ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTTricks of the Trade: Transaction Elimination and Frame Buffer Compression
While we have spent some time covering various techniques ARM uses to improve efficiency in Midgard, we wanted to spend a bit more time talking about two specific techniques in general that we find especially cool: transaction elimination and frame buffer compression.
Going back once again to what we said earlier about rendering and power efficiency, any rendering work ARM can eliminate before it’s completed not only improves performance by freeing up resources, but it also frees up power by not having to spend it on said redundant work. This is especially the case for anything that wants to hit system memory, as compared to the on-die caches and memories available to the GPU, system memory is slow and expensive to operate from a power perspective.
For their final two tricks then, having already eliminated as much rendering work as possible through other means, ARM’s last tricks involve minimizing the amount of data from rendered tiles and pixels that needs to hit system memory. The first of these tricks is Transaction Elimination (TE), which is based on the idea that if a scene (or parts of it) do not change, then it makes no sense to spend power and bandwidth rewriting those identical screen portions.
![]()
To accomplish this, ARM relies on their tiling system to break down the scene for them, and from there they can begin comparing tiles that are waiting for finalization (ROP/blending) to the tiles that are already in the frame buffer from the previous frame. Using a simple cyclic redundancy check to compare the tiles, if the tile to be rendered is found to be identical to the tile already there, the tile can be skipped and the memory bandwidth saved. Altogether of all of ARM’s various tricks, this is among the simplest conceptually.
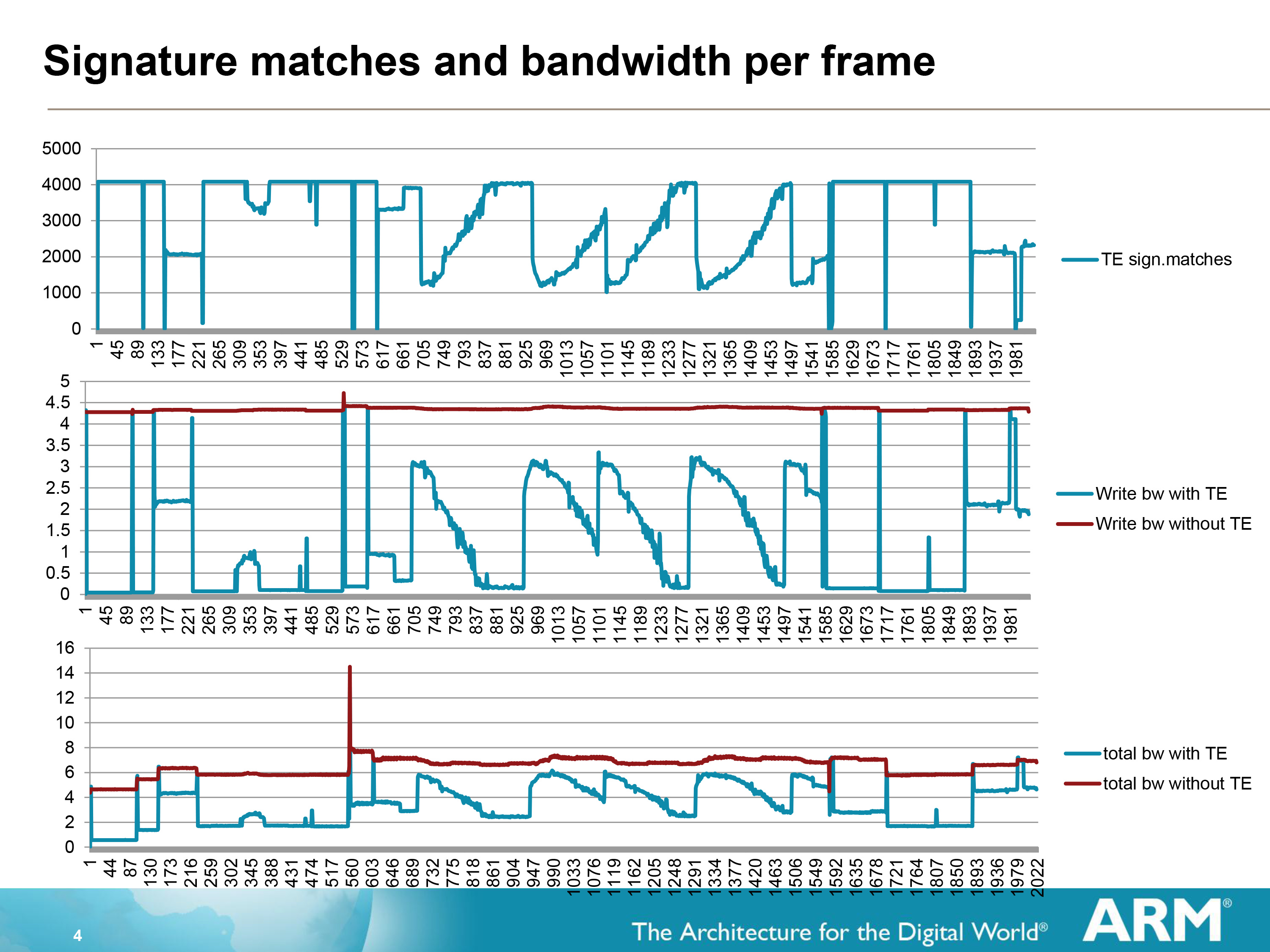
The effectiveness of Transaction Elimination in turn depends on the content. A generally static workload such as a movie will have a high degree of redundancy overall (notably when the camera is not moving), while a game may have many moving elements but will still have redundant elements that can be skipped. As a result ARM can save anywhere between almost nothing and over 99% for a highly static workload, with the average more than offsetting the roughly 1.5% overhead from computing and comparing the CRCs.
