AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher: Graphics Core Next
One of the things we’ve seen as a result of the shift from pure graphics GPUs to mixed graphics and compute GPUs is how NVIDIA and AMD go about making their announcements and courting developers. With graphics GPUs there was no great need to discuss products or architectures ahead of time; a few choice developers would get engineering sample hardware a few months early, and everyone else would wait for the actual product launch. With the inclusion of compute capabilities however comes the need to approach launches in a different manner, a more CPU-like manner.
As a result both NVIDIA and AMD have begun revealing their architectures to developers roughly six months before the first products launch. This is very similar to how CPU launches are handled, where the basic principles of an architecture are publically disclosed months in advance. All of this is necessary as the compute (and specifically, HPC) development pipeline is far more focused on optimizing code around a specific architecture in order to maximize performance; whereas graphics development is still fairly abstracted by APIs, compute developers want to get down and dirty, and to do that they need to know as much about new architectures as possible as soon as possible.
It’s for these reasons that AMD announced Graphics Core Next, the fundamental architecture behind AMD’s new GPUs, back in June of this year at the AMD Fusion Developers Summit. There are some implementation and product specific details that we haven’t known until now, and of course very little was revealed about GCN’s graphics capabilities, but otherwise on the compute side AMD is delivering on exactly what they promised 6 months ago.
Since we’ve already covered the fundamentals of GCN in our GCN preview and the Radeon HD 7970 is primarily a gaming product we’re not going to go over GCN in depth here, but I’d encourage you to read our preview to fully understand the intricacies of GCN. But if you’re not interested in that, here’s a quick refresher on GCN with details pertinent to the 7970.
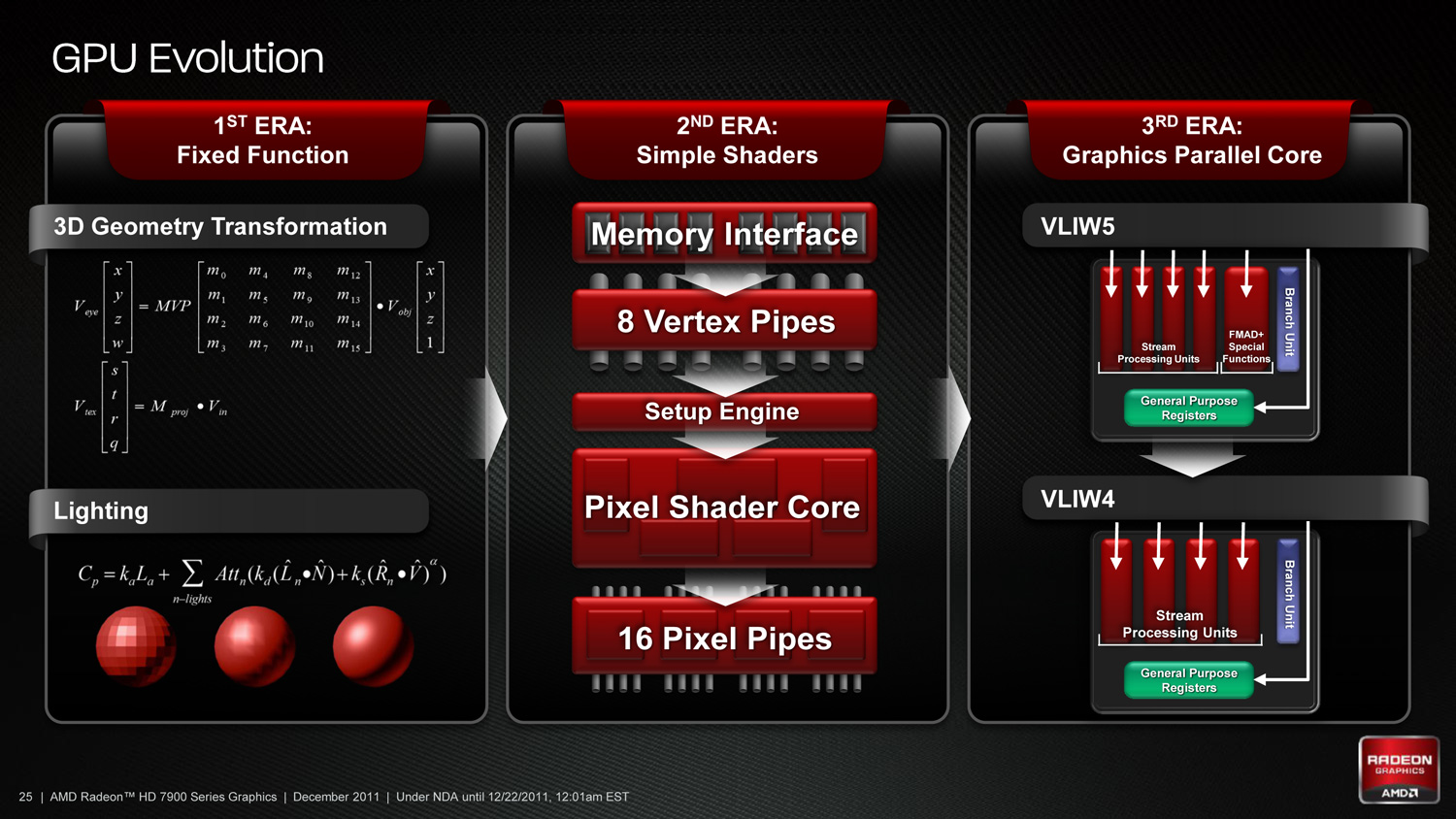
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
Cayman, A VLIW4 Design
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is the situation AMD faced.
But why does AMD want to chase compute in the first place when they already have a successful graphics GPU business? In the long term GCN plays a big part in AMD’s Fusion plans, but in the short term there’s a much simpler answer: because they have to.
