to be dispatched over multiple physical cores. The base diagram looks something like this:
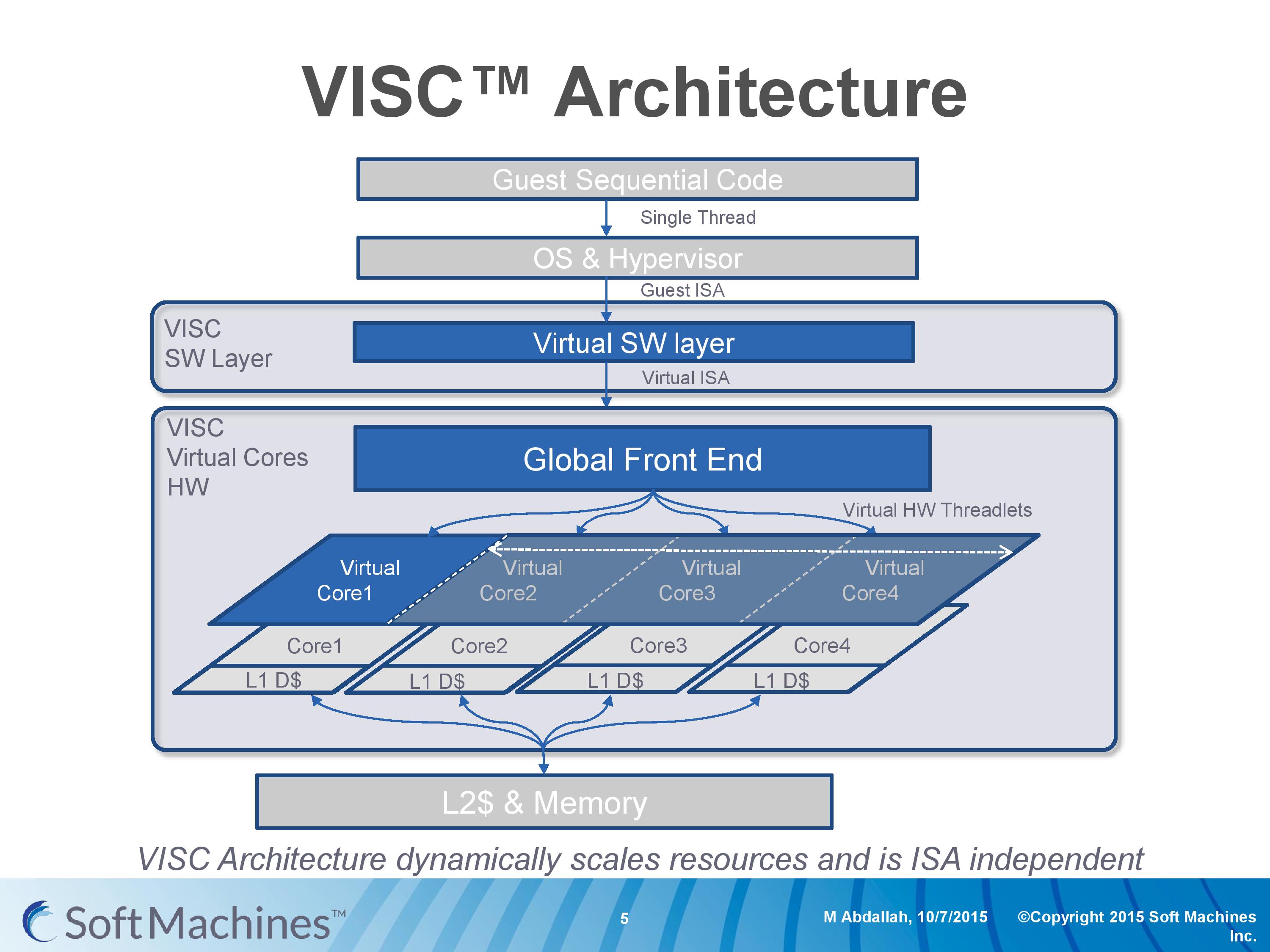
Here is an example of a VISC design with four physical cores. The design can handle four ‘virtual cores’ or threads as well, but what makes the VISC design different is that when the virtual core has a thread of instructions, it can use the resources of any physical core. Thus, if each physical core is a 4-wide out-of-order design, if a thread running on a virtual core can utilize the resources of all four cores essentially making a giant 16-wide design, then under VISC can do so.
This should instantly throw up a number of questions on ‘What!? How?! Why?! Power? Frequency? Performance? Efficiency? Complexity?’ and as well as many others in the industry, we had the same questions.








