The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
POWER8 Servers: The Reality Check
As we've just seen, the specs of the POWER8 as announced at launch are very impressive. But what about the in the real world? The top models (10-12 at 4 GHz+, 2TB per socket) are still limited to the extremely expensive E870/E880, which typically costs around 3 times as much (or more) as a comparable Xeon E7 system. But there is light at the end of the tunnel: "PowerLinux" quad socket systems are more expensive than comparable x86 systems, but only by 10 to 30%.
The real competition for x86 must probably come from the third parties of the OpenPower Fondation. IBM sells them POWER8 chips at much more reasonable prices ($2k - $3k), so it is possible to build a reasonably priced POWER8 system. The POWER8 chips sold to third parties are somewhat "lighter" versions, but that is more an advantage than you would think. For example, by keeping the clockspeed a bit lower, the power consumption is lower (190W TDP). These chips also have only 4 (instead of 8) memory buffer chips, which "limits" them to 1 TB of memory, but again this saves quite a bit of power, between 50W and 80W. In other words, the POWER8 chips available to third parties are much more reasonable and even more competitive than the power gobbling, ultra expensive behemoths that got all the attention at launch.
Tyan already has an one socket server and several Taiwanese (Wistron) and Chinese vendors are developing 2 socket systems. Quad socket models are not yet on the horizon as far as we know, but is probably going to change soon.
POWER8 vs. Xeon E5 v3: SPECing It Out
Unfortunately we did not have access to a full blown POWER8 system at this time. But as our loyal readers know, we do not limit our server testing to the x86 world (see here and here) . So until a POWER8 system arrives, we'll have to check out the available industry standard benchmarks. To that end we looked up the SPEC CPU2006 numbers for a single socket CPU.
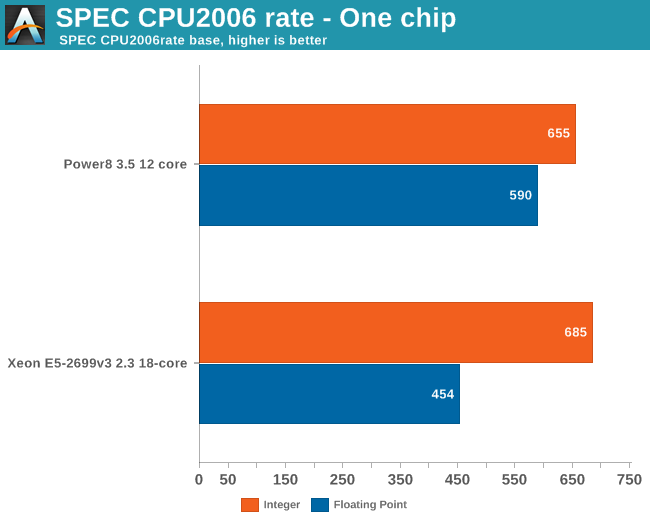
The 12 cores inside the POWER8 - the single socket chips found in the more reasonable priced servers - perform very well. The integer performance is only a few percentages lower than the Intel chip and POWER8's floating point performance is well ahead of the Xeon.
Overall the POWER8 is quite capable of keeping up with the Xeon E5-2699v3. And don't let the "2.3 GHz" official clockspeed fool you into thinking that the Xeons are clocked unnecessarily low, either: in SPECint, the XEON is running at 2.8 GHz most of the time.
Ultimately, the POWER8 is able to offer slightly higher raw performance than the Intel CPUs, however it just won't be able to do so at the same performance/watt. Meanwhile the reasonable pricing of the POWER8 chips should result in third party servers that are strongly competitive with the Xeon on a performance-per-dollar basis. Reasonably priced, well performing dual and quad socket Linux on Power servers should be possible very soon.








146 Comments
View All Comments
thunng8 - Monday, May 11, 2015 - link
Sorry about the languageA couple points that are wrong on benchmarks:
- The Power7 p270 is a 2 socket system with 2 processors in one socket (4 processors). It was designed to get more cores into 1 socket and not outright performance per processor. If you want to show the best quad processor on 4 socket system, then it would be this result:
http://download.sap.com/download.epd?context=40E2D...
- Your comment about Power7 needing more sockets to match Intel is not based on reality. IBM held the 8 socket lead in SAP SD from March 2010 with this result:
http://download.sap.com/download.epd?context=40E2D...
