Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Apache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
In previous articles, we tested with Spark 1.5 in standalone mode (non-clustered). That worked out well enough, but we saw diminishing returns as core counts went up. In hindsight, just dumping 300 GB of compressed data in one JVM was not optimal for 30+ core systems. The high core counts of the Xeon 8176 and EPYC 7601 caused serious performance issues when we first continued to test this way. The 64 core EPYC 7601 performed like a 16-core Xeon, the Skylake-SP system with 56 cores was hardly better than a 24-core Xeon E5 v4.
So we decided to turn our newest servers into virtual clusters. Our first attempt is to run with 4 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on the latest and greatest version: Apache Spark 2.1.1.
Here are the results:
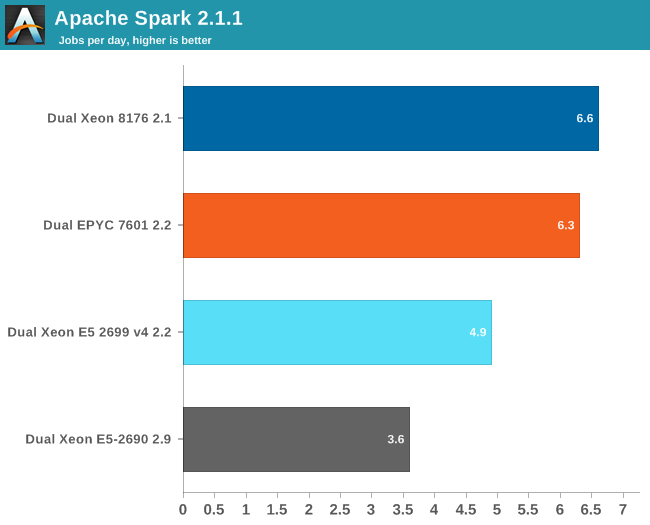
If you wonder who needs such server behemoths besides the people who virtualize a few dozen virtual machines, the answer is Big Data. Big Data crunching has an unsatisfiable hunger for – mostly integer – processing power. Even on our fastest machine, this test needs about 4 hours to finish. It is nothing less than a killer app.
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but is less than 4% of the total testing time.
Given the higher clockspeed in lightly threaded and single threaded parts, the faster shuffle phase probably gives the Intel chip an edge of only about 5%.








219 Comments
View All Comments
alpha754293 - Tuesday, July 11, 2017 - link
Pity that OpenFOAM failed to run on Ubuntu 16.04.2 LTS. I would have been very interested in those results.farmergann - Tuesday, July 11, 2017 - link
Are you trying to hide the fact that AMD's performance per watt absolutely dominates intel's, or have you simply overlooked one of, if not the, single most important aspects of server processors?Ryan Smith - Tuesday, July 11, 2017 - link
Neither. We just had very little time to look at power consumption. It's also the metric we're the least confident in right now, as we'd like to have a better understanding of the quirks of the platform (which again takes more time).Carl Bicknell - Wednesday, July 12, 2017 - link
Ryan / Ian,Just to let you know there are better chess benchmarks than the one you've chosen. Stockfish is an example of a newer program which better uses modern CPU architecture.
NixZero - Tuesday, July 11, 2017 - link
"AMD's MCM approach is much cheaper to manufacture. Peak memory bandwidth and capacity is quite a bit higher with 4 dies and 2 memory channels per die. However, there is no central last level cache that can perform low latency data coordination between the L2-caches of the different cores (except inside one CCX). The eight 8 MB L3-caches acts like - relatively low latency - spill over caches for the 32 L2-caches on one chip. "isnt skylake-x's l3 a victim cache too? and divided at 1.3mb for each core, not a monolytic one?
Ian Cutress - Tuesday, July 11, 2017 - link
That's what a 'spill-over' cache is - it accepts evicted cache lines.NixZero - Wednesday, July 12, 2017 - link
so why its put as an advantage for intel cache, which is spill over too?JonathanWoodruff - Wednesday, July 12, 2017 - link
Since the Intel one is all on one die, a miss to a "slice" of cache can be filled without DRAM-like latencies from another slice. Since AMD has it's last level caches spread across dies, going to another cache looks to be equivalent latency-wise to going to DRAM. It wouldn't necessarily have to be quite that bad, and I would expect some improvement here for Zen2.Martin_Schou - Tuesday, July 11, 2017 - link
This has to be wrong:CPU Two EPYC 7601 (2.2 GHz, 32c, 8x8MB L3, 180W)
RAM 512 GB (12x32 GB) Samsung DDR4-2666 @2400
12 x 32 GB is 384 GB, and 12 sticks doesn't fit nicely into 8 channels. In all likelihood that's supposed to be 16x32 GB, as we see in the E52690
Dr.Neale - Tuesday, July 11, 2017 - link
I find myself puzzled by the curious omission in this article of a key aspect of Server architecture: Data Security.AMD has a LOT; Intel, not so much.
I would think this aspect of Server "Performance" would be a major consideration in choosing which company's Architecture to deploy in a Secure Server scenario. Especially in light of Recent Revelations fuelling Hacking Headlines in the news, and Dominating Discussions on various social media websites.
How much is Data Security worth?
A topic of EPYC consequence!