Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
The Silvermont Module and Caches
Like AMD’s Bobcat and Jaguar designs, Silvermont is modular. The default Silvermont building block is a two-core/two-thread design. Each core is equally capable and there’s no shared execution hardware. Silvermont supports up to 8-core configurations by placing multiple modules in an SoC.
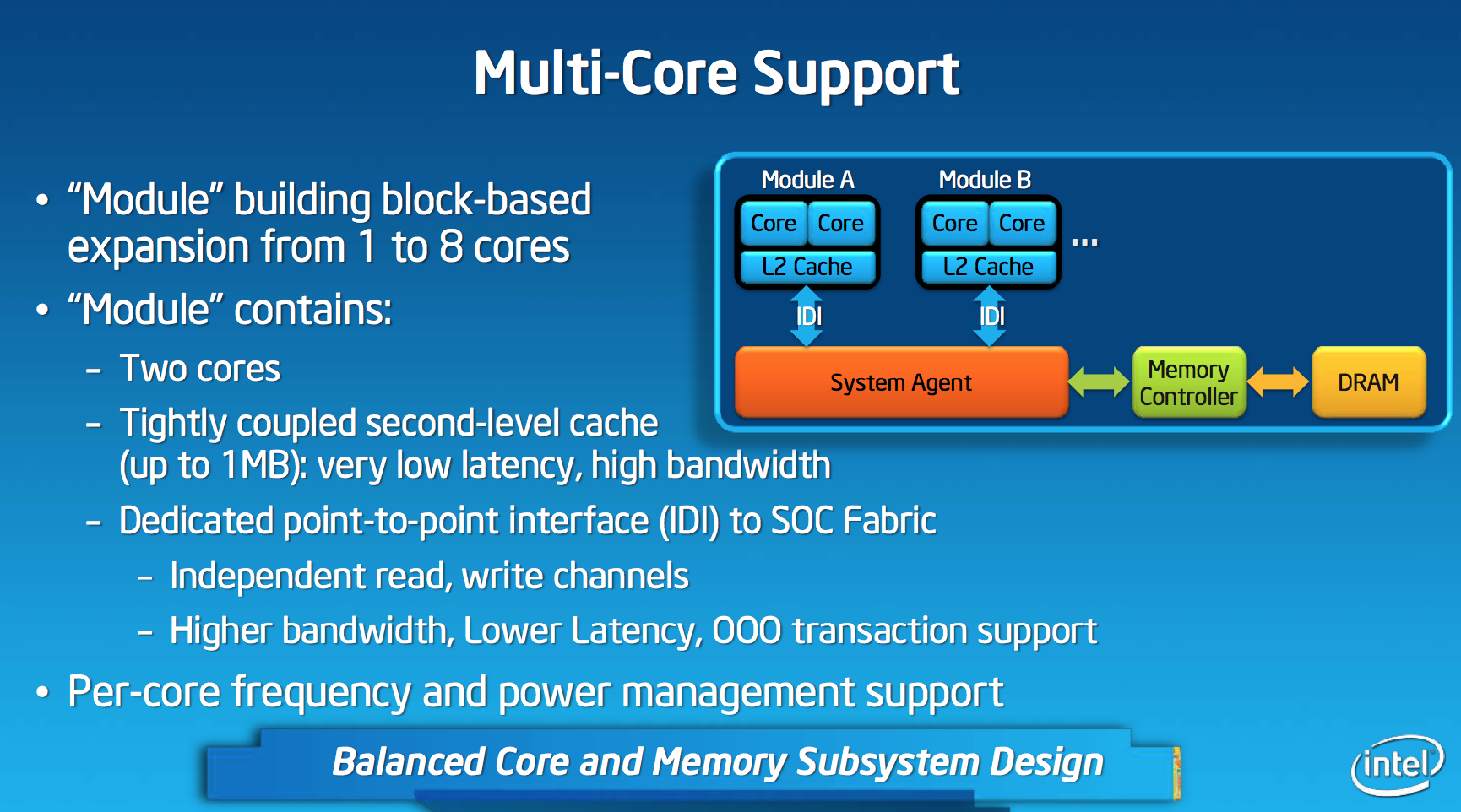
Each module features a shared 1MB L2 cache, a 2x increase over the core:cache ratio of existing Atom based processors. Despite the larger L2, access latency is reduced by 2 clocks. The default module size gives you clear indication as to where Intel saw Silvermont being most useful. At the time of its inception, I doubt Intel anticipated such a quick shift to quad-core smartphones otherwise it might’ve considered a larger default module size.