Of course Transaction Elimination does have one drawback besides its low overhead, and that is CRC collisions. During a CRC collision a pair of tiles that are different will compute to the same CRC value, and as such Transaction Elimination will consider them identical and throw away the new tile. With a standard CRC value being 64bits, such a collision is rare but not impossible, and indeed will statistically occur sooner or later. In which case Transaction Elimination has no fallback method; it is judge, jury, and executioner as it were, and the new tile will be lost.
As a result Transaction Elimination is interestingly imprecise in a world of precision. When a collision occurs the displayed tile will be wrong, but only for as long as there is a collision, which in turn should only be for 1 frame, or 1/60th of a second.
Moving on, when worse comes to worse and ARM does need to write a new tile, on the Mali-T700 series GPUs they can turn to ARM Frame Buffer Compression (AFBC) to minimize the amount of memory bandwidth they spend on that operation. By using a lossless compression algorithm to write out and store a frame, memory bandwidth is saved on both the writing of the frame and in the reading of it.
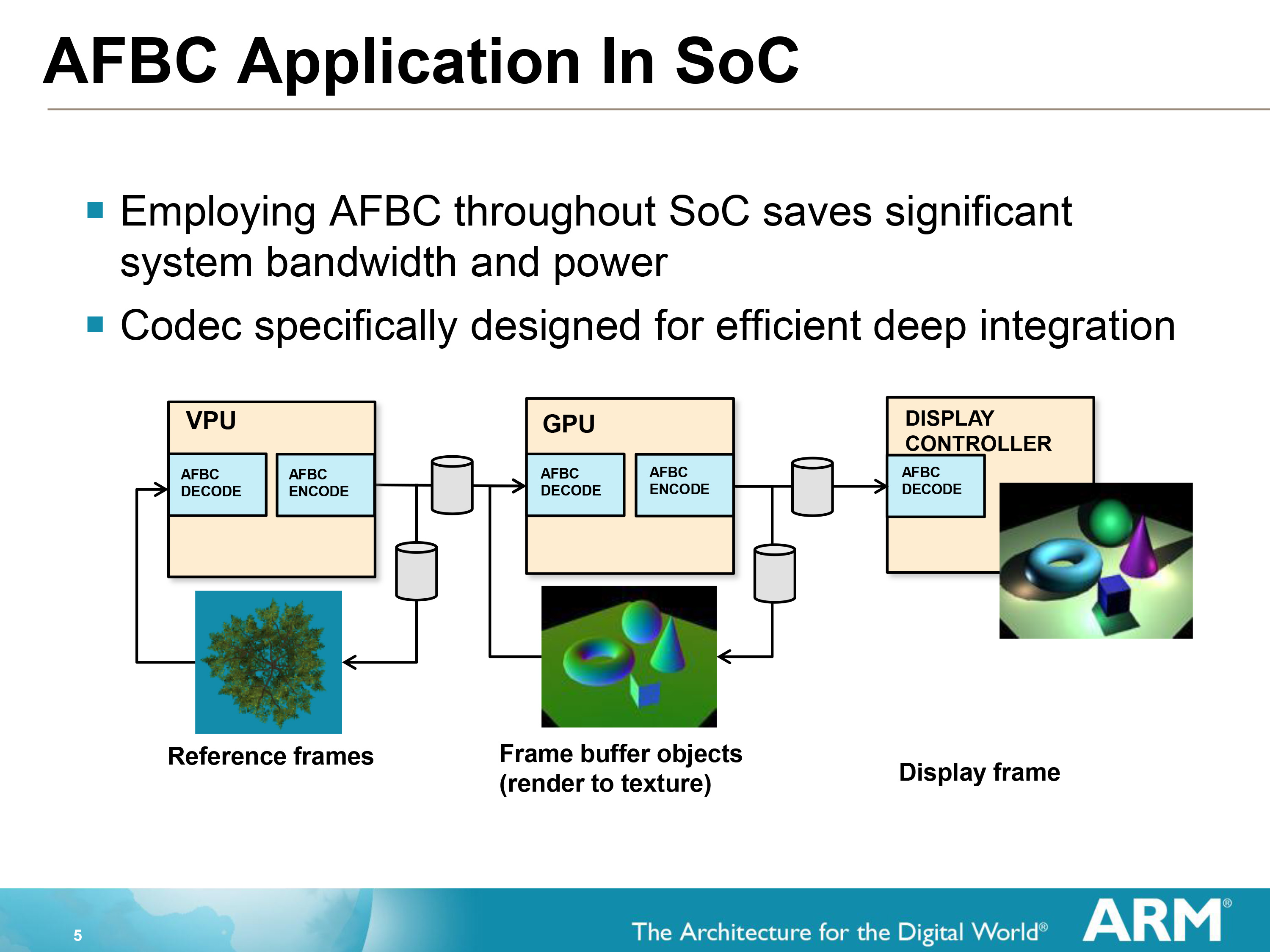
AFBC requires that both the GPU and the Display Controller support the technology, as the frame remains compressed the entire time until decompressed for display/consumption. Interestingly this means that the GPU needs to be able to compress as well as decompress, as it can reuse its own frames either in frame buffer objects (where a frame is rendered to a texture) or in Transaction Elimination. This becomes a secondary vector of saving bandwidth since it results in similar bandwidth savings for the frame even if the frame is never touched by the display controller itself. A similar principle applies to ARM’s video decoders (VPUs) which can use AFBC to compress a frame before shipping it off to the GPU.