It wasn't surpassed by Intel until June 2014 with this result:
http://download.sap.com/download.epd?context=40E2D...
Note: Even the Power7 result from 2010 shows higher throughput per core than the just released Haswell server chips.
And then 4 months later Power8 overtook it again. BTW, IBM recently announced the 12 core 4.02Ghz cpu in the E880..that should get an extra ~15% throughput per socket.
- Power8 L2 cache runs at full speed clock speed
A point completely overlooked and what makes Power systems really excel is the efficiency of the Power hypervisor. IMO it is the biggest selling point of the Power ecosystem.
thunng8 - Monday, May 11, 2015 - link
Another datapoint (not on spec site yet, but listed on the IBM e880 performance site):http://www-03.ibm.com/systems/power/hardware/e880/...
SpecIntRate: 14400
SpecfpRate: 11400
Which makes it (per processor):
SpecIntrate: 900
SepcfpRate: 713
thunng8 - Monday, May 11, 2015 - link
Also, the ibm power 760 is the same deal with the p270.It is actually a 4 socket system with 2 processors per socket.
Technical overview here:
http://www.redbooks.ibm.com/redpapers/pdfs/redp498...
thunng8 - Wednesday, May 13, 2015 - link
Well, it has been a few days since I've listed a quite few of your misrepresentations of the data in comparison to POWER, and nothing has changed and no reply at all.I find it hilarious that you can put this text in the article:
"the new POWER8 has made the Enterprise line of IBM more competitive than ever. Gone are the days that IBM needed more CPU sockets than Intel to get the top spot."
and still have it there when I've pointed out over the last 5 years (or maybe longer, I couldn't be bothered looking further), Intel has only overtaken POWER system for only 4 months. i.e. 4 months out of 60+ months
JlHADJOE - Sunday, May 10, 2015 - link
"No less than 98% of the server shipments have been 'Intel inside'... From the revenue side, the RISC based systems are still good for slightly less than 20% of the $49 Billion (per year) server market*."Wow! So RISC has 2% market share and 20% revenue.
FunBunny2 - Monday, May 11, 2015 - link
Gee. Sounds kinda like the Apple approach to production.akula2 - Sunday, May 10, 2015 - link
POWER8 is far better than Intel's counterpart.IBM is way ahead of Intel for the next generation computing with their Brain Chip.
I hope Intel's share slips with the emerging ARM 64 bit CPU (A-72) in the Server space.
ats - Tuesday, May 12, 2015 - link
Whoa, there is wrong then there is Brutalizer WRONG!First of all many IMDBs support full locking at multiple granularity including both TimesTen and SAP HANA. IMDBs are not read only and are used in the most critical performance transaction processing scenarios (because disk based DBs simply can't keep up!)
Second, IMDBs are used for a variety of DB workloads from transaction processing to analytic workloads.
Third, if your queries are taking hours, you are doing analytic workloads, not transaction processing. Transaction processing is the DB workload most dependent on locking functionality and requires real time responses. Analytic workloads are the least dependent on locking performance.
Fourth, many IMDBs are designed and deployed as the sole DB layer, including SAP HANA and TimesTen. Both fully support shadowing to disk.
Fifth, you can run businesses on **SCALE UP** severs like UV2K. Unless you now want to claim you can run businesses on mainframes, Sun's large scale servers, Fujitsu's large scale servers, IBMs large scale servers, or HP's large scale servers.
Sixth, if you think an UV2K is a cluster, you don't have enough knowledge to even post about this topic. UV2k is a SSI cache coherent SMP, no different than Oracle Sparc M6 or and IBM P795.
Seventh, you don't need a direct channel between sockets. You have never needed a direct channel between sockets. In fact the system that put Sun on the map, UE10K, did not have direct connections between each socket. In fact MANY MANY large scale sun systems have not had direct connections between sockets. If you actually knew anything about the history of big servers you would know that direct connections can be slower, using switches can be slower, and using torii and hypercubes can be slower, or they all can be faster. Looking at an interconnection network topology doesn't tell you jack. What matters is latency and latency vs load.
Eighth, people who fail at math should probably not try to make math based arguments. To directly connect N sockets, each socket needs N-1 links, no n^2 links. And you should probably learn something about how bandwidth and latency works. The more you directly connect, the less bandwidth you have between each node and the highly the latency hot spotting becomes. Using min channel widths isn't necessarily the best solution. And actually, you can have throughput and low latency, it just impacts cost.
