Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
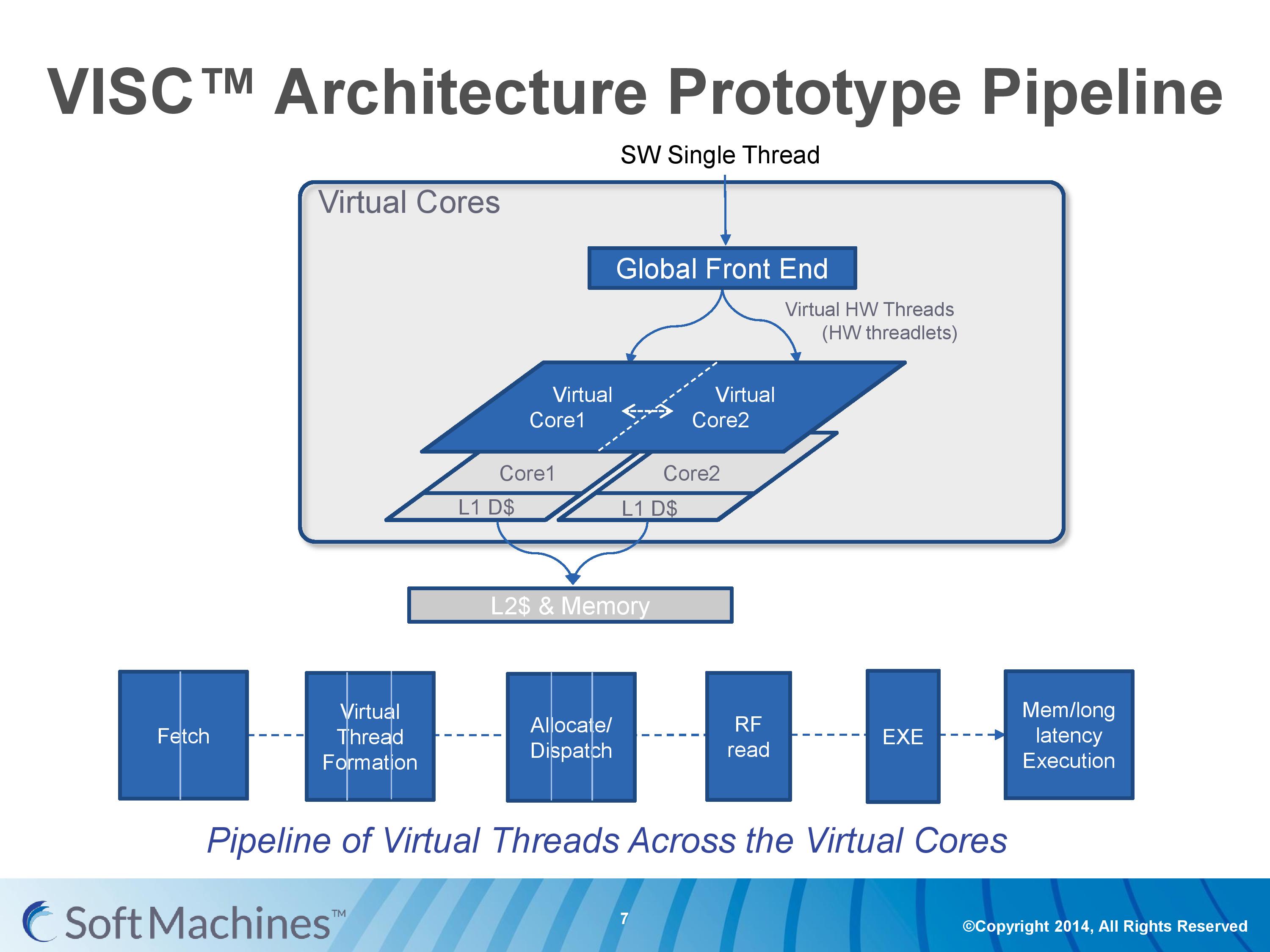
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
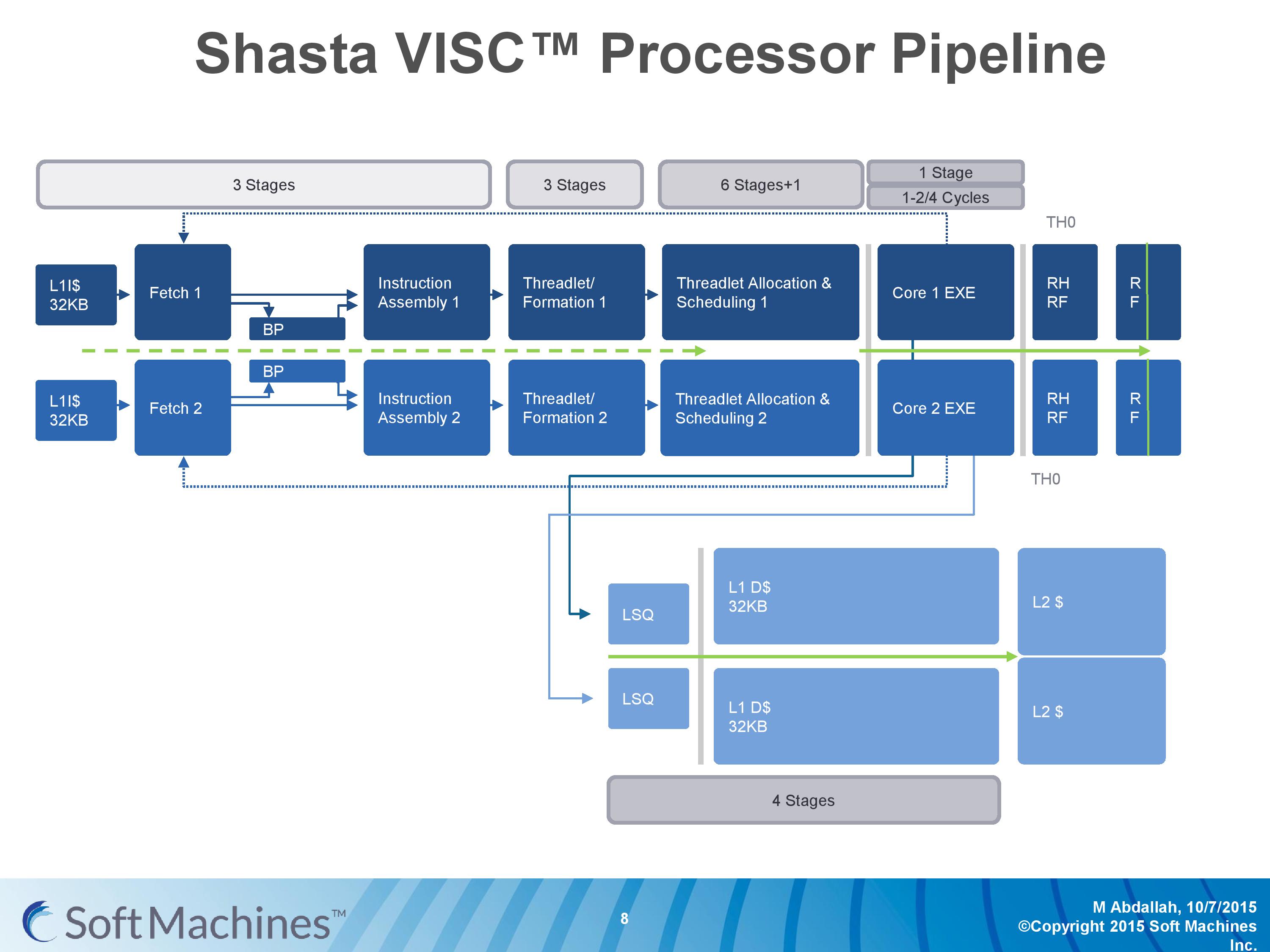
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
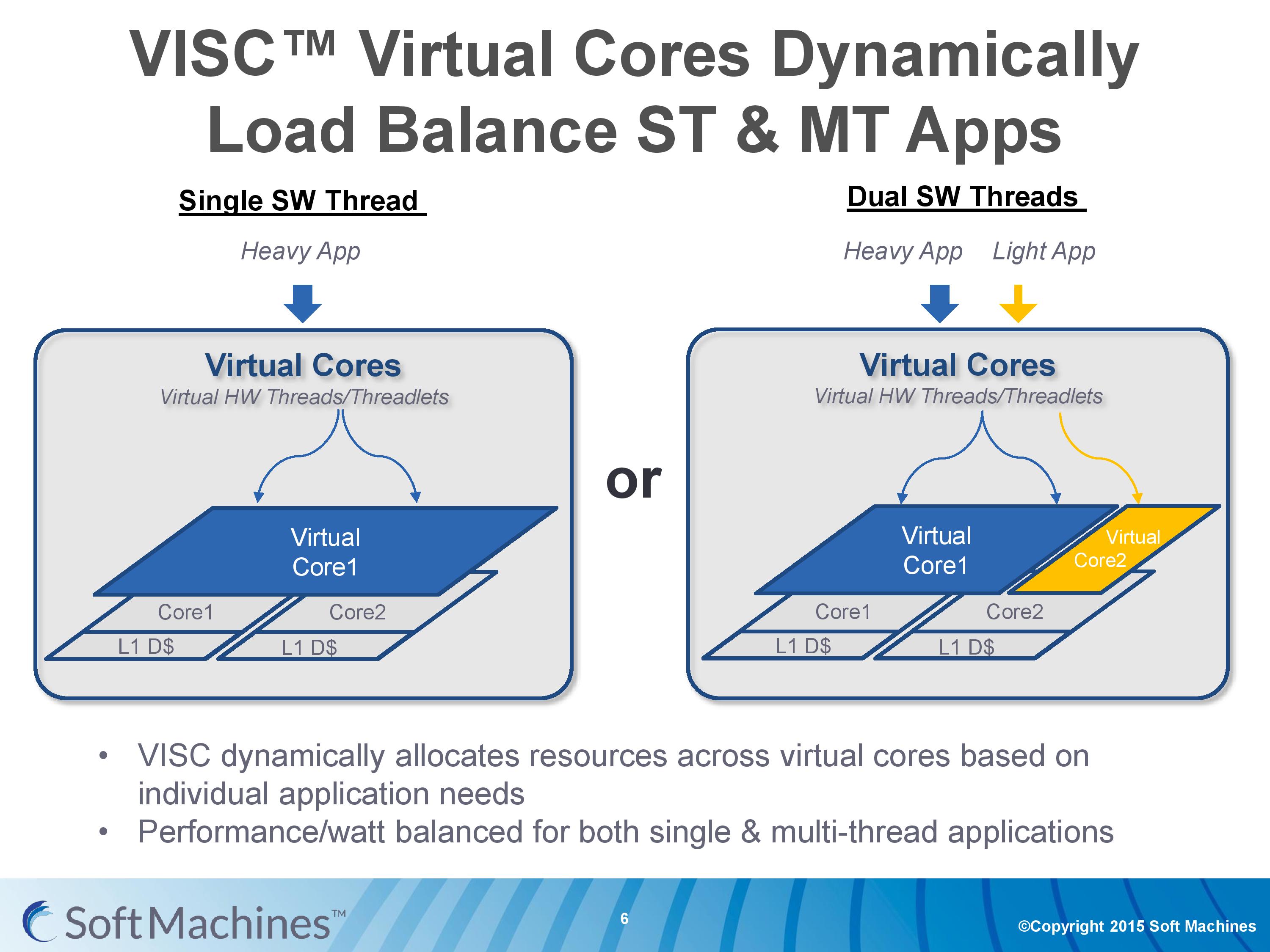
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
tipoo - Friday, February 12, 2016 - link
Pretty interesting stuff. As they open up a bit more and provide more data, I'm cautiously letting myself believe there's a possibility of this taking off, but I'm not budging my optimism meter past 1 until this ships and is positively reviewed.I wonder if it's more likely they'll be bought out first. If Intel sees a credible competitor, that's certainly possible.
willis936 - Friday, February 12, 2016 - link
The prospect of actual single threaded performance increases is exactly what the future of computing needs. I'm not as concerned with the existence of the technology as I am the adoption. Competing with intel is more than just making a good processor. This company will have to convince other companies to integrate a Lot of the controllers and interfaces that intel does for them.easp - Friday, February 12, 2016 - link
If they can actually deliver real single-threaded performance increases, the world will beat a path to their door. On-chip peripherals and off-chip interfaces are cookie-cutter in comparison.Xenonite - Wednesday, February 17, 2016 - link
"If they can actually deliver real single-threaded performance increases, the world will beat a path to their door."Sadly, this is not how the semiconductor industry works. AMD could, for instance, DOUBLE their single threaded integer performance by simply tweaking their ZEN design to utilize 4x~5x the current planned TDP of 95W, using a larger die to spread the increased current load over multiple transistors, double their L1 and L2 cache sizes and to add a low-latency Last Level Cache.
