The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTAsynchronous Concurrent Compute: Pascal Gets More Flexible
Continuing our dive into the Pascal architecture, while Pascal did not make any fundamental execution changes to the CUDA cores, the same is not true for how work is allocated/scheduled on the CUDA cores. In fact, next to the addition of GDDR5X, I’d consider the changes to work scheduling to be the other great change to the overall Pascal core architecture. With Pascal, NVIDIA has significantly improved their ability to allocate and balance workloads, which in turn has ramifications in several difference scenarios. But for the AnandTech audience the greatest significance is going to be in what it means for work concurrency when using asynchronous compute.
However to understand just what NVIDIA has done here, we’re going to have to first take a step back and try to unravel the ball of yarn that is asynchronous compute, concurrency, and load balancing on prior NVIDIA architectures. From a technical perspective, NVIDIA has slowly evolved their work queue execution abilities over time. Consumer Kepler (GK10x) could only handle a single work queue, while Big Kepler (GK110/GK210) added HyperQ, which introduced a 32 queue setup, but one that could only be used with pure compute workloads. For HPC users this was a big deal, but for consumer use cases there was no support for mixing HyperQ compute queues with a graphics queue.
| NVIDIA GPU Queue Engine Support | |||||
| Graphics/Mixed Mode | Pure Compute Mode | Scheduling | |||
| Pascal (1000 Series) | 1 Graphics + 31 Compute | 32 Compute | Dynamic! | ||
| Maxwell 2 (900 Series) | 1 Graphics + 31 Compute | 32 Compute | Static | ||
| Maxwell 1 (750 Series) | 1 Graphics | 32 Compute | Static | ||
| Kepler GK110 (780/Titan) | 1 Graphics | 32 Compute | Static | ||
| Kepler GK10x (600/700 Series) | 1 Graphics | 1 Compute | N/A | ||
Moving to Maxwell, Maxwell 1 was a repeat of Big Kepler, offering HyperQ without any way to mix it with graphics. It was only with Maxwell 2 that NVIDIA finally gained the ability to mix compute queues with graphics mode, allowing for the single graphics queue to be joined with up to 31 compute queues, for a total of 32 queues.
This from a technical perspective is all that you need to offer a basic level of asynchronous compute support: expose multiple queues so that asynchronous jobs can be submitted. Past that, it's up to the driver/hardware to handle the situation as it sees fit; true async execution is not guaranteed. Frustratingly then, NVIDIA never enabled true concurrency via asynchronous compute on Maxwell 2 GPUs. This despite stating that it was technically possible. For a while NVIDIA never did go into great detail as to why they were holding off, but it was always implied that this was for performance reasons, and that using async compute on Maxwell 2 would more likely than not reduce performance rather than improve it.
There’s a maxim in the consumer electronics industry that if you want to know what’s wrong with the current product, wait for the next one to be released. And in the case of the Pascal launch, this definitely ended up being true. Now that Pascal is upon us and NVIDIA has fixed that which ills Maxwell 2, we finally know why NVIDIA has held off from enabling concurrency with asynchronous compute on Maxwell 2 all this time.
The issue, as it turns out, is that while Maxwell 2 supported a sufficient number of queues, how Maxwell 2 allocated work wasn’t very friendly for async concurrency. Under Maxwell 2 and earlier architectures, GPU resource allocation had to be decided ahead of execution. Maxwell 2 could vary how the SMs were partitioned between the graphics queue and the compute queues, but it couldn’t dynamically alter them on-the-fly. As a result, it was very easy on Maxwell 2 to hurt performance by partitioning poorly, leaving SM resources idle because they couldn’t be used by the other queues.
