NVIDIA's GeForce GTX 550 Ti: Coming Up Short At $150
by Ryan Smith on March 15, 2011 9:00 AM ESTGTX 550 Ti’s Quirk: 1GB Of VRAM On A 192-bit Bus
One thing that has always set NVIDIA apart from AMD is their willingness to use non-power of 2 memory bus sizes. AMD always sticks to 256/128/64 bit busses, while NVIDA has used those along with interesting combinations such as 384, 320, and 192 bit busses. This can allow NVIDIA to tap more memory bandwidth by having a wider bus, however they also usually run their memory slower than AMD’s memory on comparable products, so NVIDIA’s memory bandwidth advantage isn’t quite as pronounced. The more immediate ramifications of this however are that NVIDIA ends up with equally odd memory sizes: 1536MB, 1280MB, and 768MB.
768MB in particular can be problematic. When the GTX 460 launched, NVIDIA went with two flavors: 1GB and 768MB, the difference being how many memory controller/ROP blocks were enabled, which in turn changed how much RAM was connected. 768MB just isn’t very big these days – it’s only as big as NVIDIA’s top of the line card back at the end of 2006. At high resolutions with anti-aliasing and high quality textures it’s easy to swamp a card, making 1GB the preferred size for practically everything from $250 down. So when NVIDIA has a 768MB card and AMD has a 1GB card, NVIDIA has a definite marketing problem and a potential performance problem.
| Video Card Bus Width Comparison | ||||||||
| NVIDIA | Bus Width | AMD | Bus Width | |||||
| GTX 570 | 320-bit | Radeon HD 6970 | 256-bit | |||||
| GTX 560 Ti | 256-bit | Radeon HD 6950 | 256-bit | |||||
| GTX 460 768MB | 192-bit | Radeon HD 6850 | 256-bit | |||||
| GTX 550 Ti | 192-bit | Radeon HD 5770 | 128-bit | |||||
| GTS 450 | 128-bit | Radeon HD 5750 | 128-bit | |||||
NVIDIA’s solution is to normally outfit cards with more RAM to make up for the wider bus, which is why we’ve seen 1536MB and 1280MB cards going against 1GB AMD cards. With cheaper cards though the extra memory (or higher density memory) is an extra cost that cuts in to margins. So what do you do when you have an oddly sized 192-bit memory bus on a midrange card? For GTS 450 NVIDIA disabled a memory controller to bring it down to 128-bit, however for GTX 550 Ti they needed to do something different if they wanted to have a 192-bit bus while avoiding having only 768MB of memory or driving up costs by using 1536MB of memory. NVIDIA’s solution was to put 1GB on a 192-bit card anyhow, and this is the GTX 550 Ti’s defining feature from a technical perspective.
Under ideal circumstances when inter leaving memory banks you want the banks to be of equal capacity, this allows you to distribute most memory operations equally among all banks throughout the entire memory space. Video cards with their non-removable memory have done this for ages, however full computers with their replaceable DIMMs have had to work with other layouts. Thus computers have supported additional interleaving options beyond symmetrical interleaving, most notably “flex” interleaving where one bank is larger than the other.
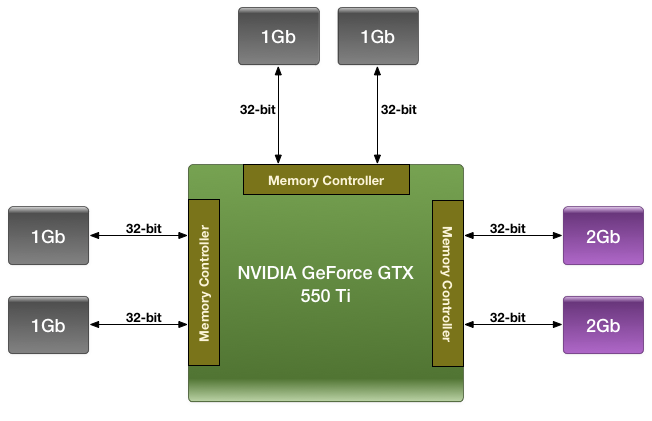
It’s this technique that NVIDIA has adopted for the GTX 550 Ti. GF116 has 3 64-bit memory controllers, each of which is attached to a pair of GDDR5 chips running in 32bit mode. All told this is a 6 chip configuration, with NVIDIA using 4 1Gb chips and 2 2Gb chips. In the case of our Zotac card – and presumably all GTX 550 Ti cards – the memory is laid out as illustrated above, with the 1Gb devices split among 2 of the memory controllers, while both 2Gb devices are on the 3rd memory controller.
