AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher: Graphics Core Next
One of the things we’ve seen as a result of the shift from pure graphics GPUs to mixed graphics and compute GPUs is how NVIDIA and AMD go about making their announcements and courting developers. With graphics GPUs there was no great need to discuss products or architectures ahead of time; a few choice developers would get engineering sample hardware a few months early, and everyone else would wait for the actual product launch. With the inclusion of compute capabilities however comes the need to approach launches in a different manner, a more CPU-like manner.
As a result both NVIDIA and AMD have begun revealing their architectures to developers roughly six months before the first products launch. This is very similar to how CPU launches are handled, where the basic principles of an architecture are publically disclosed months in advance. All of this is necessary as the compute (and specifically, HPC) development pipeline is far more focused on optimizing code around a specific architecture in order to maximize performance; whereas graphics development is still fairly abstracted by APIs, compute developers want to get down and dirty, and to do that they need to know as much about new architectures as possible as soon as possible.
It’s for these reasons that AMD announced Graphics Core Next, the fundamental architecture behind AMD’s new GPUs, back in June of this year at the AMD Fusion Developers Summit. There are some implementation and product specific details that we haven’t known until now, and of course very little was revealed about GCN’s graphics capabilities, but otherwise on the compute side AMD is delivering on exactly what they promised 6 months ago.
Since we’ve already covered the fundamentals of GCN in our GCN preview and the Radeon HD 7970 is primarily a gaming product we’re not going to go over GCN in depth here, but I’d encourage you to read our preview to fully understand the intricacies of GCN. But if you’re not interested in that, here’s a quick refresher on GCN with details pertinent to the 7970.
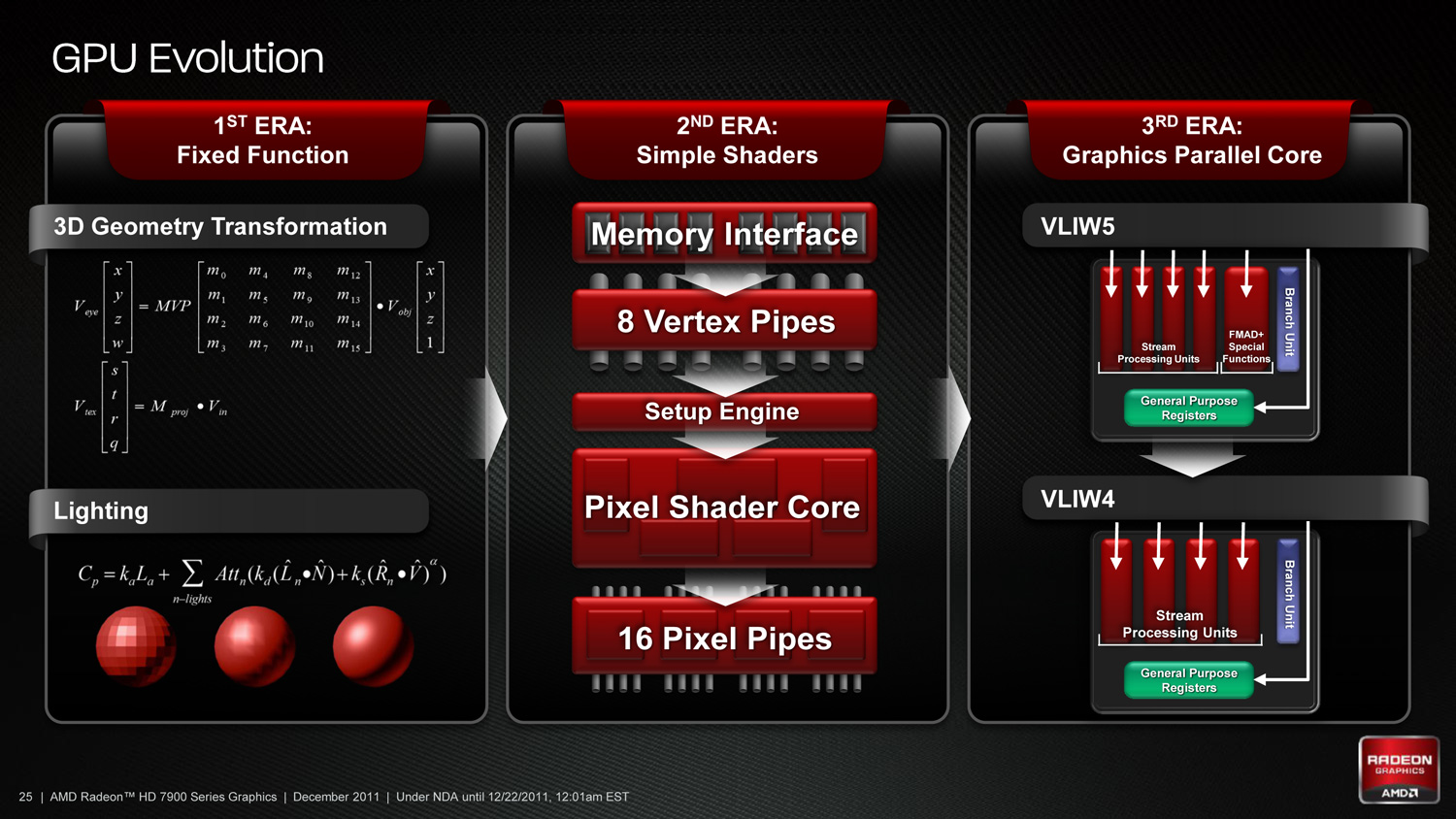
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
Cayman, A VLIW4 Design
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is the situation AMD faced.
