AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Compute: The Real Reason for GCN
Moving on from our game tests we’ve now reached the compute benchmark segment of our review. While the gaming performance of the 7970 will have the most immediate ramifications for AMD and the product, it is the compute performance that I believe is the more important metric in the long run. GCN is both a gaming and a compute architecture, and while its gaming pedigree is well defined its real-world compute capabilities still need to be exposed.
With that said, we’re going to open up this section with a rather straightforward statement: the current selection of compute applications for AMD GPUs is extremely poor. This is especially true for anything that would be suitable as a benchmark. Perhaps this is because developers ignored Evergreen and Northern Islands due to their low compute performance, or perhaps this is because developers still haven’t warmed up to OpenCL, but here at the tail end of 2011 there just aren’t very many applications that can make meaningful use of the pure compute capabilities of AMD’s GPUs.
Aggravating this some is that of the applications that can use AMD’s compute capabilities, some of the most popular ones among them have been hand-tuned for AMD’s previous architectures to the point that they simply will not run on Tahiti right now. Folding@Home, FLACC, and a few other candidates we looked into for use as compute benchmarks all fall under this umbrella, and as a result we only have a limited toolset to work with for proving the compute performance of GCN.
So with that out of the way, let’s get started.
Since we just ended with Civilization V as a gaming benchmark, let’s start with Civilization V as a compute benchmark. We’ve seen Civilization V’s performance skyrocket on 7970 and we’ve theorized that it’s due to improvements in compute shader performance, and now we have a chance to prove it.
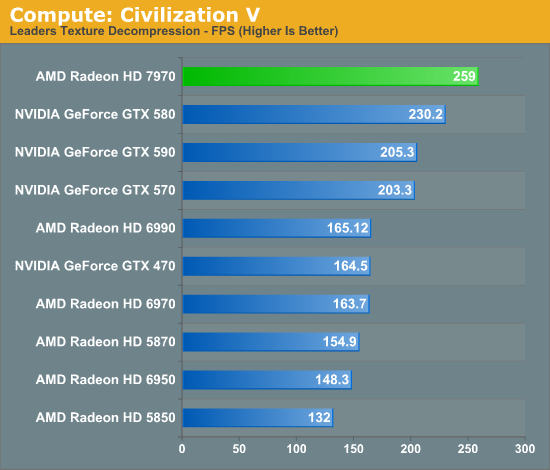
And there’s our proof. Compared to the 6970, the 7970’s performance on this benchmark has jumped up by 58%, and even the previously leading GTX 580 is now beneath the 7970 by 12%. GCN’s compute ambitions are clearly paying off, and in the case of Civilization V it’s even enough to dethrone NVIDIA entirely. If you’re AMD there’s not much more you can ask for.
Our next benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. We’re now using a development build from the version 2.0 branch, and we’ve moved on to a more complex scene that hopefully will provide a greater challenge to our GPUs.

Again the 7970 does incredibly well here compared to AMD’s past architectures. AMD already did rather well here even with the limited compute performance of their VLIW4 architecture, and with GCN AMD once again puts their old architectures to shame, and puts NVIDIA to shame too in the process. Among single-GPU cards the GTX 580 is the closest competitor and even then the 7970 leads it by 72%. The story is much the same for the 7970 versus the 6970, where the 7970 leads by 74%. If AMD can continue to deliver on performance gains like these, the GCN is going to be a formidable force in the HPC market when it eventually makes its way there.
For our next benchmark we’re once again looking at compute shader performance, this time through the Fluid simulation sample in the DirectX SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using two of them: a highly optimized grid search that Microsoft based on an earlier CUDA implementation, and an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.