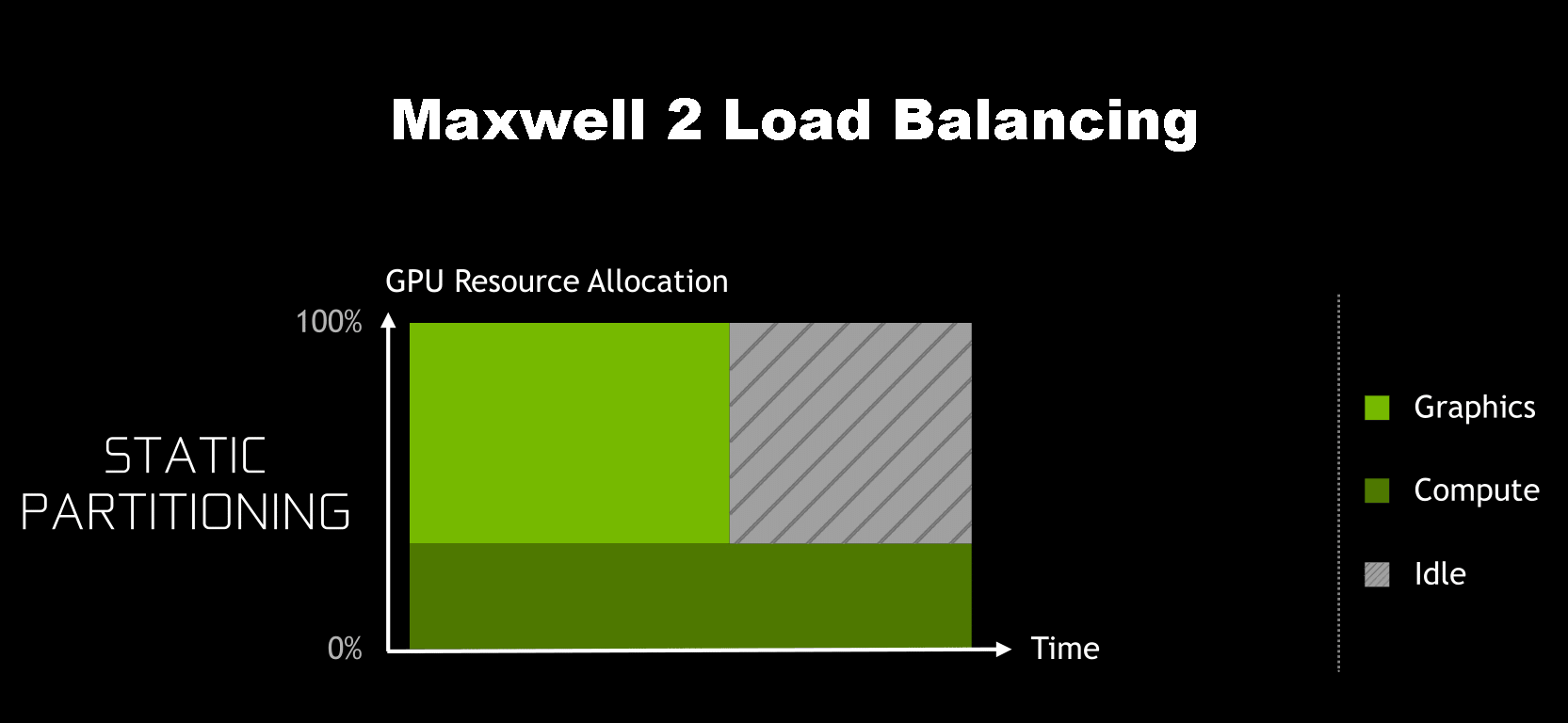
NVIDIA’s theoretical example involves when the graphics queue runs out of work before the compute queue, though in practice either one can happen, and either one would be similarly bad. There are a number of caveats in this example – among other things, this assumes that other new work can’t be started until both queues are finished – so please don’t consider this a catch-all for how concurrency under asynchronous compute works, but it covers the most basic and common case where a compute workload is closely tied to a graphics workload.
