Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Benchmarks Versus Reality
Ever run into the problem that your manager wants a clear and short answer, while the real story has lots of nuances? (ed: and hence AnandTech) The short but inaccurate answer almost always wins. It is human nature to ignore complex stories and to prefer easy to grasp answers. The graph below is a perfect illustration of that. Although this one has been produced by Intel, almost everybody in the industry, including the ARM SoC companies, love the simplicity it affords in describing the competitive situation.
The graph compares the ICC compiled & published results for SPECint_rate_base2006 with some of the claimed (gcc compiled?) results of the ARM server SoC vendors.
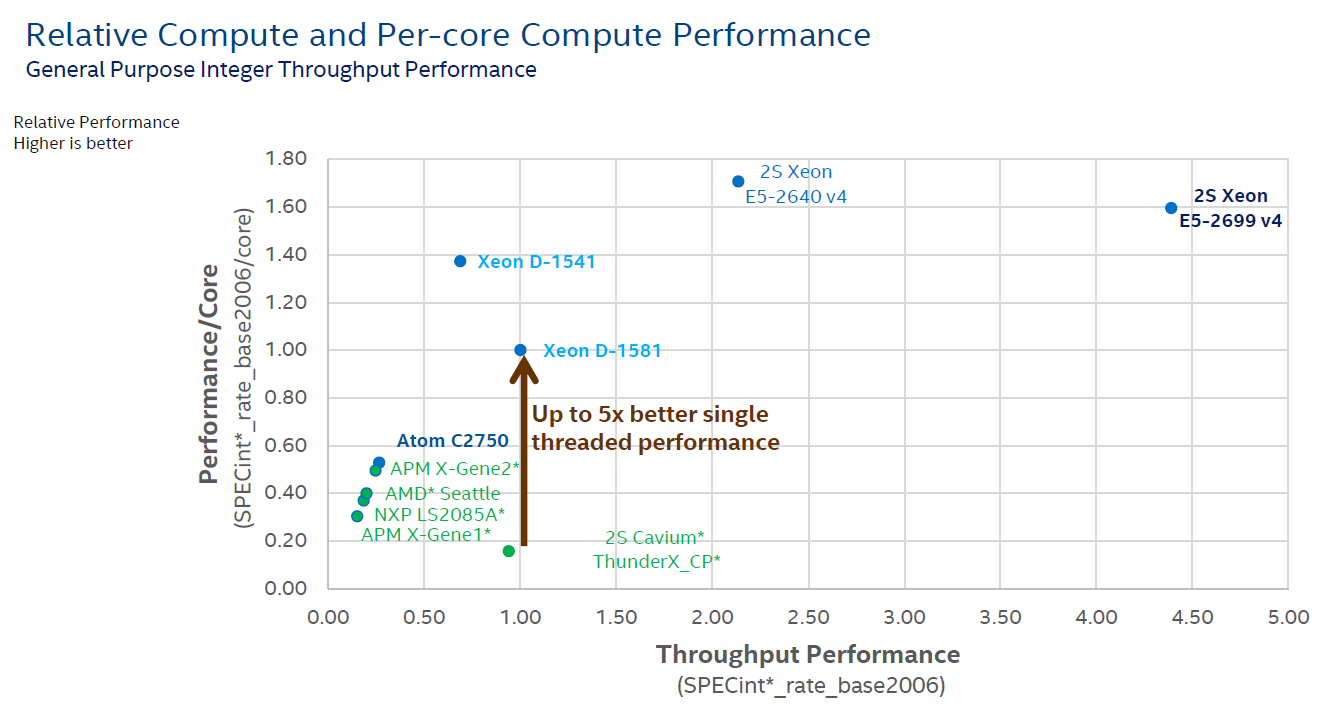
The graph shows two important performance vectors: throughput and single core performance. The former (X-axis) is self-explanatory, the latter (Y-axis) should give an indication of response times (latency). The two combined (x, y coordinate) should give you an idea on how the SoC/CPU performs in most applications that are not perfectly parallel. It is a very elegant way to give a short and crystal clear answer to anyone with a technical or scientific background.
But there are many drawbacks. The main problem is "single core performance". Since this is just diving the score by the number of cores, this favors the CPUs with some form of hardware multi-threading. But in many cases, the extra threads only help with throughput and not with latency. For example, if there are a few heavy SQL requests that keep you waiting, adding threads to a core does not help at all, on the contrary. So the graph above gives a 20% advantage to the SMT capable cores of Intel on y-axis, while hyperthreading is most of the time a feature that boosts throughput.
