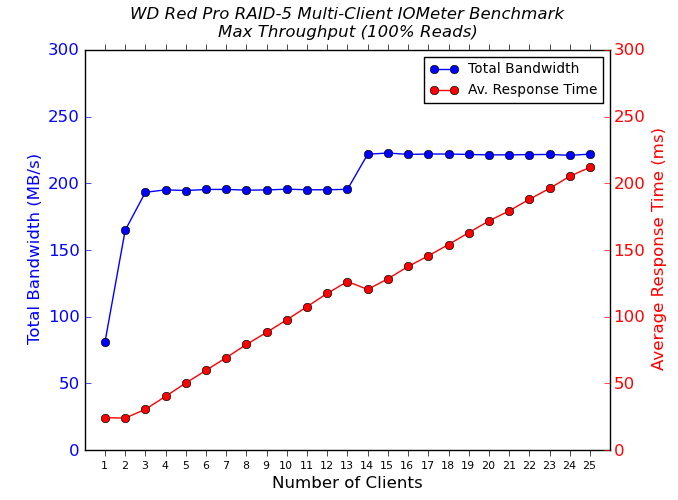
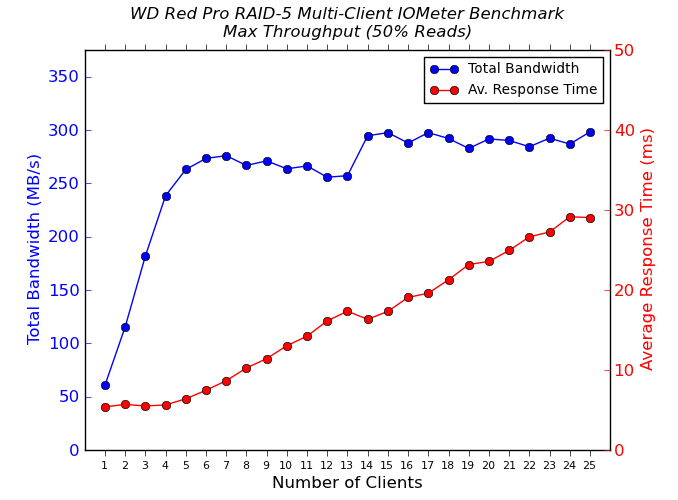
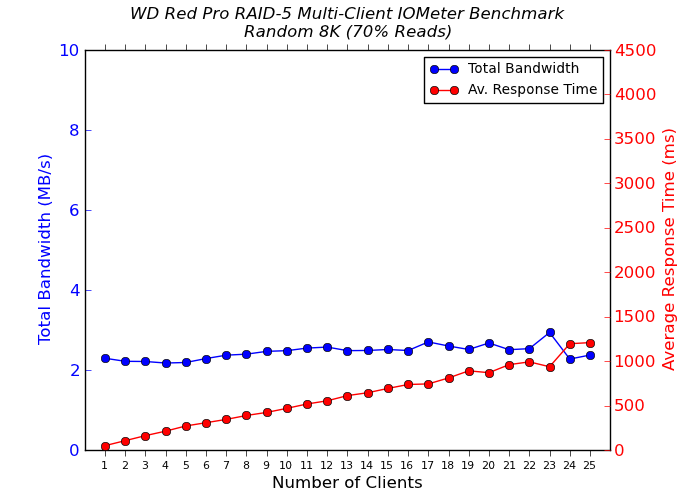
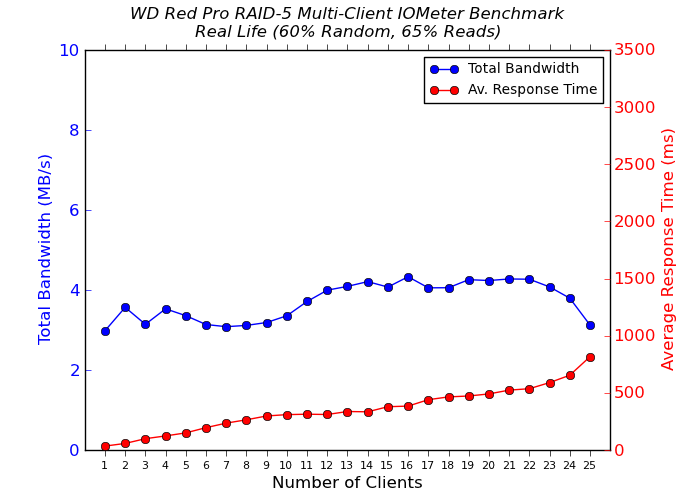
We put the NAS drives in the QNAP TS-EC1279U-SAS-RP through some IOMeter tests with a CIFS share being accessed from up to 25 VMs simultaneously. The following four graphs show the total available bandwidth and the average response time while being subject to different types of workloads through IOMeter. IOMeter also reports various other metrics of interest such as maximum response time, read and write IOPS, separate read and write bandwidth figures etc. Some of the interesting aspects from our IOMeter benchmarking run are linked below:
We see that the sequential accesses are still limited by the network link, but, this time, on the NAS side. On the other hand, our random access tests show markedly better performance for drives such as the Seagate Enterprise Capacity, Seagate Constellation, WD Re, etc. Not only is the total available bandwidth higher, the average response times also go down.
