Assessing IBM's POWER8, Part 2: Server Applications on OpenPOWER
by Johan De Gelas on September 15, 2016 8:01 AM ESTFuture Visions: POWER8 with NVLink
Digging a bit deeper, the shiny new S822LC is a different beast. If offers the "NVIDIA improved" POWER8. The core remained the same but the CPU now comes with NVIDIA's NVlink technology. Four of these NVLink ports allows the S822LC to make a very fast (80 GB/s full duplex) and direct link with the latest and greatest of NVIDIA GPUs: the Tesla P100. Ryan has discussed NVLink and the 16 nm P100 in more detail a few months ago. I quote:
NVLink will allow GPUs to connect to either each other or to supporting CPUs (OpenPOWER), offering a higher bandwidth cache coherent link than what PCIe 3 offers. This link will be important for NVIDIA for a number of reasons, as their scalability and unified memory plans are built around its functionality.
Each P100 has a 720 GB/s of memory bandwidth, powered by 16 GB of HBM2 stacked memory. If you combine that with the fact that the P100 has more than twice the processing power in half precision and double precision floating point (important for machine learning algorithms) than its predecessor, it easy to understand why the data transfers from the CPU to GPU can easily become a bottleneck in some applications.
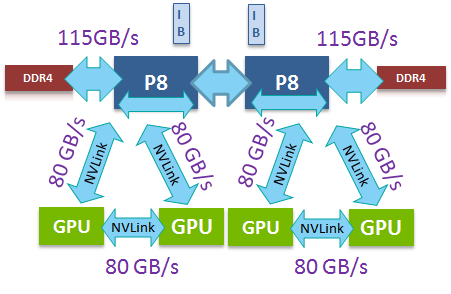
This means that the "OpenPOWER way of working" has enabled the IBM POWER8 to be the first platform to fully leverage the best of NVIDIA's technology. It is almost certain that Intel will not add NVLink to their products, as Intel went a totally different route with the Xeon and Xeon Phi. NVLink offers 80 GB/s of full-duplex connectivity per GPU, which is provided in the form of 4 20GB/s connections that can be routed between GPUs and CPUs as needed. By comparison, a P100 that plugs into an x16 PCIe 3.0 slot only gets 16 GB/s full duplex to communicate with both the CPU and the other GPUs. So theoretically, a quad NVLink setup from GPU to CPU offers at least 2.5 times more bandwidth. However, IBM claims that in reality the advantage is 2.8x as the NVLink is more efficient than PCIe (83% of theoretical bandwidth vs. 74%).

The NVLink equipped P100 cards will make use of the SXM2 form factor and come with a bonus: they deliver 13% more raw compute performance than the "classic" PCIe card due to the higher TDP (300W vs 250W). By the numbers, this amounts to 5.3 TFLOPS double precision for the SXM2 version, versus 4.7 TFLOPS for the PCIe version.








49 Comments
View All Comments
nils_ - Monday, September 26, 2016 - link
Isn't the limit slighty lower than 32 GiB? At some point the JVM switches to 64 bit pointers, which means you'll lose a lot of the available heap to larger pointers. I think you might want to lower your settings. I'm curious, what kind of GC times are you seeing with your heap size? I don't currently have access to Java running on non virtualised hardware so I would like to know if the overhead is significant (mostly running Elasticsearch here).CajunArson - Thursday, September 15, 2016 - link
All in all the Power chip isn't terrible but the power consumption coupled with the sheer amount of tuning that is required just to get it competitive with the Xeons isn't too encouraging. You could spend far less time tuning the Xeons and still have higher performance or go ahead with tuning to get even more performance out of those Xeons.On top of the fact that this isn't a supposedly "high end" model, the higher end power parts cost more and will burn through even more power, and that's an expense that needs to be considered for the types of real-world applications that use these servers.
dgingeri - Thursday, September 15, 2016 - link
That ad on the last page that claims lower equipment cost of course compares that to an HP DL380, the most overpriced Xeon E5 system out right now. (I know because I shopped them.) Comparing it to a comparable Dell R730 would show less expense, better support, and better expansion options.Morawka - Thursday, September 15, 2016 - link
you mean a company made a slide that uses the most extreme edge cases to make their product look good?!?! Shocking /sGondalf - Thursday, September 15, 2016 - link
Something is wrong is these power consumption data. The plataform idles at 221W and under full load only 260W?? the cpu is vanished?? Power 8 at over 3Ghz has an active power of only 40W??1) the idle value is wrong or 2) the under load value is wrong. All this is not consistent with IBM TDP official values.
IMO the energy consumption page of the article has to be rewrite.
JohanAnandtech - Thursday, September 15, 2016 - link
We have double checked those numbers. It is probably an indication that many of the power saving features do not work well under Linux right now.BTW, just to give you an idea: running c-ray (floating point) caused the consumption to go to 361W.
Kevin G - Thursday, September 15, 2016 - link
I presume that c-ray uses the 256 bit vector unit on POWER8?Also have you done any energy consumption testing that takes advantage of the hardware decimal unit?
mapesdhs - Thursday, September 15, 2016 - link
C-ray isn't that smart. :D It's a very simple code, brute force basically, and the smaller dataset can easily fit in a modern cache (actually the middling size test probably does too on CPUs like these). Hmm, I suppose it's possible one could optimise the compilation a bit to help, but I doubt anything except a full rewrite could make decent use of any vector tech, and I don't want to allow changes to the code, that would make comparisons to all other test results null. Compiler optimisations are ok, but not multi-pass optimisations that feed back info about the target data into the initial compile, that's cheating IMO (some people have done this to obtain what look like really silly run times, but I don't include them on my main C-ray page).Ian.
Gondalf - Tuesday, September 20, 2016 - link
Ummm so in short words the utilized sw don't stress at all the cpu, not even the hot caches near the memory banks. We need a bench with an high memory utilization and a balanced mix between integer and FP, more in line with real world utilizationI don't know if this test is enough to say POWER8 is power/perf competitive with haswell in 22nm.
In fact POWER market share is definitively at the historic minimum and 14nm Broadwell is pretty young, so this disaster it is not its fault.
jesperfrimann - Wednesday, September 21, 2016 - link
If you have a OPAL (Bare Metal system that cannot run POWERVM) then all the powersavings features are off by default AFAIR.Try to have a look at:
https://public.dhe.ibm.com/common/ssi/ecm/po/en/po...
Many of the features does have a performance impact, ranging from negative over neutral to positive for a single one.
But Again. I think your comparison with 'vanilla' software stacks are relevant. This is what people would see out of the box with an existing software stack.
It is 101% relevant to do that comparison as this is the marked that IBM is trying to break into with these servers.
But what could be fun to see was some tests where all the Bells and Whistles were utilized. As many have written here.. use of Hardware supported Decimal Floating Point. The Vector Execution unit, the ability to do hardware assisted Memory Compression etc. etc.
// Jesper