On that note, it’s worth pointing out that while AFBC is an ARM technology, for interoperability purposes ARM does license it out to other display controller designers. ARM puts together their own display controllers, but because SoC integrators can use one of many display controllers it’s to ARM’s own benefit that everyone else be able to read AFBC as well as ARM can.








66 Comments
View All Comments
3DPowerFX - Thursday, July 3, 2014 - link
Once again, AnandTech has published a great article! Thanks ARM and AnandTech.Just one point. there is a small mistake in the article about Samsung Exynos 3470 GPU. It's not Mali 450MP but the undead Mali 400MP GPU. Although it would be nice to have the latest one.
Cogman - Thursday, July 3, 2014 - link
On transaction elimination. A movie is actually much worse about being eliminated than anything else. The only saving grace for a movie is the fact that the FPS are often much lower than what the device is natively putting out (so 60fps is a typical display refresh rate whereas movies typically operate at 24->30fps). After that, everything changes right down to the smallest detail. This is the grainy effect that you see in movies.For games, there could be some benefit assuming the game isn't a high action one. The biggest win will be still images (90% of what these displays are going to be displaying).
EdvardS - Thursday, July 3, 2014 - link
Movies are not actually that bad. Remember that videos we watch on our devices have already been compressed with lossy algorithms looking for temporal resemblance, which seems to boost the transaction elimination efficiency as well.BMNify - Thursday, July 3, 2014 - link
gem did a writup , but i cant find it now !, but take a look here as regards transaction elimination http://community.arm.com/groups/arm-mali-graphics/...BTW "the grainy effect that you see in movies" have absolutely nothing to do with frame rate
its put there (as in artificially) by the post processing due to the fact today everyone's using 8bit per pixel as in Rec. 709 (HDTV) color space that produces banding and other visible anomalies not the new official Rec. 2020 (UHDTV/UHD-1/UHD-2) real 10bit/12bit color space we will see soon.
tuxRoller - Thursday, July 3, 2014 - link
Consider asking red hat's rob clark. He's been reverse engineering the adreno arch (his driver, freedreno (https://github.com/freedreno/freedreno/wiki) however, is not a reverse engineered adreno driver) for a few years now and can almost certainly give you at least that much info.His blog is at http://bloggingthemonkey.blogspot.com, and he's a super nice guy.
jwcalla - Friday, July 4, 2014 - link
Qualcomm is a really closed company. They just did a massive DCMA takedown on GitHub: https://github.com/github/dmca/blob/master/2014-07...Their software side isn't that great either.
tuxRoller - Friday, July 4, 2014 - link
I'm not sure why this is addressed to me. Although I expect AT will ignore what I've written so as not to upset their corporate friends, what I suggested is what they should do if they are really interested in the tech.What's strange to me is that they did something similar with their analysis of Cyclone to what I'm suggesting they do, except in the Qualcomm case the work is done by someone else.
Death666Angel - Thursday, July 3, 2014 - link
Awesome to see this here! I hope the Adreno team will follow suite soon and lay their doubts to rest."LG’s Viewty" Holy shit, that way my 2nd ever phone (after my first flip phone got broken when I rammed a car with my bike). That thing was pretty bad all in all. But the slow motion camera was great for its time! :D It broke too while I was in a fight, but that was the last one. Touch Pro 2, Galaxy S2, Galaxy Nexus and LG G2 all working fine till this day. :D
Willardjuice - Thursday, July 3, 2014 - link
"From a sales perspective this means ARM can offer the CPU and GPU designs together in a bundle, but perhaps more importantly it means they have the capability design the two in concert with each other, being in the position of the sole creator of the ARM ISA."lol, the bundle aspect is far more important for ARM gpu sales. ;)
skiboysteve - Thursday, July 3, 2014 - link
Truth. Basically makes it so a competitor needs to show a significant performance, power, feature, or cost difference before it's worth an integrator investing in breaking apart the bundle