Nice catch. I just went and looked up all of them.
RE = 10 in 10^16 Red Pro = 10 in 10^15 SE = 10 in 10^15 Black = 1 in 10^14 Red = 1 in 10^14 Green = 1 in 10^14
It looks like they switched to this marketing on RE and SE. The terms are in black and white, but it is a deviation from a measurement scheme, and can only be construed as deceiving in my book. I love WD, but this pisses me off.
For my home/home office use, the most important aspect by far for me is reliability/failure rates, mainly because I don't want to invest in more than 2 drives or go beyond Raid 1. I realize the most robust reliability info is based on several years of statistics in the field, but is their any kind of accelerated life test that Anandtech can do or get access to that has been proven to be a fairly reliable indicator of reliability/failure rates differences across the models? I'm aware of the manufacturer specs, but I don't regard those as objective or measured apples-apples across manufacturers.
If historical reliability data is fairly consistent across multiple drives across a manufacturers' line, perhaps at least provide that as a proxy for predicted actual reliability. Thanks for considering any of this!
If you're really concerned about reliability, you need double-parity rather than RAID-1. In a double parity situation the system knows which drive is returning bad data. With RAID-1 is doesn't know which drive is right. Of course either way you should have a robust backup infrastructure in place if your data matters.
If you speak about silent data corruption (ie: read error that aren't detected by the build in ECC), RAIDZ2 and _some_ RAID6 implementation should be able to isolate the wrond data. However this require that for every read both parity data (P and Q) are re-calculated, hammering the disk subsystem and the controller's CPU. RAIDZ2, by design, do this precise thing (N disks in a single RAIDZ array give you the same IOPS that a single disk), but many RAID6 implementation simply don't do that for performance reason (Linux MDRAID, for example, don't to it).
If you are referring to UREs, even a single parity scheme as RAID5 is sufficient for non-degraded conditions. The true problem is for the degraded scenario: in this case and on most hardware RAID implementation, a single URE error will kill your entire array (note: MDRAID behave differently and let you to recover _even_ from this scenario, albeit with some corrupted data and in different manner based on its version). In this case, a double parity scheme is a big advantage.
On the other hand, while mirroring is not 100% free from URE risk, it need to re-read the content of a _single_ disk, not the entire array. In other word, it is less exposed to URE problem then RAID5 simply because it has to read less data to recover from a failure (but with current capacities RAID6 is even less exposed to this kind of error).
MDRAID will recheck all of the parity during a scrub. That's really enough to catch silent data corruption before your backups go stale. It's not perfect but is a good balance between safety and performance. The problem with RAID5 compared to RAID6 is that in a URE situation the RAID5 will still silently produce garbage as it has no way to know if the data is correct. RAID6 is at least capable of spotting those read errors.
I think you are confusing URE with silent dats corruption. An URE in non-degraded RAID 5 will not produce any data corruption, it will simply trigger a stripe reconstruction.
An URE in degraded RAID 5 will not produce any data corruption, but it will result in a "dead" or faulty array.
A regular scrub will prevents unexpected UREs, but if a drive suddenly become returning garbage, even regular scrubs can not do anything.
In theory, RAID6 can identify what drive is returning garbage because it has two different parity data. However, as stated above, that kind of control is avoided due to the severe performance penalties it implies.
RAIDZ2 take the safe path and do a complete control for every read, but as results its performance is quite low.
We’ve updated our terms. By continuing to use the site and/or by logging into your account, you agree to the Site’s updated Terms of Use and Privacy Policy.








62 Comments
View All Comments
sin_tax - Thursday, August 21, 2014 - link
Transcoding != streaming. Most all NAS boxes are underpowered when it comes to transcoding.jaden24 - Friday, August 8, 2014 - link
Correction.WD Red Pro: Non-Recoverable Read Errors / Bits Read 10^15
Per Hansson - Friday, August 8, 2014 - link
I'm not qualified to say for certain, but I think it's just marketingbullshit to make the numbers look better when infact they are the same?
