AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Theoreticals & Tessellation
From a rendering perspective one of the most interesting things AMD did with Tahiti was what they didn’t do: they didn’t add more ROPs, they didn’t add more geometry engines. And yet based on our game performance they’ve clearly improved on their performance in those situations by making more efficient use of the hardware they do have.
So we wanted to take a quick look at synthetic performance to see what these tools had to say about AMD’s changes. We’ve included the numbers for every other GPU in our lineup as a reference point, but we would strongly suggest against reading into them too much. AMD versus AMD is sometimes relevant to real world performance; AMD versus NVIDIA rarely is.

We’ll start with 3DMark Vantage and its color fill test. This is basically a ROP test that attempts to have a GPU’s ROPs blend as many pixels as it can. Theoretically AMD can do 32 color operations per clock on Tahiti, which at 925MHz for 7970 means the theoretical limit is 29.6Gpix/sec; not that any architecture is ever that efficient. In practice 7970 hits 13.33Gpix/sec, which is still well short of the theoretical maximum, but pay close attention to 7970’s performance relative to 6970. Even with the same number of ROPs and a similar theoretical performance limit (29.6 vs 28.16), 7970 is pushing 51% more pixels than 6970 is.
In designing Tahiti AMD said that they didn’t need more ROPs they just needed more efficient ROPs, and it looks like they’ve delivered on this. It’s not clear whether this is the limit for efficiency or if AMD can squeeze more out of their ROPs in future designs, but this definitely helps to prove that there’s more to graphics rendering than a large number of functional units.
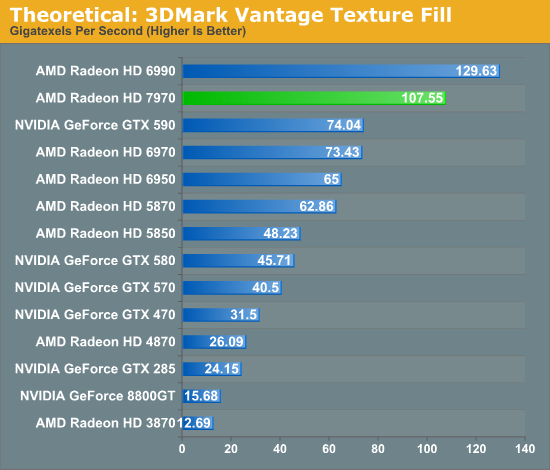
Our other 3DMark synthetic benchmark is the 3DMark Vantage Texture Blend test, which measures how quickly a GPU can blend multiple FP16 textures. This is more synthetic than most tests because FP16 textures aren’t widely used, but it’s a consistent benchmark.
The theoretical performance improvement from 6970 to 7970 is 40% - 33% more texture units operating at a 5% higher clockspeed. In practice the 7970 exceeds that improvement by increasing texture performance by 46%, meaning the 7970 has benefitted from more than the increase in texture units. Most likely the new cache architecture has further improved the efficiency of the texture units, although the 3DMark texture set is not particularly large.
Moving on, we also wanted to take a look at tessellation. AMD did not increase the theoretical geometry performance of Tahiti as compared to Cayman – both top out at 2 triangles per clock – but AMD has put a lot of effort into improving the efficiency of Tahiti’s geometry units as we’ve seen reflected in our game benchmarks.
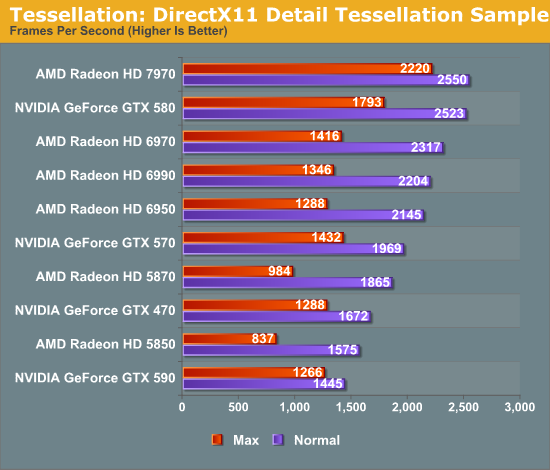
Our first tessellation benchmark is the traditional Detail Tessellation sample program from the DirectX SDK. Here we’re looking at tessellation performance as a product of the framerate, testing at tessellation factors 7 (normal) and 15 (max). Traditionally this is a test that has been rather balanced at normal tessellation levels, while NVIDIA cards with their superior geometry throughput have been the top performers at maximum tessellation levels. So it’s all the more interesting when we’ve seen the tables turned; the 7970 is merely competitive with the GTX 580 at normal tessellation levels, but now it’s ahead of the GTX 580 by 24%. More significantly however the 7970 is ahead of the 6970 by 57%.
