6 TB NAS Drives: WD Red, Seagate Enterprise Capacity and HGST Ultrastar He6 Face-Off
by Ganesh T S on July 21, 2014 11:00 AM ESTSingle Client Access - DAS and NAS Environments
The drives under test were connected to a 6 Gbps SATA port off the PCH in our DAS testbed. After formatting in NTFS, they were subject to our DAS test suite. The results are presented in the table below.
| 6 TB NAS Drives Face-Off: DAS Benchmarks (MBps) | ||||||
| WD Red 6 TB | Seagate Enterprise Capacity v4 | HGST Ultrastar He6 | ||||
| Read | Write | Read | Write | Read | Write | |
| Photos | 137.3 | 141.45 | 146.36 | 193.52 | 146.72 | 102.54 |
| Videos | 138.11 | 137.25 | 185.94 | 207.34 | 149.71 | 104.74 |
| Blu-ray Folder | 136.1 | 140.22 | 185.12 | 215.47 | 149.81 | 107.03 |
| Adobe Photoshop (Light) | 2.54 | 237.28 | 7.22 | 225.41 | 5.9 | 248.37 |
| Adobe Photoshop (Heavy) | 3.32 | 250.14 | 9.68 | 210.47 | 8.03 | 235.11 |
| Adobe After Effects | 2.27 | 96.75 | 7.27 | 49.66 | 5.98 | 17.05 |
| Adobe Illustrator | 2.36 | 101.77 | 7.11 | 163.16 | 5.9 | 71.59 |
On the NAS environment side, we configured three drives in RAID-5 in the QNAP TS-EC1279U-SAS-RP unit. Two of the network links were bonded (configured with 802.3ad LACP). Our usual Intel NASPT / robocopy benchmarks were processed from a virtual machine in our NAS testbed. The results are presented in the graph below.
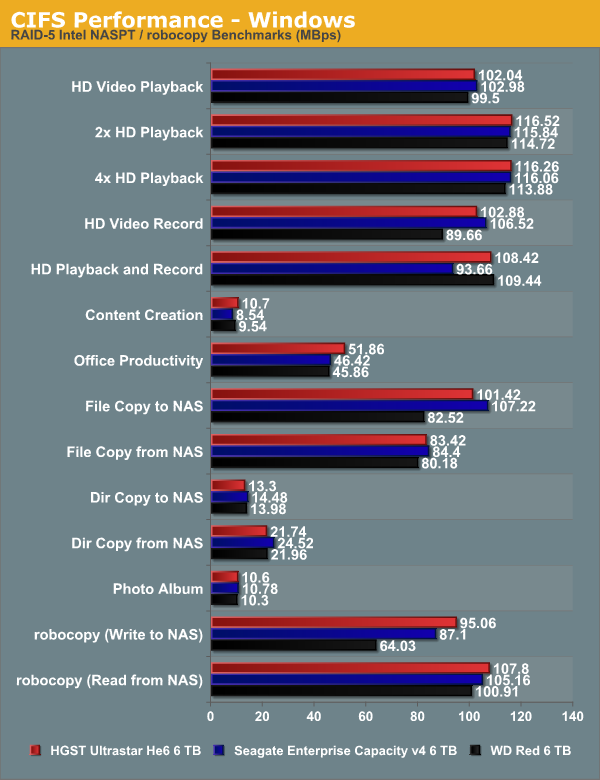
The results above indicate that when it comes to a networked environment, the lower rotational speeds of the WD Red 6 TB are not much of an issue for single client accesses. It manages to acquit itself well in most of the test cases. Write-intensive workloads do cause the performance to drop a bit. Between the HGST Ultrastar He6 and the Seagate Enterprise Capacity, there is not much to help differentiate in this particular evaluation routine.