There are many things we can gather from this data, but let’s address the most important conclusions first. Regardless of the algorithm used, AMD’s VLIW4 and VLIW5 architectures had relatively poor performance in this simulation; NVIDIA meanwhile has strong performance with the grid search algorithm, but more limited performance with the shared memory algorithm. 7970 consequently manages to blow away the 6970 in all cases, and while it can’t beat the GTX 580 at the grid search algorithm it is 45% faster than the GTX 580 with the shared memory algorithm.
With GCN AMD put a lot of effort into compute performance, not only with respect to their shader/compute hardware, but with the caches and shared memory to feed that hardware. I don’t believe we have enough data to say anything definitive about how Tahiti/GCN’s cache compares to Fermi’s cache, this benchmark does raise the possibility that GCN cache design is better suited for less than optimal brute force algorithms. In which case what this means for AMD could be huge, as it could open up new HPC market opportunities for them that NVIDIA could never access, and certainly it could help AMD steal market share from NVIDIA.
Moving on to our final two benchmarks, we’ve gone spelunking through AMD’s OpenCL archive to dig up a couple more compute scenarios to use to evaluate GCN. The first of these is AESEncryptDecrypt, an OpenCL AES encryption routine that AES encrypts/decrypts an 8K x 8K pixel square image file. The results of this benchmark are the average time to encrypt the image over a number of iterations of the AES cypher.

We went into the AMD OpenCL sample archives knowing that the projects in it were likely already well suited for AMD’s previous architectures, and there is definitely a degree of that in our results. The 6970 already performs decently in this benchmark and ultimately the GTX 580 is the top competitor. However the 7970 still manages to improve on the 6970 by a sizable degree, and accomplishes this encryption task in only 65% the time. Meanwhile compared to the GTX 580 it trails by roughly 12%, which shows that if nothing else Fermi and GCN are going to have their own architectural strengths and weaknesses, although there’s obviously some room for improvement.
One interesting fact we gathered from this compute benchmark is that it benefitted from the increase in bandwidth offered by PCI Express 3.0. With PCIe 3.0 the 7970 improves by about 10%, showcasing just how important transport bandwidth is for some compute tasks. Ultimately we’ll reach a point where even games will be able to take full advantage of PCIe 3.0, but for right now it’s the compute uses that will benefit the most.
Our final benchmark also comes from the AMD OpenCL archives, and it’s a variant of the Monte Carlo method implemented in OpenCL. Here we’re timing how long it takes to execute a 400 step simulation.

For our final benchmark the 7970 once again takes the lead. The rest of the Radeon pack is close behind so GCN isn’t providing an immense benefit here, but AMD still improves upon the 6970 by 14%. Meanwhile the lead over the GTX 580 is larger at 33%.
Ultimately from these benchmarks it’s clear that AMD is capable of delivering on at least some of the theoretical potential for compute performance that GCN brings to the table. Not unlike gaming performance this is often going to depend on the task at hand, but the performance here proves that in the right scenario Tahiti is a very capable compute GPU. Will it be enough to make a run at NVIDIA’s domination with Tesla? At this point it’s too early to tell, but the potential is there, which is much more than we could say about VLIW4.








