ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTTricks of the Trade: Transaction Elimination and Frame Buffer Compression
While we have spent some time covering various techniques ARM uses to improve efficiency in Midgard, we wanted to spend a bit more time talking about two specific techniques in general that we find especially cool: transaction elimination and frame buffer compression.
Going back once again to what we said earlier about rendering and power efficiency, any rendering work ARM can eliminate before it’s completed not only improves performance by freeing up resources, but it also frees up power by not having to spend it on said redundant work. This is especially the case for anything that wants to hit system memory, as compared to the on-die caches and memories available to the GPU, system memory is slow and expensive to operate from a power perspective.
For their final two tricks then, having already eliminated as much rendering work as possible through other means, ARM’s last tricks involve minimizing the amount of data from rendered tiles and pixels that needs to hit system memory. The first of these tricks is Transaction Elimination (TE), which is based on the idea that if a scene (or parts of it) do not change, then it makes no sense to spend power and bandwidth rewriting those identical screen portions.
![]()
To accomplish this, ARM relies on their tiling system to break down the scene for them, and from there they can begin comparing tiles that are waiting for finalization (ROP/blending) to the tiles that are already in the frame buffer from the previous frame. Using a simple cyclic redundancy check to compare the tiles, if the tile to be rendered is found to be identical to the tile already there, the tile can be skipped and the memory bandwidth saved. Altogether of all of ARM’s various tricks, this is among the simplest conceptually.
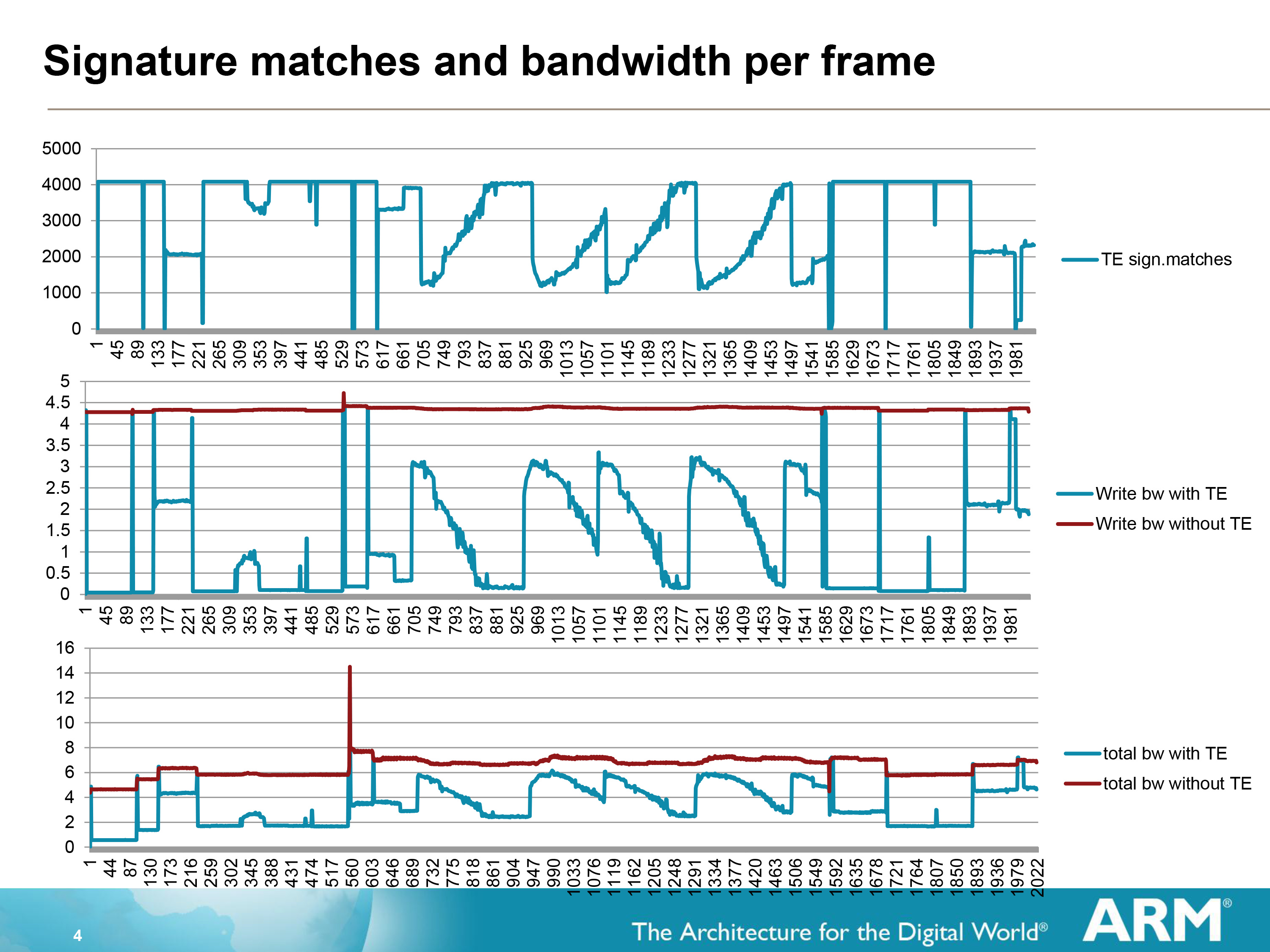
The effectiveness of Transaction Elimination in turn depends on the content. A generally static workload such as a movie will have a high degree of redundancy overall (notably when the camera is not moving), while a game may have many moving elements but will still have redundant elements that can be skipped. As a result ARM can save anywhere between almost nothing and over 99% for a highly static workload, with the average more than offsetting the roughly 1.5% overhead from computing and comparing the CRCs.
