The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTRise of the Tomb Raider
Starting things off in our benchmark suite is the built-in benchmark for Rise of the Tomb Raider, the latest iteration in the long-running action-adventure gaming series. One of the unique aspects of this benchmark is that it’s actually the average of 4 sub-benchmarks that fly through different environments, which keeps the benchmark from being too weighted towards a GPU’s performance characteristics under any one scene.
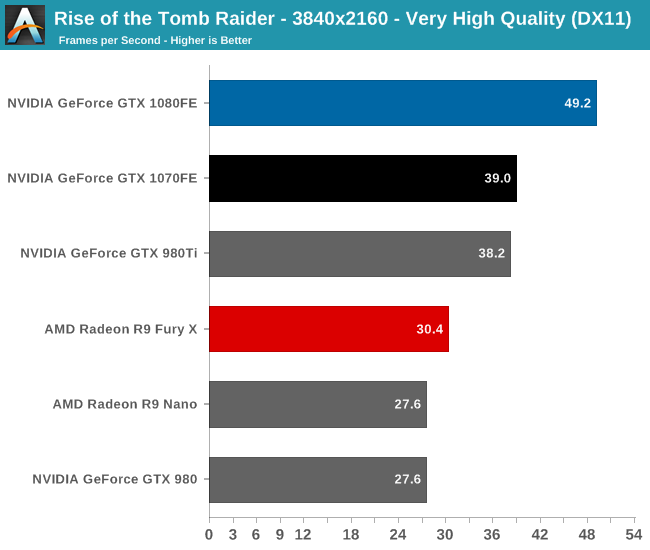
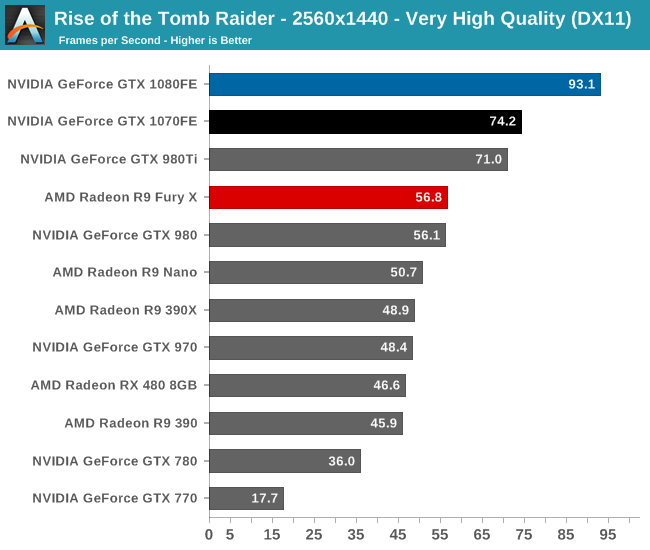
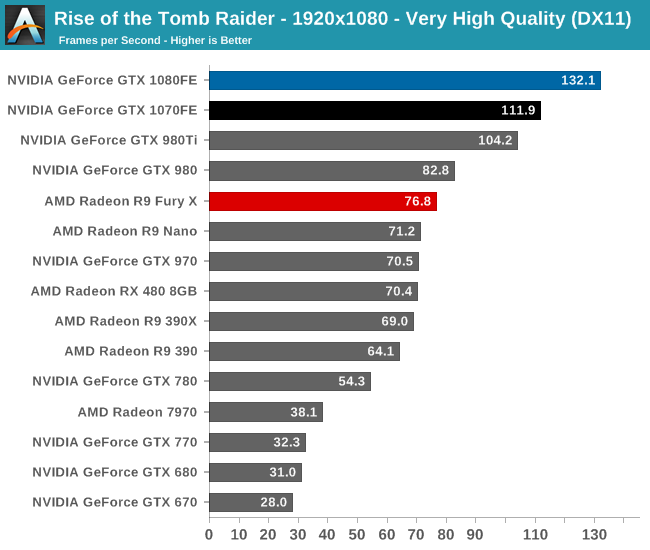
To kick things off then, while I picked the benchmark order before collecting the performance results, it’s neat that Rise of the Tomb Raider ends up being a fairly consistent representation of how the various video cards compare to each other. The end result, as you might expect, puts the GTX 1080 and GTX 1070 solidly in the lead. And truthfully there’s no reason for it to be anything but this; NVIDIA does not face any competition from AMD at the high-end at this point, so the two GP104 cards are going to be unrivaled. It’s not a question of who wins, but by how much.
Overall we find the GTX 1080 ahead of its predecessor, the GTX 980, by anywhere between 60% and 78%, with the lead increasing with the resolution. The GTX 1070’s lead isn’t quite as significant though, ranging from 53% to 60#. This is consistent with the fact that the GTX 1070 is specified to trail the GTX 1080 by more than we saw with the 980/970 in 2014, which means that in general the GTX 1070 won’t see quite as much uplift.