L1 cache sizes/latencies haven’t changed. Each Silvermont core features a 32KB L1 data cache and 24KB L1 instruction cache.
Silvermont Supports Independent Core Frequencies: Vindication for Qualcomm?
In all Intel Core based microprocessors, all cores are tied to the same frequency - those that aren’t in use are simply shut off (power gated) to save power. Qualcomm’s multi-core architecture has always supported independent frequency planes for all CPUs in the SoC, something that Intel has always insisted was a bad idea. In a strange turn of events, Intel joins Qualcomm in offering the ability to run each core in a Silvermont module at its own independent frequency. You could have one Silvermont core running at 2.4GHz and another one running at 1.2GHz. Unlike Qualcomm’s implementation, Silvermont’s independent frequency planes are optional. In a split frequency case, the shared L2 cache always runs at the higher of the two frequencies. Intel believes the flexibility might be useful in some low cost Silvermont implementations where the OS actively uses core pinning to keep threads parked on specific cores. I doubt we’ll see this on most tablet or smartphone implementations of the design.
From FSB to IDI
Atom and all of its derivatives have a nasty secret: they never really got any latency benefits from integrating a memory controller on die. The first implementation of Atom was a 3-chip solution, with the memory controller contained within the North Bridge. The CPU talked to the North Bridge via a low power Front Side Bus implementation. This setup should sound familiar to anyone who remembers Intel architectures from the late 90s up to the mid 2000s. In pursuit of integration, Intel eventually brought the memory controller and graphics onto a single die. Historically, bringing the memory controller onto the same die as the CPU came with a nice reduction in access latency - unfortunately Atom never enjoyed this. The reasoning? Atom never ditched the FSB interface.
Even though Atom integrated a memory controller, the design logically looked like it did before. Integration only saved Intel space and power, it never granted it any performance. I suspect Intel did this to keep costs down. I noticed the problem years ago but completely forgot about it since it’s been so long. Thankfully, with Silvermont the FSB interface is completely gone.
Silvermont instead integrates the same in-die interconnect (IDI) that is used in the big Core based processors. Intel’s IDI is a lightweight point to point interface that’s far lower overhead than the old FSB architecture. The move to IDI and the changes to the system fabric are enough to improve single threaded performance by low double digits. The gains are even bigger in heavily threaded scenarios.
Another benefit of moving away from a very old FSB to IDI is increased flexibility in how Silvermont can clock up/down. Previously there were fixed FSB:CPU ratios that had to be maintained at all times, which meant the FSB had to be lowered significantly when the CPU was running at very low frequencies. In Silvermont, the IDI and CPU frequencies are largely decoupled - enabling good bandwidth out of the cores even at low frequency levels.
The System Agent
Silvermont gains an updated system agent (read: North Bridge) that’s much better at allowing access to main memory. In all previous generation Atom architectures, virtually all memory accesses had to happen in-order (Clover Trail had some minor OoO improvements here). Silvermont’s system agent now allows reordering of memory requests coming in from all consumers/producers (e.g. CPU cores, GPU, etc...) to optimize for performance and quality of service (e.g. ensuring graphics demands on memory can regularly pre-empt CPU requests when necessary).