Meanwhile not shown in these simple graphical examples is that for async’s concurrent execution abilities to be beneficial at all, there needs to be idle time bubbles to begin with. Throwing compute into the mix doesn’t accomplish anything if the graphics queue can sufficiently saturate the entire GPU. As a result, making async concurrency work on Maxwell 2 is a tall order at best, as you first needed execution bubbles to fill, and even then you’d need to almost perfectly determine your partitions ahead of time.
Getting back to Pascal then, Pascal finally fixes the resource allocation issue. For Pascal, NVIDIA has implemented a dynamic load balancing system to replace Maxwell 2’s static partitions. Now if the queues end up unbalanced and one of the queues runs out of work early, the driver and work schedulers can step in and fill up the remaining time with work from the other queues.
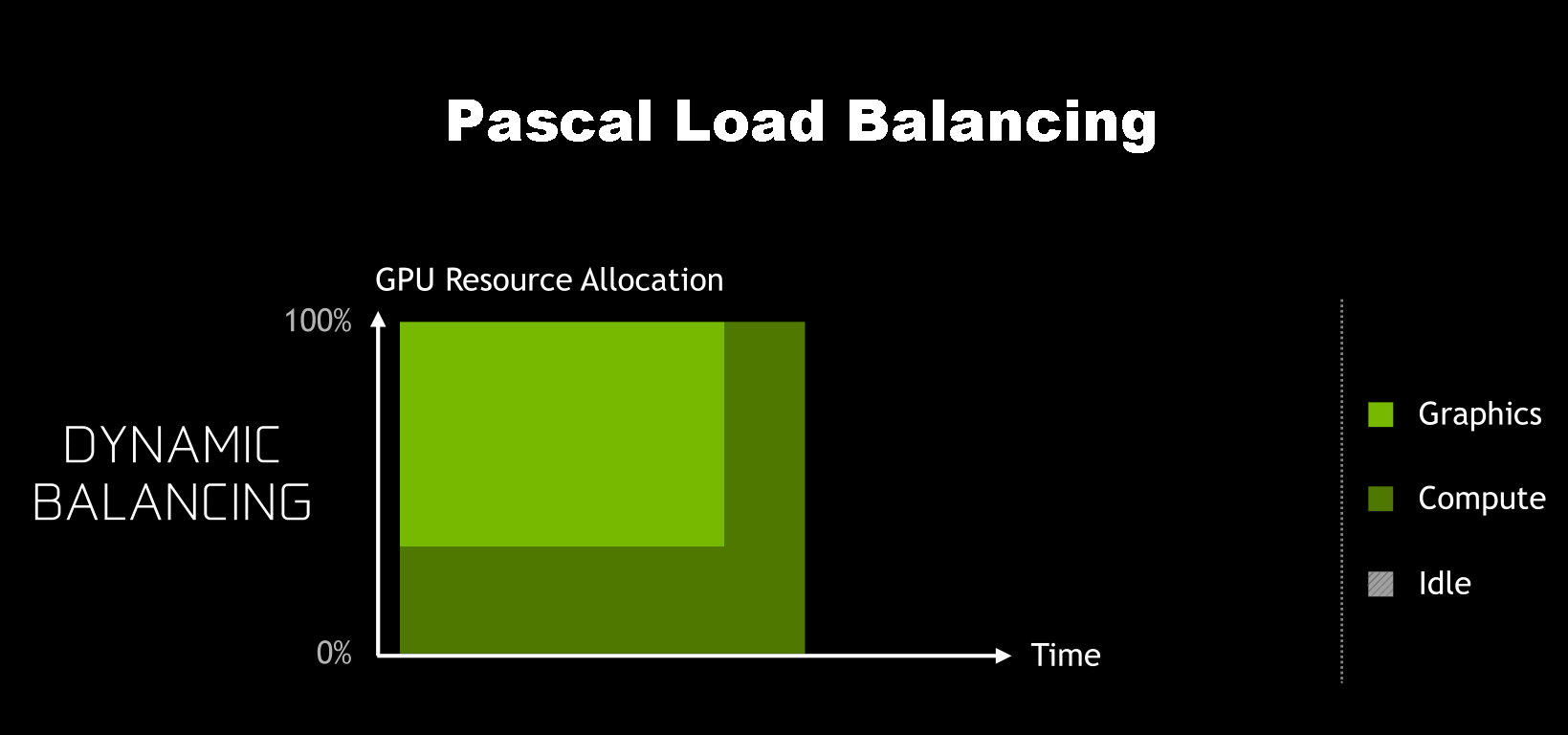
In concept it sounds simple, and in practice it should make a large difference to how beneficial async compute can be on NVIDIA’s architectures. Adding more work to create concurrency to fill execution bubbles only works if the queue scheduling itself doesn’t create bubbles, and this was Maxwell 2’s Achilles’ heel that Pascal has addressed.