But why does AMD want to chase compute in the first place when they already have a successful graphics GPU business? In the long term GCN plays a big part in AMD’s Fusion plans, but in the short term there’s a much simpler answer: because they have to.
In Q3’2011 NVIDIA’s Professional Solutions Business (Quadro + Tesla) had an operating income of 95M on 230M in revenue. Their (consumer) GPU business had an operating income of 146M, but on a much larger 644M in revenue. Professional products have much higher profit margins and it’s a growing business, particularly the GPU computing side. As it stands NVIDIA and AMD may have relatively equal shares of the discrete GPU market, but it’s NVIDIA that makes all the money. For AMD’s GPU business it’s no longer enough to focus only on graphics, they need a larger piece of the professional product market to survive and thrive in the future. And thus we have GCN.








292 Comments
View All Comments
Wreckage - Thursday, December 22, 2011 - link
That's kind of disappointing.atticus14 - Thursday, December 22, 2011 - link
oh look its that guy that was banned from the forums for being an overboard nvidia zealot.medi01 - Tuesday, January 3, 2012 - link
Maybe he meant "somebody @ anandtech is again pissing on AMDs cookies"?I mean "oh, it's fastest and coolest single GPU card on the market, it is slightly more expensive than competitor's, but it kinda sucks since AMD didn't go "significantly cheaper than nVidia" route" is hard to call unbiased, eh?
Kind of disappointing conclusion, indeed.
ddarko - Thursday, December 22, 2011 - link
To each their own but I think this is undeniable impressive:"Even with the same number of ROPs and a similar theoretical performance limit (29.6 vs 28.16), 7970 is pushing 51% more pixels than 6970 is" and
"it’s clear that AMD’s tessellation efficiency improvements are quite real, and that with Tahiti AMD can deliver much better tessellation performance than Cayman even at virtually the same theoretical triangle throughput rate."
Samus - Thursday, December 22, 2011 - link
I prefer nVidia products, mostly because the games I play (EA/DICE Battlefield-series) are heavily sponsered by nVidia, giving them a developement-edge.That out of the way, nVidia has had their problems just like this card is going to experience. Remember when Fermi came out, it was a performance joke, not because it was slow, but because it used a ridiculous amount of power to do the same thing as an ATI card while costing substantially more.
Fermi wasn't successful until second-generation products were released, most obviously the GTX460 and GT430, reasonably priced cards with quality drivers and low power consumption. But it took over a year for nVidia to release those, and it will take over a year for ATI to make this architecture shine.
kyuu - Thursday, December 22, 2011 - link
Wat? The only thing there might be an issue with is drivers. As far as power consumption goes, this should be better than Cayman.CeriseCogburn - Sunday, March 11, 2012 - link
He's saying the 28mn node will have further power improvements. Take it as an amd compliment - rather you should have.StriderTR - Thursday, December 22, 2011 - link
EA/Dice are just as heavily sponsored by AMD, more in fact. Not sure where your getting your information, but its .. well ... wrong. Nvidia bought the rights to advertize the game with their hardware, AMD is heavily sponsoring BF3 and related material. Example, The Controller.Also, the GTX 580 and HD 6970 perform within a few FPS of each other on BF3. I run dual 6970's, by buddy runs dual 580's, we are almost always within 2 FPS of one and other at any given time.
AMD will have the new architecture "shining" in far under a year. They have been focused on it for a long time already.
Simple bottom line, both Nvidia and AMD make world class cards these days. No matter your preference, you have cards to choose from that will rock any games on the planet for a long time to come.
deaner - Thursday, December 22, 2011 - link
Umm, yea no. Not so much with nvidia and EA/DICE Batttlefield series giving nvidia a development edge. (if it does, the results are yet to be seen)Facts are facts, the 5 series to our current review today, the 7970, do and again continue to edge the Nvidia lines. The AMD Catalyst performance of particular note, BF3, has been far superior.
RussianSensation - Thursday, December 22, 2011 - link
."..most obviously the GTX460 and GT430, reasonably priced cards with quality drivers and low power consumption. But it took over a year for nVidia to release those"GTX470/480 launched March 26, 2010
GTX460 launched July 12, 2010
GT430 launched October 11, 2010
Also, Fermi's performance at launch was not a joke. GTX470 delivered performance between HD5850 and HD5870, priced in the middle. Looking now, GTX480 ~ HD6970. So again, both of those cards did relatively well at the time. Once you consider overclocking of the 470/480, they did extremely well, both easily surprassing the 5870 in performance in overclocked states.
Sure power consumption was high, but that's the nature of the game for highest-end GPUs.