174 Comments
View All Comments
Amoro - Monday, May 6, 2013 - link
In the first sentence of the paragraph below the Saltwell Vs. Silvermont graph, it states "In terms of absolute performance, Saltwell’s peak single threaded performance is 2x that of Saltwell" and it should be "Silvermont's peak single...."ClockworkPirate - Monday, May 6, 2013 - link
Also at the end of the first paragraph on the "Tablet Expectations and Performance" page, "...with Haswell picking up above Haswell." should probably be "...with Haswell picking up above Bay Trail."chrone - Monday, May 6, 2013 - link
this is the soc i've been waiting for since 2008. winter is coming!! it's gonna be a long winter for arm and friends ahead. \m/theos83 - Monday, May 6, 2013 - link
lol...wait and watch...it has been a long winter for intel (from a mobile market point of view), lets see what they end up with in the next 4 years...ARM and friends are not going away anytime soon.Hector2 - Friday, May 17, 2013 - link
True. The difference between then and now is that Intel didn't have an SoC designed and optimized for smartphones. Now they do (this year) and it'll be about 22nm & 14nm offering Intel higher performance, lower power and lower cost. In this area Intel has about a 2 year lead on their competitionKrysto - Monday, May 6, 2013 - link
It's very, very, VERY hard to beat a monopoly in a certain market (ARM that is), even with a company like Intel that may have a monopoly in another.Plus they have like a dozen competitors there, with at least 3-4 top ones. Intel has promised a lot of stuff before, and under-delivered. So we'll see. ARM chips are also going 20nm and 64 bit next year, and at 14nm FinFET the year after that (yes, only a year later).
Plus, if these things cost 2-3x what the high-end ARM chips cost, they can just pack and go home. No OEM will accept that, unless Intel gives them Haswell in PC's for 30% off, or some deal like that (which would mean they won't be making any money on these Atoms anytime soon).
klmccaughey - Tuesday, May 7, 2013 - link
Intel has the cash to loss-lead on this and open a big crack into the market. It also has the bucks to advertise.My guess is that shareholders are screaming for Intel to get into this market. All the omens look good and I am really looking forward to a big jump in power and battery life for mobiles. I think ARM finally has a real competitor.
HisDivineOrder - Tuesday, May 7, 2013 - link
Intel (and MS) are still under the delusion they're in the 1990's where they could be a premium vendor. Look at all the Windows tablets for proof of this. Intel and MS are both charging way more than they should and all their Wintel tablets (RT or 8) are overpriced by a huge amount.Intel doesn't loss lead. At least, they haven't shown any sign of it at all. Maybe this will be their moment, but somehow... I really, really doubt it.
zeo - Wednesday, May 8, 2013 - link
Don't confuse Intel with the OEMs and MS, Intel isn't over charging on their hardware!The listed Tray cost for the Clover Trail Z2760 SoC is only $41, at a time when ARM high end SoCs are starting to go over $30... So there's not a multiple times cost difference anymore.
OEMs just mistakenly took their cue from MS pricing of the Surface and it's not like the tablet market is really set up for PC configurations.
OEMs for example are used to using internal drive capacity as a way of charging more of their products. Like it doesn't cost anywhere near $50 to double the drive capacity of a Nexus 7 for example or how Apple charges a $100 for each doubling of capacity.
Remember, Windows tablets start with 32GB and that's much higher minimum than what mobile devices still offer.
Along with inclusion of full size USB ports, the added cost of Windows license, the greater tendency to include premium parts like WACOM digitizers, etc all added together for how the pricing finally came out...
However, the OEMs should have learned their lessons, MS is definitely going to offer them better volume license fees this time around, and Bay Trail is suppose to be even lower priced than Clover Trail... So we should see much better pricing with this new generation of products.
BSMonitor - Wednesday, May 8, 2013 - link
Its not a monopoly. There are several companies that build ARM SoC's. ARM is an ISA, no different than x86. If Intel delivers quantity, better performaning SoC's than the competitors, best believe they will switch. Apple already does x86 in house on OS X. Promise you they have been testing Atom in house for potential future designs.. Whether those designs win over ARM A# in house designs is another matter... Intel is nothing if not good at getting companies to sign up with them.. They deliver the highest quality and highest quantities of anyone in the silicon business.