Non-Recoverable Read Errors per Bits Read:
<1 in 10^14 WD Red
<10 in 10^15 WD Red Pro
<10 in 10^15 WD Se
Just for reference the Seagate Constellation ES.3, Hitachi Ultrastar He6 &
7K4000 are all rated for: 1 in 10^15
shodanshok - Friday, August 8, 2014 - link
Hi, watch at the specs carefully: WD claim <10 errors for 10^15 bytes read.Previously, it was <1 each 10^14.
In other word, they increase the exponent (14 vs 15), but the value is (more or less) the same!
jaden24 - Friday, August 8, 2014 - link
Nice catch. I just went and looked up all of them.RE = 10 in 10^16
Red Pro = 10 in 10^15
SE = 10 in 10^15
Black = 1 in 10^14
Red = 1 in 10^14
Green = 1 in 10^14
It looks like they switched to this marketing on RE and SE. The terms are in black and white, but it is a deviation from a measurement scheme, and can only be construed as deceiving in my book. I love WD, but this pisses me off.
isa - Friday, August 8, 2014 - link
For my home/home office use, the most important aspect by far for me is reliability/failure rates, mainly because I don't want to invest in more than 2 drives or go beyond Raid 1. I realize the most robust reliability info is based on several years of statistics in the field, but is their any kind of accelerated life test that Anandtech can do or get access to that has been proven to be a fairly reliable indicator of reliability/failure rates differences across the models? I'm aware of the manufacturer specs, but I don't regard those as objective or measured apples-apples across manufacturers.If historical reliability data is fairly consistent across multiple drives across a manufacturers' line, perhaps at least provide that as a proxy for predicted actual reliability. Thanks for considering any of this!
NonSequitor - Friday, August 8, 2014 - link
If you're really concerned about reliability, you need double-parity rather than RAID-1. In a double parity situation the system knows which drive is returning bad data. With RAID-1 is doesn't know which drive is right. Of course either way you should have a robust backup infrastructure in place if your data matters.shodanshok - Friday, August 8, 2014 - link
Mmm... it depends.If you speak about silent data corruption (ie: read error that aren't detected by the build in ECC), RAIDZ2 and _some_ RAID6 implementation should be able to isolate the wrond data. However this require that for every read both parity data (P and Q) are re-calculated, hammering the disk subsystem and the controller's CPU. RAIDZ2, by design, do this precise thing (N disks in a single RAIDZ array give you the same IOPS that a single disk), but many RAID6 implementation simply don't do that for performance reason (Linux MDRAID, for example, don't to it).
If you are referring to UREs, even a single parity scheme as RAID5 is sufficient for non-degraded conditions. The true problem is for the degraded scenario: in this case and on most hardware RAID implementation, a single URE error will kill your entire array (note: MDRAID behave differently and let you to recover _even_ from this scenario, albeit with some corrupted data and in different manner based on its version). In this case, a double parity scheme is a big advantage.
On the other hand, while mirroring is not 100% free from URE risk, it need to re-read the content of a _single_ disk, not the entire array. In other word, it is less exposed to URE problem then RAID5 simply because it has to read less data to recover from a failure (but with current capacities RAID6 is even less exposed to this kind of error).
Regards.
NonSequitor - Friday, August 8, 2014 - link
MDRAID will recheck all of the parity during a scrub. That's really enough to catch silent data corruption before your backups go stale. It's not perfect but is a good balance between safety and performance. The problem with RAID5 compared to RAID6 is that in a URE situation the RAID5 will still silently produce garbage as it has no way to know if the data is correct. RAID6 is at least capable of spotting those read errors.shodanshok - Friday, August 8, 2014 - link
I think you are confusing URE with silent dats corruption. An URE in non-degraded RAID 5 will not produce any data corruption, it will simply trigger a stripe reconstruction.An URE in degraded RAID 5 will not produce any data corruption, but it will result in a "dead" or faulty array.
A regular scrub will prevents unexpected UREs, but if a drive suddenly become returning garbage, even regular scrubs can not do anything.
In theory, RAID6 can identify what drive is returning garbage because it has two different parity data. However, as stated above, that kind of control is avoided due to the severe performance penalties it implies.
RAIDZ2 take the safe path and do a complete control for every read, but as results its performance is quite low.
Regards.