In Q3’2011 NVIDIA’s Professional Solutions Business (Quadro + Tesla) had an operating income of 95M on 230M in revenue. Their (consumer) GPU business had an operating income of 146M, but on a much larger 644M in revenue. Professional products have much higher profit margins and it’s a growing business, particularly the GPU computing side. As it stands NVIDIA and AMD may have relatively equal shares of the discrete GPU market, but it’s NVIDIA that makes all the money. For AMD’s GPU business it’s no longer enough to focus only on graphics, they need a larger piece of the professional product market to survive and thrive in the future. And thus we have GCN.








292 Comments
View All Comments
SlyNine - Friday, December 23, 2011 - link
Not really, If Nvidia didn't handicap the CPU version of physx so bad than I'd be fine with it, But Nvidia purposely made the CPU version of phsyx worse totally gimped.CeriseCogburn - Thursday, March 8, 2012 - link
I agree, but that's the way it guy. The amd fans don't care what they and their reviewers pull, and frankly the reviewers would recieve death threats if they didn't comply with amd fanboy demands....So when nvidia had ambient occlusion active for several generations back in a driver add, we were suddenly screamed at that shadows in games suck.... because of course amd didn't have that feature...
That's how the whole thing is set up - amd must be the abused underdog, nvidia must be the evil mis-implementer, until of course amd gets and actual win, or even any win even with 10% IQ performance cheat solidly in place, and any other things like failed AA, poor tessellation performance, no PhysX, etc, etc, etc...
We just must hate nvidia for being better and of course it's all nvidia's fault as they are keeping the poor red radeon down....
If amd radeon has " a perfectly circular algorithm " and it does absolutely nothing and even worse in all games, it is to be praised as an advantage anyway.... and that is still happening to this very day... we ignore shimmer until now, when amd 79xx has a fix for it.... etc..
Dude, that's the way it is man....
Nvidia is the evil, and they're keeping the radeon down...
They throw around money too ( that's unfair as well - and evil ...)
See?
So just pretend anything radeon cannot do that nvidia can doesn't count and is bad, and then make certain nvidia is cut down to radeon level, IQ cheat, no PhysX, AA not turned on, Tesselation turned down, default driver hacks left in place for amd, etc....
Then be sure to cheer when some price perf calc ignoring all the above shows a higher and or lower and card to have a few cents advantage... no free game included, no eyefinity cables... etc.
Just dude... amd = good / nvidia=evil ...
Cool ?
shin0bi272 - Thursday, December 22, 2011 - link
Since I cant edit my comments I have to post this in a second comment instead.According to the released info, Nvidia’s Next Gen flagship GK-100/GK-112 chip which will feature a total f 1024 Shaders (Cuda Cores), 128 texture units (TMUs), 64 ROP’s and a 512-bit GDDR5 Memory interface. The 28nm Next Gen beast would outperform the current Dual chip Geforce GTX590 GPU.
shaboinkin - Thursday, December 22, 2011 - link
Can someone tell me why GPUs tend to have much more transistors than a CPU? I never knew why.Boushh - Thursday, December 22, 2011 - link
Basically it has to do with the difference between programs (= CPU instructions) and graphics (= pixels):A program consists of CPU intructions, many of these instructions depend on output from the previous instruction, Therefore adding more pipelines that can work on the instructions doen't realy work.
A picture consists of pixels, these can be processed in parrallel. So if you double the number of pipelines (= pixels you can work on at the same time), you double the performance.
Therefore CPU's don't have that many transistors. In fact, most transistors in a CPU are in the cache memory not in the actual CPU cores. And GPU's do.
Of course this is hust a simple explenation, the through is much much more complex ;-)
Boushh - Thursday, December 22, 2011 - link
That last line should read:'Of course this is just a simple explanation, the reality is much much more complex'
Reminds me to yet again vote for an EDIT button !!!! Maybe as a christmas present ? PLEASE !!!
shaboinkin - Thursday, December 22, 2011 - link
Interesting...Do you know of a site that goes into the finer details?
Mishera - Wednesday, December 28, 2011 - link
If you're looking for something to specifically answer you question the checking different tech sites. I think realworldtech addressed tis to a degree. Jon Stokes at arstechnica from what I heard wrote some pretty good articles on chip design as well. But if it's a question on chip architecture, reading some textbooks is your best bet. I asked a similar question in the forums before and got some great responses just check my posts.I add to what Boushh said in that for the type of information they process, it's beneficial to have more performance (and not just for graphics). That's why Amd has been pushing to integrate the gpu into the CPU. That's also to a degree show the different philosophy right now between intel and Amd in multicore computing (or the difference between Amd's new gpu architecture vs their previous one).
What it comes down to is optimizing chip design to make use of programs, vice versa. There really is now absolute when dealing with this.
MrSpadge - Thursday, December 22, 2011 - link
It's not like - as stated several times in the article - AMD is wrong about the power target of the HD7970, if they mean the PowerTune limit. Think of it as "the card is built to handle this much heat, and is guaranteed not to exceed it". That doesn't forbid drawing less power. And that's exactly what the HD6970 does: it's got the same "power target", but it uses less of its power budget than the HD7970.Like CPUs, whose real world power consumption is often much less than the TDP.
MrS
Ryan Smith - Thursday, December 22, 2011 - link
PowerTune is a hard cap on power consumption. Given a sufficient workload (i.e. FurMark or OCCT), you can make the card try to consume more power than it is allowed, at which point PowerTune kicks in. Or to put this another way, PowerTune doesn't kick in unless the card is at its limit.PowerTune kicked in for both the 6970 and 7970. In which case both cards should have be limited to 250W.