At the same time however I feel it’s important to note that the scheduling change alone won’t (and can’t) guarantee that Pascal will see significant gains from async compute across the board. Async compute itself is a catch-all term – there are lots of things you can do with asynchronous work submission/execution – so async doesn’t mean that a game is making significant use of concurrency. Furthermore the concurrency is still based on filling execution bubbles, and that means that there needs to be bubbles to fill in the first place. In other words, the greatest gains from async will come from scenarios where for whatever reason, the graphics queue and its synchronous shaders can’t completely saturate the GPU on its own.
Right now I think it’s going to prove significant that while NVIDIA introduced dynamic scheduling in Pascal, they also didn’t make the architecture significantly wider than Maxwell 2. As we discussed earlier in how Pascal has been optimized, it’s a slightly wider but mostly higher clocked successor to Maxwell 2. As a result there’s not too much additional parallelism needed to fill out GP104; relative to GM204, you only need 25% more threads, a relatively small jump for a generation. This means that while NVIDIA has made Pascal far more accommodating to asynchronous concurrent executeion, there’s still no guarantee that any specific game will find bubbles to fill. Thus far there’s little evidence to indicate that NVIDIA’s been struggling to fill out their GPUs with Maxwell 2, and with Pascal only being a bit wider, it may not behave much differently in that regard.
Meanwhile, because this is a question that I’m frequently asked, I will make a very high level comparison to AMD. Ever since the transition to unified shader architectures, AMD has always favored higher ALU counts; Fiji had more ALUs than GM200, mainstream Polaris 10 has nearly as many ALUs as high-end GP104, etc. All other things held equal, this means there are more chances for execution bubbles in AMD’s architectures, and consequently more opportunities to exploit concurrency via async compute. We’re still very early into the Pascal era – the first game supporting async on Pascal, Rise of the Tomb Raider, was just patched in last week – but on the whole I don’t expect NVIDIA to benefit from async by as much as we’ve seen AMD benefit. At least not with well-written code.
Otherwise, for the time being, the one good benchmark we have here is 3DMark Time Spy, which was released last week. The ground up DirectX 12 benchmark attempts to heavily overlap rendering passes to fill those aforementioned execution bubbles.
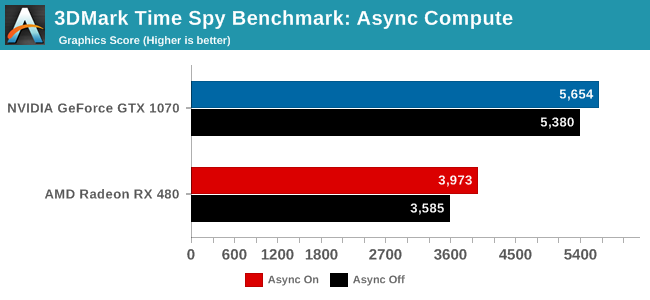
Taking a quick run of the benchmark, on a relative basis we see a 10.8% gain from using async compute plus concurrency for the RX 480, and a 5.4% gain for the GTX 1070. This is but one benchmark (and technically not even a game at that), but for what it’s worth this is the kind of trend I’m expecting to see in future games as they get better about exploiting workload concurrency via async compute.