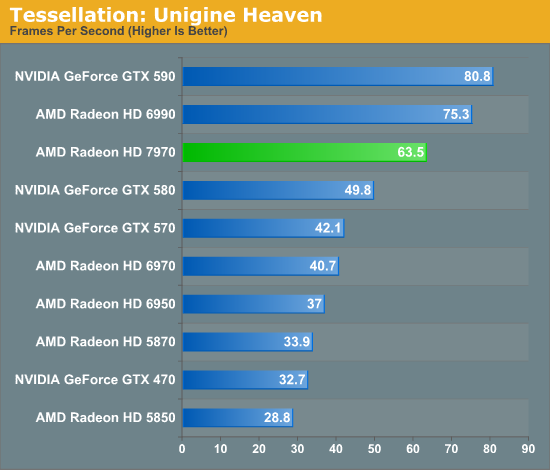
Our second tessellation benchmark is Unigine Heaven, a benchmark that straddles the line between a synthetic benchmark and a real-world benchmark, as the engine is licensed but no notable DX11 games have been produced using it yet. In any case the Heaven benchmark is notable for its heavy use of tessellation, which means it’s largely a proxy test for tessellation performance.
As with the Detail Tessellation sample program, Heaven shows significant gains for the 7970 versus the 6970, with the 7970 leading by 56%. Meanwhile it leads the GTX 580 by 27%, which is actually slightly better than what we saw under the more “pure” Detail Tessellation sample. Between these two benchmarks it’s clear that AMD’s tessellation efficiency improvements are quite real, and that with Tahiti AMD can deliver much better tessellation performance than Cayman even at virtually the same theoretical triangle throughput rate.
Of course one has to wonder what NVIDIA will have in store for Kepler next year. Their current Fermi design seems to scale well with additional geometry units, but if Tahiti is anything to go by, there’s a great deal to be gained just by focusing on efficiency. NVIDIA has prided themselves on their geometry performance since before GF100 even shipped, so it will be interesting if they have anything in store to hold on to that distinction.








292 Comments
View All Comments
mczak - Thursday, December 22, 2011 - link
Oh yes _for this test_ certainly 32 ROPs are sufficient (FWIW it uses FP16 render target with alpha blend). But these things have caches (which they'll never hit in the vantage fill test, but certainly not everything will have zero cache hits), and even more important than color output are the z tests ROPs are doing (which also consume bandwidth, but z buffers are highly compressed these days).You can't really say if 32 ROPs are sufficient, nor if they are somehow more efficient judged by this vantage test (as just about ANY card from nvidia or amd hits bandwidth constraints in that particular test long before hitting ROP limits).
Typically it would make sense to scale ROPs along with memory bandwidth, since even while it doesn't need to be as bad as in the color fill test they are indeed a major bandwidth eater. But apparently AMD disagreed and felt 32 ROPs are enough (well for compute that's certainly true...)
cactusdog - Thursday, December 22, 2011 - link
The card looks great, undisputed win for AMD. Fan noise is the only negative, I was hoping for better performance out the new gen cooler but theres always non-reference models for silent gaming.Temps are good too so theres probably room to turn the fan speed down a little.
rimscrimley - Thursday, December 22, 2011 - link
Terrific review. Very excited about the new test. I'm happy this card pushes the envelope, but doesn't make me regret my recent 580 purchase. As long as AMD is producing competitive cards -- and when the price settles on this to parity with the 580, this will be the market winner -- the technology benefits. Cheers!nerfed08 - Thursday, December 22, 2011 - link
Good read. By the way there is a typo in final words.faster and cooler al at once
Anand Lal Shimpi - Thursday, December 22, 2011 - link
Fixed, thank you :)Take care,
Anand
hechacker1 - Thursday, December 22, 2011 - link
I think most telling is the minimum FPS results. The 7970 is 30-45% ahead of the previous generation; in a "worse case" situation were the GPU can't keep up or the program is poorly coded.Of course they are catching up with Nvidia's already pretty good minimum FPS, but I am glad to see the improvement, because nothing is worse than stuttering during a fasted pace FPS. I can live with 60fps, or even 30fps, as long as it's consistent.
So I bet the micro-stutter problem will also be improved in SLI with this architecture.
jgarcows - Thursday, December 22, 2011 - link
While I know the bitcoin craze has died down, I would be interested to see it included in the compute benchmarks. In the past, AMD has consistently outperformed nVidia in bitcoin work, it would also be interesting to see Anandtech's take as to why, and to see if the new architecture changes that.dcollins - Thursday, December 22, 2011 - link
This architecture will most likely be a step backwards in terms of bitcoin mining performance. In the GCN architecture article, Anand mentioned that buteforce hashing was one area where a VLIW style architecture had an advantage over a SIMD based chip. Bitcoin mining is based on algorithms mathematically equivalent to password hashing. With GCN, AMD is changing the very thing that made their card better miners than Nvidia's chips.The old architecture is superior for "pure," mathematically well defined code while GCN is targeted at "messy," more practical and thus widely applicable code.
wifiwolf - Thursday, December 22, 2011 - link
a bit less than expected, but not really an issue:http://www.tomshardware.co.uk/radeon-hd-7970-bench...
dcollins - Thursday, December 22, 2011 - link
You're looking at a 5% increase in performance for a whole new generation with 35% more compute hardware, increased clock speed and increased power consumption: that's not an improvement, it's a regression. I don't fault AMD for this because Bitcoin mining is a very niche use case, but Crossfire 68x0 cards offer much better performance/watt and performance/$.