Of course Transaction Elimination does have one drawback besides its low overhead, and that is CRC collisions. During a CRC collision a pair of tiles that are different will compute to the same CRC value, and as such Transaction Elimination will consider them identical and throw away the new tile. With a standard CRC value being 64bits, such a collision is rare but not impossible, and indeed will statistically occur sooner or later. In which case Transaction Elimination has no fallback method; it is judge, jury, and executioner as it were, and the new tile will be lost.
As a result Transaction Elimination is interestingly imprecise in a world of precision. When a collision occurs the displayed tile will be wrong, but only for as long as there is a collision, which in turn should only be for 1 frame, or 1/60th of a second.
Moving on, when worse comes to worse and ARM does need to write a new tile, on the Mali-T700 series GPUs they can turn to ARM Frame Buffer Compression (AFBC) to minimize the amount of memory bandwidth they spend on that operation. By using a lossless compression algorithm to write out and store a frame, memory bandwidth is saved on both the writing of the frame and in the reading of it.
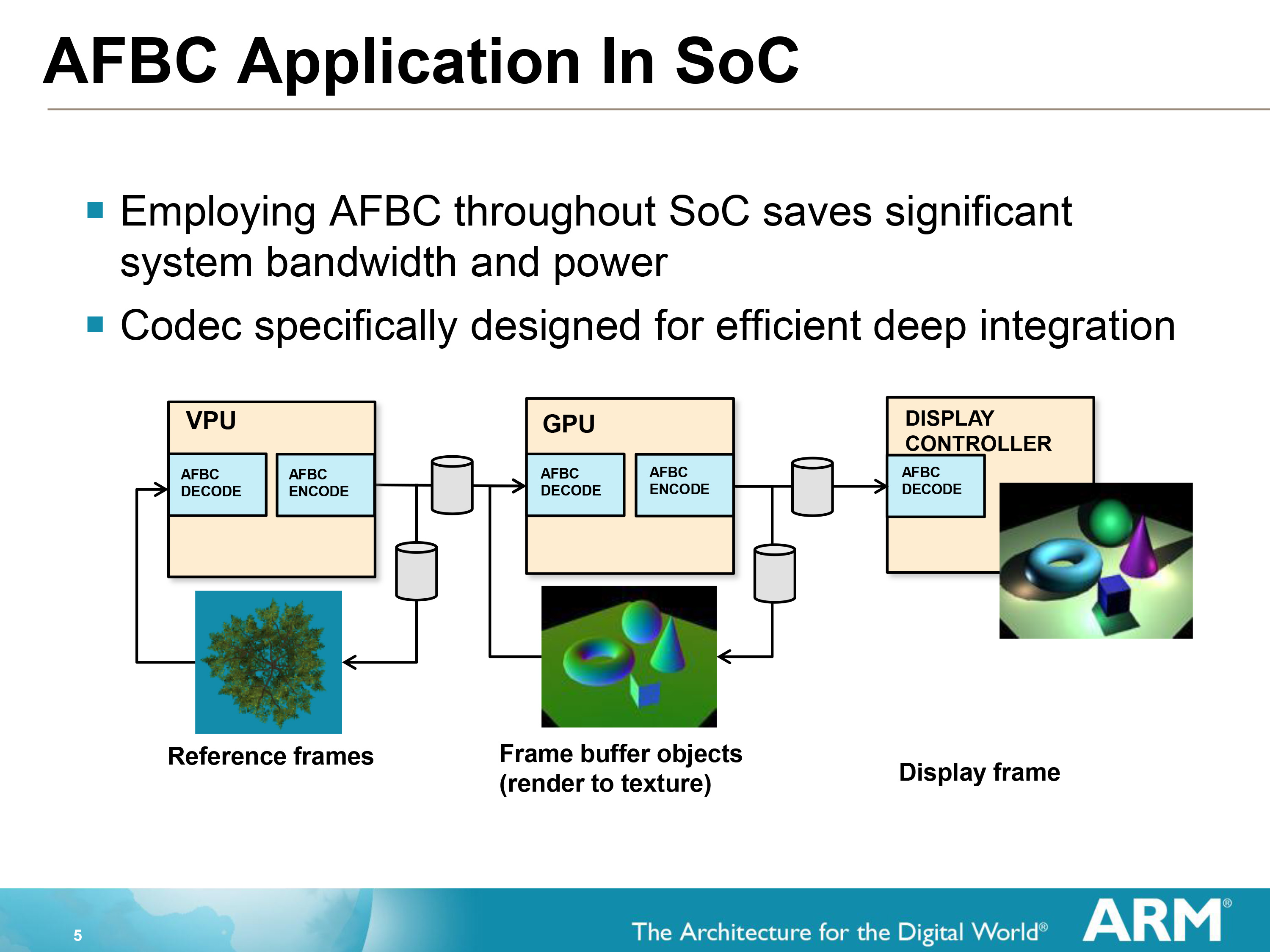
AFBC requires that both the GPU and the Display Controller support the technology, as the frame remains compressed the entire time until decompressed for display/consumption. Interestingly this means that the GPU needs to be able to compress as well as decompress, as it can reuse its own frames either in frame buffer objects (where a frame is rendered to a texture) or in Transaction Elimination. This becomes a secondary vector of saving bandwidth since it results in similar bandwidth savings for the frame even if the frame is never touched by the display controller itself. A similar principle applies to ARM’s video decoders (VPUs) which can use AFBC to compress a frame before shipping it off to the GPU.