Finally, getting back to the subject of dynamic scheduling, I’ve spent some time mulling over what’s probably the obvious question: if dynamic scheduling is so great, why didn’t NVIDIA do this sooner? It’s not a question I have an answer to, but I strongly suspect it’s another one of those tradeoffs that’s rooted in balancing costs and benefits. Dynamic scheduling requires a greater management of hazards that simply weren’t an issue with static scheduling, as now you need to handle everything involved with suddenly switching an SM to a different queue. Meanwhile NVIDIA more than likely paid a die space penalty for implementing dynamic scheduling. GPUs continually sit on the fence between being an ultra-fast staticly scheduled array of ALUs and an ultra-flexible somewhat smaller array of ALUs, and GPU vendors get to sit in the middle trying to figure out which side to lean towards in order to deliver the best performance for workloads that are 2-5 years down the line. It is, if you’ll pardon the pun, a careful balancing act for everyone involved.








200 Comments
View All Comments
TestKing123 - Wednesday, July 20, 2016 - link
Then you're woefully behind the times since other sites can do this better. If you're not able to re-run a benchmark for a game with a pretty significant patch like Tomb Raider, or a high profile game like Doom with a significant performance patch like Vulcan that's been out for over a week, then you're workflow is flawed and this site won't stand a chance against the other crop. I'm pretty sure you're seeing this already if you have any sort of metrics tracking in place.TheinsanegamerN - Wednesday, July 20, 2016 - link
So question, if you started this article on may 14th, was their no time in the over 2 months to add one game to that benchmark list?nathanddrews - Wednesday, July 20, 2016 - link
Seems like an official addendum is necessary at some point. Doom on Vulkan is amazing. Dota 2 on Vulkan is great, too (and would be useful in reviews of low end to mainstream GPUs especially). Talos... not so much.Eden-K121D - Thursday, July 21, 2016 - link
Talos Principle was a proof of conceptajlueke - Friday, July 22, 2016 - link
http://www.pcgamer.com/doom-benchmarks-return-vulk...Addendum complete.
mczak - Wednesday, July 20, 2016 - link
The table with the native FP throughput rates isn't correct on page 5. Either it's in terms of flops, then gp104 fp16 would be 1:64. Or it's in terms of hw instruction throughput - then gp100 would be 1:1. (Interestingly, the sandra numbers for half-float are indeed 1:128 - suggesting it didn't make any use of fp16 packing at all.)Ryan Smith - Wednesday, July 20, 2016 - link
Ahh, right you are. I was going for the FLOPs rate, but wrote down the wrong value. Thanks!As for the Sandra numbers, they're not super precise. But it's an obvious indication of what's going on under the hood. When the same CUDA 7.5 code path gives you wildly different results on Pascal, then you know something has changed...
BurntMyBacon - Thursday, July 21, 2016 - link
Did nVidia somehow limit the ability to promote FP16 operations to FP32? If not, I don't see the point in creating such a slow performing FP16 mode in the first place. Why waste die space when an intelligent designer can just promote the commands to get normal speeds out of the chip anyways? Sure you miss out on speed doubling through packing, but that is still much better than the 1/128 (1/64) rate you get using the provided FP16 mode.Scali - Thursday, July 21, 2016 - link
I think they can just do that in the shader compiler. Any FP16 operation gets replaced by an FP32 one.Only reading from buffers and writing to buffers with FP16 content should remain FP16. Then again, if their driver is smart enough, it can even promote all buffers to FP32 as well (as long as the GPU is the only one accessing the data, the actual representation doesn't matter. Only when the CPU also accesses the data, does it actually need to be FP16).
owan - Wednesday, July 20, 2016 - link
Only 2 months late and published the day after a different major GPU release. What happened to this place?