83 Comments
View All Comments
brettinator - Friday, March 18, 2016 - link
I realize this is years old, but I did indeed use raw i/o on a 10TB fried RAID 6 volume to recover copious amounts of source code.andychow - Monday, November 24, 2014 - link
@extide, you've just shown that you don't understand how it works. You're NEVER going to have checksum errors if your data is being corrupted by your RAM. That's why you need ECC RAM, so errors don't happen "up there".You might have tons of corrupted files, you just don't know it. 4 GB of RAM has a 96% percent chance of having a bit error in three days without ECC RAM.
alpha754293 - Monday, July 21, 2014 - link
Yeah....while the official docs say you "need" ECC, the truth is - you really don't. It's nice, and it'll help to mitigate like bit-flip errors and stuff like that, but I mean...by that point, you're already passing PBs of data through the array/zpool before it's even noticable. And part of that has to do with the fact that it does block-by-block checksumming, which means that given the nature of how people run their systems, it'll probably reduce your ERRs even further, but you might be talking like a third of what's already an INCREDIBLY small percentage.A system will NEVER complain if you have ECC RAM (and have ECC enabled, because my servers have ECC RAM, but I've always disabled ECC in the BIOS), but it isn't going to NOT startup if you have ECC RAM, but with ECC disabled.
And so far, I haven't seen ANY discernable evidence that suggests that ECC is an absolute must when running ZFS, and you can SAY that I am wrong, but you will also need to back that statement up with evidence/data.
AlmaFather - Monday, July 28, 2014 - link
Some information:http://forums.freenas.org/index.php?threads/ecc-vs...
Samus - Monday, July 21, 2014 - link
The problem with power saving "green" style drives is the APM is too aggressive. Even Seagate, who doesn't actively manufacture a "green" drive at a hardware level, uses firmware that sets aggressive APM values in many low end and external versions of their drives, including the Barracuda XT.This is a completely unacceptable practice because the drives are effectively self-destructing. Most consumer drives are rated at 250,000 load/unload cycles and I've racked up 90,000 cycles in a matter of MONTHS on drives with heavy IO (seeding torrents, SQL databases, exchange servers, etc)
HDPARM is a tool that you can send SMART commands to a drive and disable APM (by setting the value to 255) overriding the firmware value. At least until the next power cycle...
name99 - Tuesday, July 22, 2014 - link
I don't know if this is the ONLY problem.My most recent (USB3 Seagate 5GB) drive consistently exhibited a strange failure mode where it frequently seemed to disconnect from my Mac. Acting on a hunch I disabled the OSX Energy Saver "Put hard disks to sleep when possible" setting, and the problem went away. (And energy usage hasn't gone up because the Seagate drive puts itself to sleep anyway.)
Now you're welcome to read this as "Apple sux, obviously they screwed up" if you like. I'd disagree with that interpretation given that I've connected dozens of different disks from different vendors to different macs and have never seen this before. What I think is happening is Seagate is not handling a race condition well --- something like "Seagate starts to power down, half-way through it gets a command from OSX to power down, and it mishandles this command and puts itself into some sort of comatose mode that requires power cycling".
I appreciate that disk firmware is hard to write, and that power management is tough. Even so, it's hard not to get angry at what seems like pretty obvious incompetence in the code coupled to an obviously not very demanding test regime.
jay401 - Tuesday, July 22, 2014 - link
> Completely unsurprised here, I've had nothing but bad luck with any of those "intelligent power saving" drives that like to park their heads if you aren't constantly hammering them with I/O.I fixed that the day i bought mine with the wdidle utility. No more excessive head parking, no excessive wear. I've had 3 2TB Greens and 2 3TB Greens with no issues so far (thankfully). Currently running a pair of 4TB Reds, but have not seen any excessive head parking showing up in the SMART data with those.
chekk - Monday, July 21, 2014 - link
Yes, I just test all new drives thoroughly for a month or so before trusting them. My anecdotal evidence across about 50 drives is that they are either DOA, fail in the first month or last for years. But hey, YMMV.icrf - Monday, July 21, 2014 - link
My anecdotal experience is about the same, but I'd extend the early death window a few more months. I don't know that I've gone through 50 drives, but I've definitely seen a couple dozen, and that's the pattern. One year warranty is a bit short for comfort, but I don't know that I care much about 5 years over 3.Guspaz - Tuesday, July 22, 2014 - link
I've had a bunch of 2TB greens in a ZFS server (15 of them) for years and none of them have failed. I expected them to fail, and I designed the setup to tolerate two to four of them failing without data loss, but... nothing.