On that note, it’s worth pointing out that while AFBC is an ARM technology, for interoperability purposes ARM does license it out to other display controller designers. ARM puts together their own display controllers, but because SoC integrators can use one of many display controllers it’s to ARM’s own benefit that everyone else be able to read AFBC as well as ARM can.








66 Comments
View All Comments
toyotabedzrock - Friday, July 4, 2014 - link
Didn't imagine also buy from ATI? Maybe that is why they are concerned with patents?Kevin G - Saturday, July 5, 2014 - link
There likely is a cross licensing agreement in place. Literally to build any modern GPU a company has to cross license patents. It works out to be zero sum in that money isn't exchanged but one company can use the other's patents (and future patents) royalty free.This also puts a rather high barrier to entry in the market.
nolaviz - Thursday, July 3, 2014 - link
Ah, the history... I led the integration of MALI55 into Zoran's APPROACH-5C. Sweet memories :)skiboysteve - Thursday, July 3, 2014 - link
Very interesting. Complete 100% opposite of the AMD architecture.Also, the fact that they can power down shader cores and even individual ALUs makes this pure ILP and zero TLP architecture really shine. Because the compiler only needs to optimize work on an ALU level.... Not on a shader or wavefront level. So then based upon demand they just feed more or less of these ALU-optomized-packets of work into the GPU and power down the rest of the ALUs. It makes complete sense. Make each ALU independent, compile work on a per ALU basis, then scale your ALU utilization at run time... And also scale your chip portfolio on ALU count. Perfect scalability in price, performance and power combined with straightforward driver work.
Awesome!
rootheday - Thursday, July 3, 2014 - link
Transaction Elimination might work for "render to texture", where the texture is then used later in the scene, but it doesn't make sense to me for the final render target that is shown on the screen.. Typically your final render target is part of a swap chain with 2 or 3 different buffers. So the CRC computed for a tile in Frame N would need to match the CRC for frame N-2 (or maybe N-3), not N-1.EdvardS - Thursday, July 3, 2014 - link
So each buffer has its own CRC buddy attached to it - problem solved :-) Longer buffer chains just reduces you temporal coherency a bit.hexgrid - Thursday, July 3, 2014 - link
Relying on a 32bit hash for transaction elimination is a very bad idea. Assuming a normal distribution of hash results, the Birthday Paradox means you've got a better than 50% chance of collision if you have more than ~5000 items being hashed. The compartmentalized comparisons (it looks like they only compare against the same tile) means the collision rate will be lower, but there will be collisions, and in some cases they will look terrible.If there's a glitch, there's an excellent chance it will persist for a while. For example, let's say I'm bringing up a "pause" menu. If the title overlay of the pause menu happens to hash to the same value as the background that it replaced, that one tile of the pause menu title won't appear. Next frame, it still won't appear, because again the hash value hasn't changed. Until something happens to actually change the title or make it disappear, the glitch will persist.
The "fix" will be to do GUI overlays in translucency and keep the background animating somehow to prevent cache misses from sticking around, but it's an ugly hardware hack that will force software workarounds.
EdvardS - Thursday, July 3, 2014 - link
What if the CRC is 64 bit for each small tile? Quite overkill and very hard to break.mkozakewich - Sunday, July 6, 2014 - link
If the pause screen fades in, wouldn't that change the image data enough that it would generate entirely different CRCs for each frame until the animation ended?At any rate, my rule of thumb would be that if it doesn't happen more often than a keyframe is dropped in a video, it'll be fine.
Krysto - Thursday, July 3, 2014 - link
I'd like you guys to do more 30x GFX loops, that how whether these GPU's only prop up high numbers at first, but then quickly get throttled. From what I noticed Imagination is the only one that doesn't throttle in that test. But I'm curious to see if K1 and T760 do.