What we do get however is confirmation that the GTX 1070FE is a GTX 980 Ti and more. The performance of what was NVIDIA’s $650 flagship can now be had in a card that costs $450, and with any luck will get cheaper still as supplies improve. For 1440p gamers this should hit a good spot in terms of performance.
Otherwise when it comes to 4K gaming, NVIDIA has made a lot of progress thanks to GTX 1080, but even their latest and greatest card isn’t quite going to crack 60fps here. We haven’t yet escaped having to made quality tradeoffs for 4K at this time, and it’s likely that future games will drive that point home even more.
Finally, 1080p is admittedly here largely for the sake of including much older cards like the GTX 680, to show what kind of progress NVIDIA has made since their first 28nm high-end card. The result? A 4.25x performance increase over the GTX 680.








200 Comments
View All Comments
Ryan Smith - Friday, July 22, 2016 - link
2) I suspect the v-sync comparison is a 3 deep buffer at a very high framerate.lagittaja - Sunday, July 24, 2016 - link
1) It is a big part of it. Remember how bad 20nm was?The leakage was really high so Nvidia/AMD decided to skip it. FinFET's helped reduce the leakage for the "14/16"nm node.
That's apples to oranges. CPU's are already 3-4Ghz out of the box.
RX480 isn't showing it because the 14nm LPP node is a lemon for GPU's.
You know what's the optimal frequency for Polaris 10? 1Ghz. After that the required voltage shoots up.
You know, LPP where the LP stands for Low Power. Great for SoC's but GPU's? Not so much.
"But the SoC's clock higher than 2Ghz blabla". Yeah, well a) that's the CPU and b) it's freaking tiny.
How are we getting 2Ghz+ frequencies with Pascal which so closely resembles Maxwell?
Because of the smaller manufacturing node. How's that possible? It's because of FinFET's which reduced the leakage of the 20nm node.
Why couldn't we have higher clockspeeds without FinFET's at 28nm? Because power.
28nm GPU's capped around the 1.2-1.4Ghz mark.
20nm was no go, too high leakage current.
16nm gives you FinFET's which reduced the leakage current dramatically.
What does that enable you to do? Increase the clockspeed..
Here's a good article
http://www.anandtech.com/show/8223/an-introduction...
lagittaja - Sunday, July 24, 2016 - link
As an addition to the RX 480 / Polaris 10 clockspeedGCN2-GCN4 VDD vs Fmax at avg ASIC
http://i.imgur.com/Hdgkv0F.png
timchen - Thursday, July 21, 2016 - link
Another question is about boost 3.0: given that we see 150-200 Mhz gpu offset very common across boards, wouldn't it be beneficial to undervolt (i.e. disallow the highest voltage bins corresponding to this extra 150-200 Mhz) and offset at the same time to maintain performance at lower power consumption? Why did Nvidia not do this in the first place? (This is coming from reading Tom's saying that 1060 can be a 60w card having 80% of its performance...)AnnonymousCoward - Thursday, July 21, 2016 - link
NVIDIA, get with the program and support VESA Adaptive-Sync already!!! When your $700 card can't support the VESA standard that's in my monitor, and as a result I have to live with more lag and lower framerate, something is seriously wrong. And why wouldn't you want to make your product more flexible?? I'm looking squarely at you, Tom Petersen. Don't get hung up on your G-sync patent and support VESA!AnnonymousCoward - Thursday, July 21, 2016 - link
If the stock cards reach the 83C throttle point, I don't see what benefit an OC gives (won't you just reach that sooner?). It seems like raising the TDP or under-voltaging would boost continuous performance. Your thoughts?modeless - Friday, July 22, 2016 - link
Thanks for the in depth FP16 section! I've been looking forward to the full review. I have to say this is puzzling. Why put it on there at all? Emulation would be faster. But anyway, NVIDIA announced a new Titan X just now! Does this one have FP16 for $1200? Instant buy for me if so.Ryan Smith - Friday, July 22, 2016 - link
Emulation would be faster, but it would not be the same as running it on a real FP16x2 unit. It's the same purpose as FP64 units: for binary compatibility so that developers can write and debug Tesla applications on their GeForce GPU.hoohoo - Friday, July 22, 2016 - link
Excellent article, Ryan, thank you!Especially the info on preemption and async/scheduling.
I expected the preemption mght be expensive in some circumstances, but I didn't quite expect it to push the L2 cache though! Still this is a marked improvement for nVidia.
hoohoo - Friday, July 22, 2016 - link
It seems like the preemption is implemented in the driver though? Are there actual h/w instructions to as it were "swap stack pointer", "push LDT", "swap instruction pointer"?