The AMD FX (Bulldozer) Scheduling Hotfixes Tested
by Anand Lal Shimpi on January 27, 2012 12:47 PM ESTMixed Workloads: Mild Gains
The one thing all of the following benchmarks have in common is they feature more varied CPU utilization. With periods of heavy single and all core utilization, we also see times when these benchmarks use more than one core but fewer than all.
SYSMark has always been a fairly lightly threaded test. While there are definite gains seen when going from 2 to 4 cores, this is hardly a heavily threaded test. The performance impact of the hotfixes is negligible in the overall performance result or across the individual benchmark suites however:
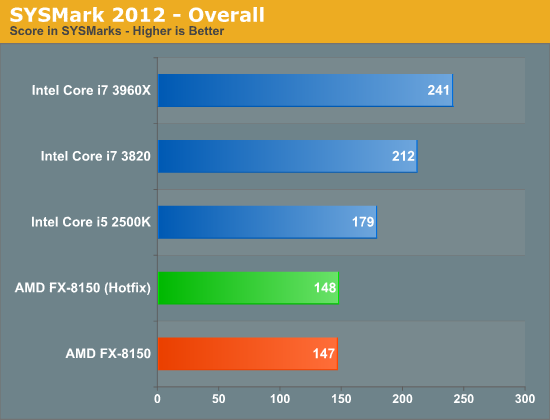
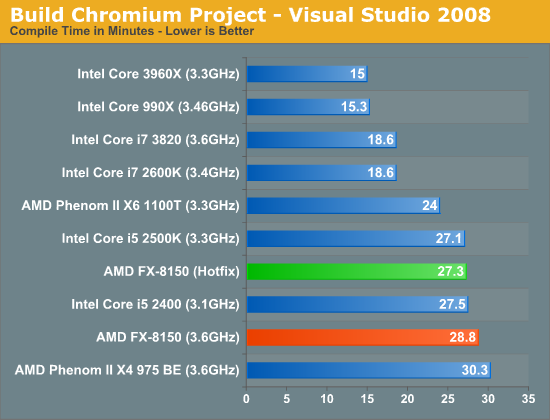
Our Visual Studio 2008 compile test is heavily threaded for the most part, however the beginning of the build process uses a fraction of the total available cores. The hotfixes show a reasonable impact on performance here (~5%):
The first pass of our x264 transcode benchmark doesn't use all available cores but it is more than just single threaded:

Performance goes up but only by ~2% here. As expected, the second pass which consumes all cores in the system remains unchanged:

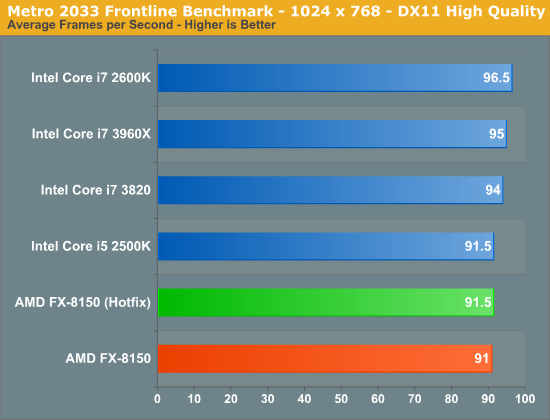
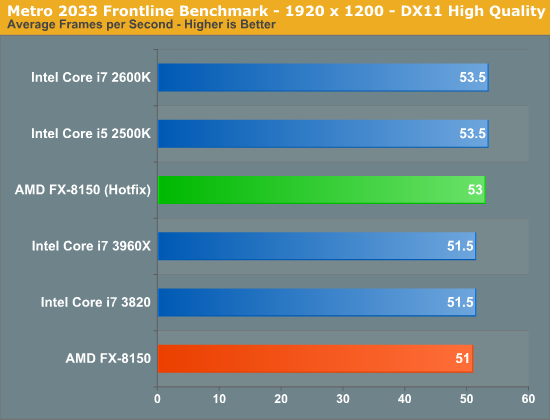
Games are another place we can look for performance improvements as it's rare to see consistent, many-core utilization while playing a modern title on a high-end CPU. Metro 2033 is fairly GPU bound and thus we don't see much of an improvement, although for whatever reason the 51.5 fps ceiling at 19x12 is broken by the hotfixes.
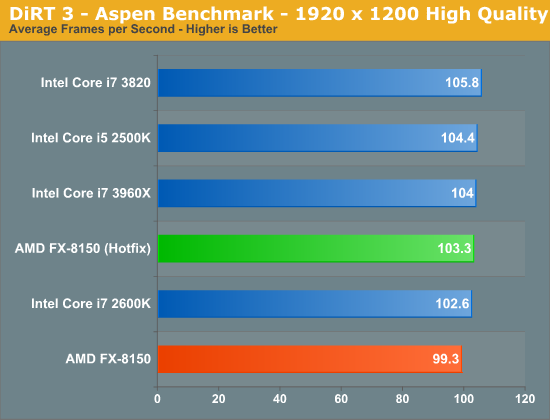
DiRT 3 shows a 5% performance gain from the hotfixes. The improvement isn't enough to really change the standings here, but it's an example of a larger performance gain.