This marks the first time we’ve seen such a memory configuration on a video card, and as such raises a number of questions. Our primary concern at this point in time is performance, as it’s mathematically impossible to organize the memory in such a way that the card always has access to its full theoretical memory bandwidth. The best case scenario is always going to be that the entire 192-bit bus is in use, giving the card 98.5GB/sec of memory bandwidth (192bit * 4104MHz / 8), meanwhile the worst case scenario is that only 1 64-bit memory controller is in use, reducing memory bandwidth to a much more modest 32.8GB/sec.
How NVIDIA spreads out memory accesses will have a great deal of impact on when we hit these scenarios, and at this time they are labeling the internal details of their memory bus a competitive advantage, meaning they’re unwilling to share the details of its operation with us. Thus we’re largely dealing with a black box here, which we’re going to have to poke and prod at to try to determine how NVIDIA is distributing memory operations.
Our base assumption is that NVIDIA is using a memory interleaving mode similar to “flex” modes on desktop computers, which means lower memory addresses are mapped across all 3 memory controllers, while higher addresses are mapped to the remaining RAM capacity on the 3rd memory controller. As such NVIDIA would have the full 98.5GB/sec of memory bandwidth available across the first 768MB, while the last 256MB would be much more painful at 32.8GB/sec. This isn’t the only way to distribute memory operations however, and indeed NVIDIA doesn’t have to use 1 method at a time thanks to the 3 memory controllers, so the truth is likely much more complex.
Given the black box nature of GTX 550’s memory access methods, we decided to poke at things in the most practical manner available: CUDA. GPGPU operation makes it easy to write algorithms that test the memory across the entire address space, which in theory would make it easy to determine GTX 550’s actual memory bandwidth, and if it was consistent across the entire address space. Furthermore we have another very similar NVIDIA card with a 192-bit memory bus on hand – GTX 460 768MB – so it would be easy to compare the two and see how a pure 192-bit card would compare.
We ran in to one roadblock however: apparently no one told the CUDA group that GTX 550 was going to use mixed density memory. As it stands CUDA (and other APIs built upon it such as OpenCL and DirectCompute) can only see 768MB minus whatever memory is already in use. While this lends support to our theory that NVIDIA is using flex mode interleaving, this makes it nearly impossible to test the theory at this time as graphics operations aren’t nearly as flexible enough (and much more prone to caching) to test this.
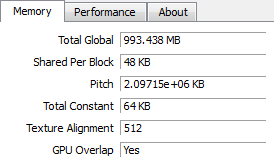
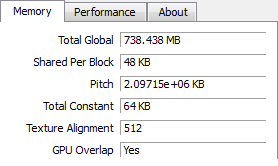
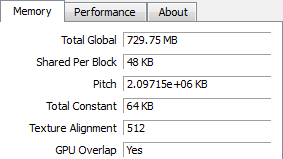
CUDA-Z: CUDA Available Memory. Clockwise, Top-Left: GTS 450, GTX 460 768MB, GTX 550 Ti
At this point NVIDIA tells us it’s a bug and that it should be fixed by the end of the month, however until such a time we’re left with our share of doubts. Although this doesn’t lead to any kind of faulty operation, this is a pretty big bug to slip through NVIDIA’s QA process, which makes it all the more surprising.
In the meantime we did do some testing against the more limited memory capacity of the GTX 550. At this point the results are inconclusive at best. Using NVIDIA’s Bandwidth Test CUDA sample program, which is a simple test to measure memcopy bandwidth of the GPU, we tested the GTS 450, GTX 468 768MB, GTX 460 1GB, and GTX 550 Ti at both stock and normalized (GTX 460) clocks. The results were inconclusive – the test seems to scale with core clocks far more than memory bandwidth – which may be another bug, or an artifact of the program having originally been written pre-Fermi. In any case here is the data, but we have low confidence in it.
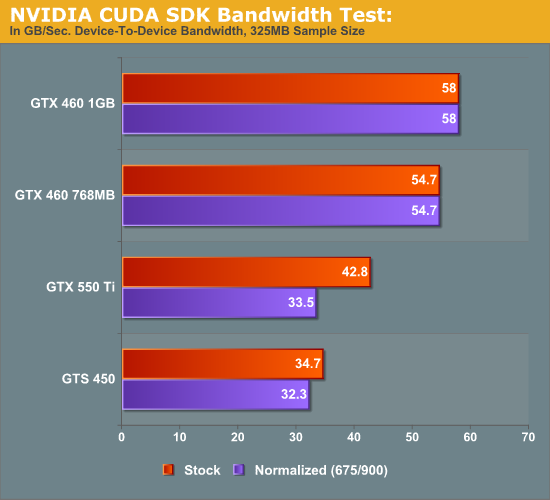
As it stands the test shows almost no gain over the GTS 450 at normalized clocks; this doesn’t make a great deal of sense under any memory interleaving scheme, hence the low confidence. If and when all the bugs that may be causing this are fixed, we’ll definitely be revisiting the issue to try to better pin down how NVIDIA is doing memory interleaving.