If done before tape-out, AMD can work with the foundry to optimize the transistors' characteristics and operating points, which would easily allow for a doubling in single-threaded throughput.
Even if the raw clock-rate couldn't simply be doubled, they could use the additional power budget to run MUCH more aggressive speculative execution, and to widen their superscalar pipeline to be at least as wide the average instruction pipeline length is long.
Since IPC does not need to be tied to instruction latency, each core could easily complete around 5~6 instructions per clock by having, say, 10~12 fully functional superscalar pipelines (each pipeline can complete any instruction indapendently, without having to rely on shared logic blocks) .
Xenonite - Wednesday, February 17, 2016 - link
Sorry, I submitted the post before I was finished. Basically, it boils down to the fact that no one (other than myself XD) would be willing to pay for such a processor. Even if AMD managed to totally thrash Intel in absolute performance, no one will care. And with no mass consumer support, their shareholders would never approve such a project in the first place.The main reason why VISC is doomed to fail, is quite similar: you simply can not attract investors with raw performance in 2016.
Even if they actually had a ~5x single-threaded performance lead over Intel's fastest consumer desktop chips, they STILL wouldn't get the billions of dollars that they need to do a mass market rollout of their arch.
The whole situation is making me really morbid and depressed; what I wouldn't give to go back to the Pentium 3 days.
Demiurge - Friday, February 12, 2016 - link
16-wide ILP isn't going to be a mass-market solution... most designs are barely using 1.5 instructions per cycle, let alone 4. Given the stellar shift to CPU and then GPU based vector processing... I might be missing something here, but I would say that there are already 16-wide ILP on certain specialized operation that actually benefit, such as video processing for example.Incidentally, does anyone remember Transmeta Code-Morphing Software? If not, look it up...
sonicmerlin - Saturday, February 13, 2016 - link
You didn't even read the fracking article.name99 - Saturday, February 13, 2016 - link
What he's saying (perfectly legitimately) is that- there is a LONG history of companies praising to the skies superficially good ideas which actually turned out not to matter much
- VISC's unwillingness to provide SPECInt numbers, even after being so strongly excoriated about this by the entire tech press and academic world, STRONGLY suggests that what they're peddling does not work the way they claim. It likely provides a great speedup for much FP code (speedup which you can also get by using a GPU, the preferred path of traditional companies), and very little speedup for standard integer code.
The speed at which they claim they can execute also makes one wonder. Even Apple (likely right now the best funded CPU design-house out there, with the simplest target in their sights, working on more or less traditional designs) aims for a major core every two years, with a minor upgrade in between. These guys, with vastly fewer engineers and money, and trying to do something more innovative, believe they can spin a major upgrade every year...
That seems extremely unlikely, so the only real question is: they bullsh*tting only the press/their investors, or are they also bullsh&tting themselves?
Samus - Monday, February 15, 2016 - link
The parallels with Transmetta ring a bell with me, too, and yes, I did read the article. I'm inclined to have a immature capitalist response to things like this, specifically: if a company as big as Intel, with some of the best engineers in the world who are often open to radical ideas, haven't bothered trying an instruction decoder, it is likely because the pros did not outweigh the cons. After all, Jackson technology (hyper threading) is some form of what's going on here, just not targeting specific requests.Azethoth - Wednesday, February 17, 2016 - link
Agreed, and reading the list of unanswered questions it sounds a lot like they are trying to look good in very specific circumstances, rather than being naturally best in class. The competition is GPU + CPU cores. Unless you prove superiority despite all the tricks the competition has available you cannot succeed. What they propose sounds like it needs to break down the normal inter core separation that lets them operate independently so that they can realize single threaded speedup. I am not an EE, so I assume it is at least possible. I am not sure it can be done practically though.