The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
POWER8 Servers: The Reality Check
As we've just seen, the specs of the POWER8 as announced at launch are very impressive. But what about the in the real world? The top models (10-12 at 4 GHz+, 2TB per socket) are still limited to the extremely expensive E870/E880, which typically costs around 3 times as much (or more) as a comparable Xeon E7 system. But there is light at the end of the tunnel: "PowerLinux" quad socket systems are more expensive than comparable x86 systems, but only by 10 to 30%.
The real competition for x86 must probably come from the third parties of the OpenPower Fondation. IBM sells them POWER8 chips at much more reasonable prices ($2k - $3k), so it is possible to build a reasonably priced POWER8 system. The POWER8 chips sold to third parties are somewhat "lighter" versions, but that is more an advantage than you would think. For example, by keeping the clockspeed a bit lower, the power consumption is lower (190W TDP). These chips also have only 4 (instead of 8) memory buffer chips, which "limits" them to 1 TB of memory, but again this saves quite a bit of power, between 50W and 80W. In other words, the POWER8 chips available to third parties are much more reasonable and even more competitive than the power gobbling, ultra expensive behemoths that got all the attention at launch.
Tyan already has an one socket server and several Taiwanese (Wistron) and Chinese vendors are developing 2 socket systems. Quad socket models are not yet on the horizon as far as we know, but is probably going to change soon.
POWER8 vs. Xeon E5 v3: SPECing It Out
Unfortunately we did not have access to a full blown POWER8 system at this time. But as our loyal readers know, we do not limit our server testing to the x86 world (see here and here) . So until a POWER8 system arrives, we'll have to check out the available industry standard benchmarks. To that end we looked up the SPEC CPU2006 numbers for a single socket CPU.
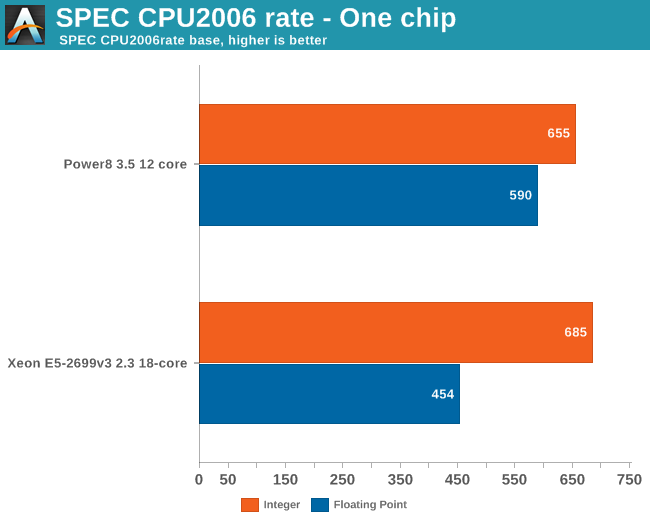
The 12 cores inside the POWER8 - the single socket chips found in the more reasonable priced servers - perform very well. The integer performance is only a few percentages lower than the Intel chip and POWER8's floating point performance is well ahead of the Xeon.
Overall the POWER8 is quite capable of keeping up with the Xeon E5-2699v3. And don't let the "2.3 GHz" official clockspeed fool you into thinking that the Xeons are clocked unnecessarily low, either: in SPECint, the XEON is running at 2.8 GHz most of the time.
Ultimately, the POWER8 is able to offer slightly higher raw performance than the Intel CPUs, however it just won't be able to do so at the same performance/watt. Meanwhile the reasonable pricing of the POWER8 chips should result in third party servers that are strongly competitive with the Xeon on a performance-per-dollar basis. Reasonably priced, well performing dual and quad socket Linux on Power servers should be possible very soon.








146 Comments
View All Comments
kgardas - Thursday, May 21, 2015 - link
@Kevin G: thanks for the correction about load/store units doing simple integer operations. I agree with your testing that single-threaded POWER8 is not up to the speed of Haswell. In fact my testing shows it's on the same level like POWER7.So with POWER8 doing 6 integer ops in cycle, it's more powerful than SPARC64 X which is doing 4 or than SPARC S3 core which is doing just 2. It also explain well spec rate difference between M10-4 and POWER8 machine. Good! Things start to be more clear now...
patrickjp93 - Saturday, May 16, 2015 - link
No, just no. Intel solved the cluster latency problem long ago with Infiniband revisions. 4 nanoseconds to have a 10-removed node tell the head node something or vice versa, and no one builds hypercube or start topology that's any worse than 10-removed.Brutalizer - Sunday, May 17, 2015 - link
@patrickjp93,If Intel solved the cluster latency problem, then why are not SGI UV2000 and ScaleMP clusters used to run monolithic business software? Question: Why are there no SGI UV2000 top records in SAP?