79 Comments
View All Comments
Marlin1975 - Tuesday, March 15, 2011 - link
But over priced.If this was in the $100 area it be a much better buy. But the cheaper 460 is better right now.
Also you have the 450 in yoru graph as a 256bit bandwidth, not the 128bit it is.
vol7ron - Tuesday, March 15, 2011 - link
I'm not usually an advocate of OCing gpus, but I'm curious how much more performance could be achieved. We know there's some room in the memory, how much more can the gpu/shaders really extract? While Zotac OCs, they normally don't max it out on air cooling, so a little testing would be nice :)slickr - Tuesday, March 15, 2011 - link
Its a crap card.Its about $50 overpriced, its worse in consumption, noise and coolness than Nvidia's own 1 year old GTS 450.
So how can this be a good card? For the same price I can get a GTX 460 768mb that performs 20% faster and I can get cooler, quieter and less power draw card for $50 less in the 5770 and still get the same performance.
If you ask me this card is a rip off for consumers who don't know anything about graphic cards.
Aircraft123 - Tuesday, March 15, 2011 - link
I really don't understand why nVidia is so concerned with these lower performing cards.Their own cards from TWO GENERATIONS AGO perform better then this "new" card.
I have a GTX275 it will perform equivalent or better than this new card and you can find it on a particular auction site for ~$100.
The only thing missing from my 275, is directX 11. Which unless you get a 470 or greater the card isn't powerful enough to run any dx11 stuff anyway.
I could also say the same for AMD considering the 4870 performs better than the 5770.
I am interested in the dual fermi card due out soon though. It will be interesting if/how they can beat the 6990 with lower power sonsumption/noise.
Anyhow good article.
Marlin1975 - Tuesday, March 15, 2011 - link
The reason is the re-work I bet has a better yeild number, let alone more performance from the same chip with a new series number.So people think they are getting new cutting edge when its just a 4xx series chip re-worked.
Taft12 - Tuesday, March 15, 2011 - link
In fairness, if we are considering dollars and cents your GTX275 has a TDP twice the 550 Ti, and probably eats up double or more at idle as well.jiffylube1024 - Tuesday, March 15, 2011 - link
The GTX 275 costs a lot more to make than the Ti 550 (they couldn't mass manufacture the GTX 275 card at a $100 or even $150 pricepoint and hope to make a profit) and a GTX 275's that you could find for $100 today would either be old stock (meaning they're just clearing inventory) or a used card, meaning no profit for Nvidia whatsoever.It's pretty obvious that companies come out with these cards to occupy lower pricepoints... The problem is that, as you point out, they are often too cut-down and previous generation cards throttle them. It's a balance, and when they hit the right price/performance, magic happens (GTX 460), but they often miss the mark on other cards (GTS 450, Ti 550).
Even if you examine the Ti550 on paper, it stands no chance vs the GTX 460 -- it has 56% less shader power than the GTX 460 (336 shaders vs 192; a similar drop in texturing power) and not enough of a clockspeed advantage (900 MHz vs 675 MHz) to make up for that. At $150, the Ti550 is a total waste since you can find GTX 460's for $130 or less these days. It's going to take a fall below $100 for these cards to become worthwhile.
Nevertheless, if GTX 460 stock dries up, then without a Ti 550, Nvidia has a gaping hole below $250.
I think this has a lot to do with manufacturing costs -- it's not economical to keep making GTX 460's and sell them for ~$100. The Ti 550 has 66.7% the transitor count of the GTX 460, meaning a much cheaper die to manufacture.
Kiji - Tuesday, March 15, 2011 - link
"Indeed the GTX 550 Ti is faster than the 5770 - by around 7% - but then the 5770 costs 36% more." - I think you mean "..36% less."Good review, and it's disappointing NVidia doesn't want to change their mentality.
Kiji - Tuesday, March 15, 2011 - link
Nevermind, already fixed :)passive - Tuesday, March 15, 2011 - link
At the end of page 5 you say that the 550 is ahead of the 5770 by 50%, and at 90% of the 6850. According to your graphs, both of these are very wrong (even when using the Zotacs numbers):23.1 (550) / 19.8 (5770) = 16.6%
23.1 (550) / 29.8 (6850) = 77.5%
What's weird is that immediately after you say how the 550 is beating the 450 by 30%, which is accurate, but further paints a pro-Nvidia picture.
I know we live in era of community edited content, but in order to prevent accusations of bias, you should really catch this before you publish.