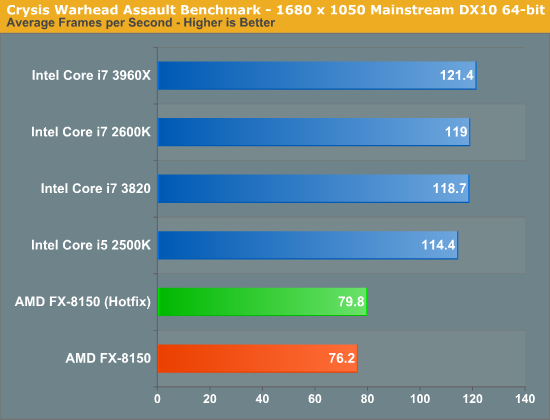
Crysis Warhead mirrors the roughly 5% gain we saw in DiRT 3:
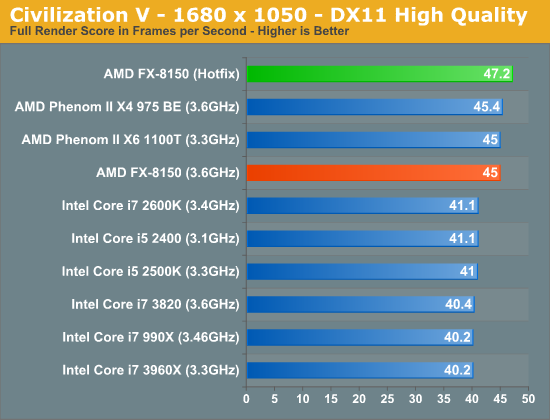
Civilization V's CPU bound no render results show no gains, which is to be expected. But looking at the average frame rate during the simulation we see a 4.9% increase in performance.









79 Comments
View All Comments
wumpus - Friday, January 27, 2012 - link
I'd have to believe that any CPU with SMT enabled will benefit. That is, unless they already have this feature. Of course, Intel has been shipping SMT processors since P4. I'd like to believe that microsoft simply flipped whatever switch to treat bulldozer cores as SMT cores, but I don't have enough faith in microsoft's scheduling to believe they ever got it right.hansmuff - Friday, January 27, 2012 - link
At least Windows 7 (haven't tested anything else) schedules threads properly on Sandy Bridge. HT only comes into play once all 4 cores are loaded.tipoo - Friday, January 27, 2012 - link
Windows already has intelligent behaviour for Hyperthreading. I don't think this will change anything on the Intel side.silet1911 - Wednesday, February 1, 2012 - link
Yes, a website called Jagatreview have review a 2500+patch and there is a small performance increasehttp://www.jagatreview.com/2012/01/amd-fx-8120-vs-...
tk11 - Friday, January 27, 2012 - link
Even if if a scheduler did take the time to figure out when threads shared a significant number of recent memory accesses would that be enough information to determine that the thread would perform optimally on the same module as a related thread rather than an unused module?Also... Wouldn't running code that performed "intelligent core/module scheduling based on the memory addresses touched by a thread" negatively impact performance far more than any gains realized by scheduling threads on cores that are merely suspected to be more optimally suited to running each particular thread?
eastyy123 - Friday, January 27, 2012 - link
could some explain the whole module/core thing to me pleasei always assumed a core was basically like a whole processor shrunk onto a die is that basically right ?
and how does the amd modules differ ?
KonradK - Friday, January 27, 2012 - link
Long sory short:Bulldozer's module consist 2 integer cores and 1 floating point (FPU) core.
KonradK - Friday, January 27, 2012 - link
"Story" no "sory"I'm sorry...
Ammaross - Friday, January 27, 2012 - link
"Bulldozer's module consist 2 integer cores and 1 floating point (FPU) core."However, the 1 FPU core can be used as two single floating point cores or a single double double floating point core, so it depends on the floating point data running through it.
KonradK - Friday, January 27, 2012 - link
Not sure what you are supposing.Precision is the same, regardless of fact whether one or two threads are executed by FPU core. There are single or double precision FPU instructions, but aech thread can use any of them.
However if you mean single or double performance:
If two FPU threads will run on the same module each of them will have half of performance in comparision tothe same two FPU threads running on separate modules.
Just in first case one FPU is shared by two threads.
And it is whole point in the hotfixes - avoiding such situation as long this is possible.