Answer: Because they can not run monolithich software that branches too much. That is why there are no good x86 benchmarks.
misiu_mp - Tuesday, June 2, 2015 - link
Just to point out, 10ns at the speed of light in vacuum is 3m, and signalling is slower than that because of the fibre medium (glass) limits the sped of light to about 60% of c and on top of that come electronic latencies. So maybe you can get 10ns latency over 1-1.5m maximum. That's not a large cluster.Kevin G - Monday, May 11, 2015 - link
I am not uninformed. I would say that you're being willfully ignorant. In fact, you ignored my previous links about this very topic when I could actually find examples for you. ( For the curious outsider: http://www.anandtech.com/comments/7757/quad-ivy-br... )So again I will cite the US Post Office using SGI machines to run Oracle Times Ten databases:
http://www.intelfreepress.com/news/usps-supercompu...
As for the UV 2000 not being a scale up sever, did you not watch the videos I posted? You can see Linux tools in the videos clearly that indicate that it was produced on a 64 socket system. If that is not a scale up server, why are the LInux tools reporting it as such? If the UV 2000 series isn't good for SAP, then why is HANA being tuned to run on it by both SGI and SAP?
HP's Superdome X shares a strong relationship with the Itanium based Superdome 2 machine: they use the same chipset to scale past 8 sockets. This is because the recent Itaniums and Xeons both use QPI as an interconnect bus. So if the Superdome X is a cluster, then so is its Itanium 2 based offerings using that same chipset. Speaking of, that chipset does go up to 64 sockets and there is the potential to go that far (source: http://www.enterprisetech.com/2014/12/02/hps-itani... ). It won't be a decade if HP already has working chipset that they've shipped in other machines. :)
Speaking of the Superdome X, it is fast and can outrun the SPARC M10-4S at the 16 socket level by a fatctor of 2.38. Even with perfect scaling, the SPARC system would need more than 32 sockets to compete. Oh wait, if we go by your claim above that "you double the number of sockets, you will likely gain 20% or so" then the SPARC system would need to scale to 512 sockets to be competitive with the Superdome X. (Source: http://h20195.www2.hp.com/V2/getpdf.aspx/4AA5-6149... )
And if you're dead set on an >8 socket SAP benchmark using x86 processors, here is one, though a bit dated:
https://www.vmware.com/files/pdf/partners/ibm/ibm-...
68k - Tuesday, May 12, 2015 - link
You know, those >8 socket systems are flying of the shelf faster than anyone can produce them. That is why Intel only got, according to the article, 92-94% of the >4-sockets market... It seem pretty safe to state that >8 socket is an extreme niche market, which is probably why it is hard to find any benchmarks on such systems.The price point of really big scaled-up servers is also an extreme intensive to think very hard about how one can design software to now require a single system. Some problems absolutely need scale-up, as you pointed out, there are such x86 systems available and have been for quite some time.
Anyone know what the ratio between the 2-socket servers vs >4-socket in terms of market share (number of deployed systems) look like?
68k - Tuesday, May 12, 2015 - link
No edit... Pretend that '>' means "greater or equal" in the post above.Arkive - Tuesday, May 12, 2015 - link
You guys are obviously not idiots, just enormously stubborn. Why don't you take the wealth of time you spend fighting on the internet and do something productive instead?kgardas - Wednesday, May 13, 2015 - link
Kevin, I'll not argue with you about SGI UV. It's in fact very nice machine and it looks like it is on part with latency to Sun/Oracle Bixby interconnect. Anyway, what I would like to note is about your Superdome X comparison to SPARC M10-4S. Unfortunately IMHO this is purely CPU benchmark. It's multi-JVM so if you use one JVM per one processor, you pin that JVM to this processor and limit its memory to the size (max) of memory available to the processor, then basically you do have kind of scale-out cluser inside one machine. This is IMHO what they are benchmarking. What it just shows that current SPARC64 is really not up to the performance level of latest Xeon. Pity, but is fact. Anyway, my point is, for memory scalability benchmark you should use something different than multi-jvm bench. I would vote for stream here, although it's still bandwidth oriented still it provides at least some picture: https://www.cs.virginia.edu/stream/top20/Bandwidth... -- no Superdome there and HP submitted some Superdome results in the past. Perhaps it's not memory scalability hero these days?ats - Tuesday, May 12, 2015 - link
So that must be why SAP did this for SGI: https://www.sgi.com/company_info/newsroom/awards/s...You don't normally recognize partners for innovation for your products unless they are filling a need. AKA SGI actually sells their UV300H appliance.
And SAP HANA like ALL DBs can be used both SSI or clustered.
And the SAP SD 2-Tier benchmark is not at all monolithic. The whole 2-tier thing should of been a hint. And SAP SD 3-Tier is also not monolithic.
Scaling for x86 is no easier nor no harder than for any other architecture for large scale coherent systems. If you think it is, its because you don't know jack. I've designed CPUs/Systems that can scale up to 256 CPUs in a coherent image, fyi. Also it should probably be noted that the large scale systems are pretty much never used as monolithic systems, and almost always used via partitioning or VMs.