Ninth, ScaleMP has no relation to SGI's UV2k. None.
10th, more business software runs on X86 than anything else in the world. More DBs run on x86 than anything else in the world. And neither ScaleMP nor UV2k are scale out solutions. UV2K is a pure scale-up system. You might know that if you only had a clue.
1) There are 8, 16, 32, 64, 128, AND 256 processor **SCALE-UP** x86 systems. And the x86 Superdome delivers higher performance than any previous HP scale-up system. And no, you don't need socket counts, you need performance. Socket counts are quite immaterial, and shrinking by the by.
2) SGI UV2K is not a scale out system. Its a SSI Scale Up system. When you finally admit this, you'll be one step closer to not riding the short bus.
And fyi, plenty of people use x86 for large sap installations. In fact, x86 runs more sap installations than anyone else combined.
Oh and: http://global.sap.com/solutions/benchmark/bweml-re...
And just for fun, WE LAUGH AT YOUR PUNY ORACLE SAPS: http://global.sap.com/solutions/benchmark/sd3tier.... still under a million? You are being beaten by 8 socket servers, ouch that's gotta hurt!
ats - Tuesday, May 12, 2015 - link
Whoa, there is wrong then there is Brutalizer WRONG!First of all many IMDBs support full locking at multiple granularity including both TimesTen and SAP HANA. IMDBs are not read only and are used in the most critical performance transaction processing scenarios (because disk based DBs simply can't keep up!)
Second, IMDBs are used for a variety of DB workloads from transaction processing to analytic workloads.
Third, if your queries are taking hours, you are doing analytic workloads, not transaction processing. Transaction processing is the DB workload most dependent on locking functionality and requires real time responses. Analytic workloads are the least dependent on locking performance.
Fourth, many IMDBs are designed and deployed as the sole DB layer, including SAP HANA and TimesTen. Both fully support shadowing to disk.
Fifth, you can run businesses on **SCALE UP** severs like UV2K. Unless you now want to claim you can run businesses on mainframes, Sun's large scale servers, Fujitsu's large scale servers, IBMs large scale servers, or HP's large scale servers.
Sixth, if you think an UV2K is a cluster, you don't have enough knowledge to even post about this topic. UV2k is a SSI cache coherent SMP, no different than Oracle Sparc M6 or and IBM P795.
Seventh, you don't need a direct channel between sockets. You have never needed a direct channel between sockets. In fact the system that put Sun on the map, UE10K, did not have direct connections between each socket. In fact MANY MANY large scale sun systems have not had direct connections between sockets. If you actually knew anything about the history of big servers you would know that direct connections can be slower, using switches can be slower, and using torii and hypercubes can be slower, or they all can be faster. Looking at an interconnection network topology doesn't tell you jack. What matters is latency and latency vs load.
Eighth, people who fail at math should probably not try to make math based arguments. To directly connect N sockets, each socket needs N-1 links, no n^2 links. And you should probably learn something about how bandwidth and latency works. The more you directly connect, the less bandwidth you have between each node and the highly the latency hot spotting becomes. Using min channel widths isn't necessarily the best solution. And actually, you can have throughput and low latency, it just impacts cost.
Ninth, ScaleMP has no relation to SGI's UV2k. None.
10th, more business software runs on X86 than anything else in the world. More DBs run on x86 than anything else in the world. And neither ScaleMP nor UV2k are scale out solutions. UV2K is a pure scale-up system. You might know that if you only had a clue.
1) There are 8, 16, 32, 64, 128, AND 256 processor **SCALE-UP** x86 systems. And the x86 Superdome delivers higher performance than any previous HP scale-up system. And no, you don't need socket counts, you need performance. Socket counts are quite immaterial, and shrinking by the by.
2) SGI UV2K is not a scale out system. Its a SSI Scale Up system. When you finally admit this, you'll be one step closer to not riding the short bus.
And fyi, plenty of people use x86 for large sap installations. In fact, x86 runs more sap installations than anyone else combined.
Oh and: http://global.sap.com/solutions/benchmark/bweml-re...
And just for fun, WE LAUGH AT YOUR PUNY ORACLE SAPS: http://global.sap.com/solutions/benchmark/sd3tier.... still under a million? You are being beaten by 8 socket servers, ouch that's gotta hurt!
MyNuts - Tuesday, May 12, 2015 - link
Great, i guess. Wheres the holograms and teleporters. I see just another calculator :(