97 Comments
View All Comments
tipoo - Friday, February 12, 2016 - link
Pretty interesting stuff. As they open up a bit more and provide more data, I'm cautiously letting myself believe there's a possibility of this taking off, but I'm not budging my optimism meter past 1 until this ships and is positively reviewed.I wonder if it's more likely they'll be bought out first. If Intel sees a credible competitor, that's certainly possible.
willis936 - Friday, February 12, 2016 - link
The prospect of actual single threaded performance increases is exactly what the future of computing needs. I'm not as concerned with the existence of the technology as I am the adoption. Competing with intel is more than just making a good processor. This company will have to convince other companies to integrate a Lot of the controllers and interfaces that intel does for them.easp - Friday, February 12, 2016 - link
If they can actually deliver real single-threaded performance increases, the world will beat a path to their door. On-chip peripherals and off-chip interfaces are cookie-cutter in comparison.Xenonite - Wednesday, February 17, 2016 - link
"If they can actually deliver real single-threaded performance increases, the world will beat a path to their door."Sadly, this is not how the semiconductor industry works. AMD could, for instance, DOUBLE their single threaded integer performance by simply tweaking their ZEN design to utilize 4x~5x the current planned TDP of 95W, using a larger die to spread the increased current load over multiple transistors, double their L1 and L2 cache sizes and to add a low-latency Last Level Cache.
If done before tape-out, AMD can work with the foundry to optimize the transistors' characteristics and operating points, which would easily allow for a doubling in single-threaded throughput.
Even if the raw clock-rate couldn't simply be doubled, they could use the additional power budget to run MUCH more aggressive speculative execution, and to widen their superscalar pipeline to be at least as wide the average instruction pipeline length is long.
Since IPC does not need to be tied to instruction latency, each core could easily complete around 5~6 instructions per clock by having, say, 10~12 fully functional superscalar pipelines (each pipeline can complete any instruction indapendently, without having to rely on shared logic blocks) .
Xenonite - Wednesday, February 17, 2016 - link
Sorry, I submitted the post before I was finished. Basically, it boils down to the fact that no one (other than myself XD) would be willing to pay for such a processor. Even if AMD managed to totally thrash Intel in absolute performance, no one will care. And with no mass consumer support, their shareholders would never approve such a project in the first place.The main reason why VISC is doomed to fail, is quite similar: you simply can not attract investors with raw performance in 2016.
Even if they actually had a ~5x single-threaded performance lead over Intel's fastest consumer desktop chips, they STILL wouldn't get the billions of dollars that they need to do a mass market rollout of their arch.
The whole situation is making me really morbid and depressed; what I wouldn't give to go back to the Pentium 3 days.
Demiurge - Friday, February 12, 2016 - link
16-wide ILP isn't going to be a mass-market solution... most designs are barely using 1.5 instructions per cycle, let alone 4. Given the stellar shift to CPU and then GPU based vector processing... I might be missing something here, but I would say that there are already 16-wide ILP on certain specialized operation that actually benefit, such as video processing for example.Incidentally, does anyone remember Transmeta Code-Morphing Software? If not, look it up...
sonicmerlin - Saturday, February 13, 2016 - link
You didn't even read the fracking article.name99 - Saturday, February 13, 2016 - link
What he's saying (perfectly legitimately) is that- there is a LONG history of companies praising to the skies superficially good ideas which actually turned out not to matter much
- VISC's unwillingness to provide SPECInt numbers, even after being so strongly excoriated about this by the entire tech press and academic world, STRONGLY suggests that what they're peddling does not work the way they claim. It likely provides a great speedup for much FP code (speedup which you can also get by using a GPU, the preferred path of traditional companies), and very little speedup for standard integer code.
The speed at which they claim they can execute also makes one wonder. Even Apple (likely right now the best funded CPU design-house out there, with the simplest target in their sights, working on more or less traditional designs) aims for a major core every two years, with a minor upgrade in between. These guys, with vastly fewer engineers and money, and trying to do something more innovative, believe they can spin a major upgrade every year...
That seems extremely unlikely, so the only real question is: they bullsh*tting only the press/their investors, or are they also bullsh&tting themselves?
Samus - Monday, February 15, 2016 - link
The parallels with Transmetta ring a bell with me, too, and yes, I did read the article. I'm inclined to have a immature capitalist response to things like this, specifically: if a company as big as Intel, with some of the best engineers in the world who are often open to radical ideas, haven't bothered trying an instruction decoder, it is likely because the pros did not outweigh the cons. After all, Jackson technology (hyper threading) is some form of what's going on here, just not targeting specific requests.Azethoth - Wednesday, February 17, 2016 - link
Agreed, and reading the list of unanswered questions it sounds a lot like they are trying to look good in very specific circumstances, rather than being naturally best in class. The competition is GPU + CPU cores. Unless you prove superiority despite all the tricks the competition has available you cannot succeed. What they propose sounds like it needs to break down the normal inter core separation that lets them operate independently so that they can realize single threaded speedup. I am not an EE, so I assume it is at least possible. I am not sure it can be done practically though.