Secondly, dividing throughput by the number of cores means also that you favor the architectures that are able to run many instances of SPECint. In other words, it is all about memory bandwidth and cache size. So if a CPU does not scale well, the graph will show a lower per core performance. So basically this kind of graph creates the illusion of showing two performance parameters (throughput and latency), but it is in fact showing throughput and something that is more related to throughput (throughput normalized per core?) than latency. And of course, SPECint_rate is only a very inaccurate proxy for server compute performance: IPC is higher than in most server applications and there is too much emphasis on cache size and memory bandwidth. Running 32 parallel instances of an application is totally different from running one application with 32 threads.
This is definitely not written to defend or attack any vendor: many vendors publish and abuse these kind of graphs to make their point. Our point is that it is very likely that this kind of graph gives you a very inaccurate and incomplete view of the competition.
But as the saying goes, the proof is in the pudding, so let's put together a framework for comparing these high level overviews with real world testing. First step, let's pretend the graph above is accurate. So the Cavium ThunderX has absolutely terrible single threaded performance: one-fifth that of the best Xeon D, not even close to any of the other ARM SoCs. A ThunderX core cannot even deliver half the performance of an ARM Cortex-A57 core (+/- 10 points per core), which is worse than the humble Cortex-A53. It does not get any better: the throughput of a single ThunderX SoC is less than half of the Xeon D-1581. The single threaded performance of the Xeon D-1581 is only 57% of the Xeon E5-2640's and it cannot compete with the throughput of even a single Xeon E5-2640 (2S = 2.2 times the Xeon-D 1581).
Second step, do some testing instead of believing vendor claims or published results from SPEC CPU2006. Third step, compare the graph above with our test results...








82 Comments
View All Comments
vivs26 - Wednesday, June 15, 2016 - link
Not necessarily - (read Amdahl's law of diminishing returns). The performance actually depends on the workload. Having a million cores guarantees nothing in terms of performance unless the workload is parallelizable which in the real world is not as much as we think it could be. I'm curious to see how xeon merged with altera programmable fabric performs than ARM on a server.maxxbot - Wednesday, June 22, 2016 - link
Technically true but every generation that millstone gets a little smaller, the die area and power needed to translate x86 into uops isn't huge and reduces every generation.jardows2 - Wednesday, June 15, 2016 - link
Interesting. Faster in a few workloads where heavy use of multi-thread is important, but significantly slower in more single thread workloads. For server use, you don't always want parallelized tasks. The results are pretty much across the board for all the processors tested: If the ThunderX was slower, it was slower than all the Intel chips. If it were faster, it was faster than all but the highest end Intel Chips. With the price only being slightly lower than the cheapest Intel chip being sold, I don't think this is going to be a Xeon competitor at all, but will take a few niche applications where it can do better.With no significant energy savings, we should be looking forward to the ThunderX2 to see if it will bring this into a better alternative.
ddriver - Wednesday, June 15, 2016 - link
There is hardly a server workload where you don't get better throughput by throwing more cores and servers at it. Servers are NOT about parallelized task, but about concurrent tasks. That's why while desktops are still stuck at 8 cores, server chips come with 20 and more... Server workloads are usually very simple, it is just that there is a lot of them. They are so simple and take so little time it literally makes no sense parallelizing them.jardows2 - Wednesday, June 15, 2016 - link
In the scenario you described, the single-thread performance takes on even more importance, thus highlighting the advantage the Xeon's currently have in most server configurations.niva - Wednesday, June 15, 2016 - link
Not if the Xeon doesn't have enough cores to actually process 40+ singlethreaded tasks con-currently.hechacker1 - Wednesday, June 15, 2016 - link
But kernels and VMWare know how to schedule multiple threads on 1 core if it's not being fully utilized. Single threaded IPC can make up for not having as many cores. See the iPhone SoCs for another example.ddriver - Wednesday, June 15, 2016 - link
Not if you have thousands of concurrent workloads and only like 8 cores. As fast as each core might be, the overhead from workload context switching will eat it up.willis936 - Thursday, June 16, 2016 - link
Yeah if each task is not significantly longer than a context switch. Context switches are very fast, especially with processors with many sets of SMT registers per core.ddriver - Thursday, June 16, 2016 - link
If what you suggest is correct, then intel would not be investing chip TDP in more cores but higher clocks and better single threaded performance. Clearly this is not the case, as they are pushing 20 cores at the fairly modest 2.4 Ghz.