292 Comments
View All Comments
Ananke - Thursday, December 22, 2011 - link
"The 7970 leads the 5870 by 50-60% here and in a number of other games"...and as I see it also carries 500-600% of price premium over the 5870.Meh, this is so so priced for a FireGL card, but very badly placed for a consumer market. Regardless, CUDA is getting more open meanwhile. AMD is still several generations/years behind in the HPC market and marketing a product above the NVidia price targets will not help AMD to make it popular.
Having say so, I am using ATI cards for gaming for several years already, and I am very pleased with their IQ and performance. I have always pre-purchased my ATI cards... What I am missing though is teh promised and never materialized consumer level software that can utilize its calculation ability, aka CyberLink and other video transcoders. If it was not for the naughty Nvidia power draw in the 5th series, I would've gone green to have CUDA. Hence, considering SO MUCH MONEY, I am waiting at least 6 months from now to see what the prices will be for the both new contenders in next GPU architectures :).
Dangerous_Dave - Thursday, December 22, 2011 - link
Seems like AMD can't do anything right these days. Bulldozer was designed for a world that doesn't exist, and now we have this new GPU stinking up the place. I'm sorry but @28nm you have double the transistors per area compared with @40nm, yet the performance is only 30% better for a chip that is virtually the same size! It should be at least twice as far ahead of the 6970 as that, even on immature drivers. As it stands, AMD @ 28nm is only just ahead of Nvidia @ 40nm as far as minimums go (the only thing that matters).I shudder to think how badly AMD is going to get destroyed when Nvidia release their 28nm GPU.
Finally - Friday, December 23, 2011 - link
I shudder to think how badly one Nvidia fanboy's ego is going to get scratched if team red released a better GPU and his favourite team has nothing to offer.Oh... they did?
CeriseCogburn - Thursday, March 8, 2012 - link
We have to let amd "go first" now since they have been so on the brink of bankruptcy collapse for so long that they've had to sell off most of their assets... and refinance by AbuDhabi oil money...I think it's nice our laws and global economy puts pressure on the big winners to not utterly crush the underdogs...
Really, if amd makes another fail it might be the last one before collapse and "restructuring" and frankly not many of us want to see that...
They already made the "last move" a dying company does and slashed with the ax at their people...
If the amd fans didn't constantly demand they be given a few dollars off all the time, amd might not be failing - I mean think about it - a near constant loss, because the excessive demand for price vs perf vs the enemy is all the radeon fans claim to care about.
It would be better for us all if the radeon fans dropped the constant $ complaints and just manned up and supported AMD as real fans, with their pocketbooks... instead of driving their favorite toward bankruptcy and cooked books filled with red ink...
Dangerous_Dave - Thursday, December 22, 2011 - link
On reflection this card is even worse than my initial analysis. For 3.4billion transistors AMD could have done no research at all and simply integrated two 6870s onto a single die (a la 5870 vs 4870) and ramped up the clock speed to somewhere over 1Ghz (since 28nm would have easily allowed that). This would have produced performance similar to a 6990, and far in excess of the 7970.Instead we've done a lot of research and spent 4.1billion transistors creating a card that is far worse than a 6990!
That's the value of AMD's creative thinking.
cknobman - Thursday, December 22, 2011 - link
The sad part is your likely too stupid to realize just how idiotic your post sounds.They introduced a new architecture that facilitates much better compute performance as well as giving more gaming performance.
Did you read the article and look at the compute benchmarks or did you just flip through the game benchmark pages and look at numbers without reading?
Zingam - Thursday, December 22, 2011 - link
Or maybe you just don't realize that they've added another 2 billion transistors for minimal graphics performance increase over the previous generation.That's almost as if you buy a new generation BMW that has instead 300 hp, 600hp but is not able to drag a bigger trailer.
The only benefit for you would be that you can brag that you've just got the most expensive and useless car available.
Finally - Friday, December 23, 2011 - link
Rule 1A:The frequency of a car pseudoanalogy to explain a technical concept increases with thread length. This will make many people chuckle, as computer people are rarely knowledgeable about vehicular mechanics.
cknobman - Friday, December 23, 2011 - link
Holy sh!t are you not reading and understanding the article and posts here??????????The extra transistors and new architecture were to increase COMPUTE PERFORMANCE as well as graphics.
Think bigger picture here dude not just games. Think of fusion and how general computing and graphics computing will merge into one.
This architecture is much bigger than just being a graphics card for games.
This is AMD's fermi except they did it about 100x better than Nvidia keeping power in check and still having amazing performance.
Plus your looking at probably beta drivers (heck maybe alpha) so there could very will be another 10+% increase in performance once this thing hit retail shelves and gets some driver improvements.
CeriseCogburn - Thursday, March 8, 2012 - link
I see. So when nvidia did it, it was abandoning gamers for 6 months of ripping away and gnawing plus... but now, since it's amd, amd has done it 100X better... and no abandonment...Wow.
I love hypocrisy in it's full raw and massive form - it's an absolute wonder to behold.