Understanding the iPhone 3GS
by Anand Lal Shimpi on July 7, 2009 12:00 AM EST- Posted in
- Smartphones
- Mobile
A Crash Course in CPU Architecture
It’s been years since I’ve gone through the life of an instruction, and when I last did it it was about a very high end desktop processor. I realize that not everyone interested in what’s powering the iPhone 3GS or Palm Pre may have been taken down this path, so I thought some of that knowledge might be useful here.
Applications spawn threads, threads are made up of instructions and instructions are what a CPU “processes”. The actual processing of an instruction is pretty simple; the CPU must fetch the instruction from memory, decode or somehow understand what the instruction is telling it to do (e.g. add two numbers), grab any data that is required by the instruction (e.g. find the numbers to be added), actually execute the instruction and finally write the result of the operation either to a register or memory.
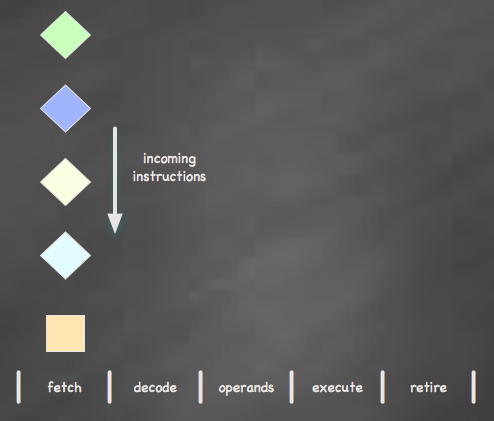
Our basic microprocessor with a 5-stage pipeline
Based on the example above, executing an instruction requires five distinct stages. In a pipelined microprocessor, a different instruction can be active at each stage of the execution pipeline. For example, you can be grabbing data for one instruction, while decoding another and fetching yet another. All modern day processors work this way.
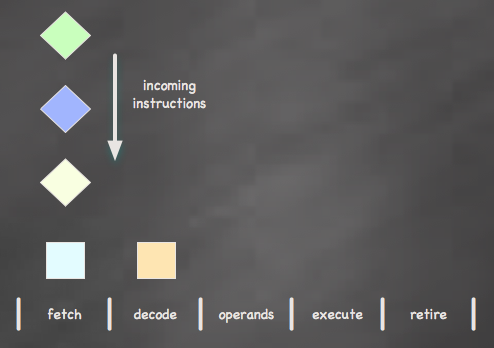
Multiple instructions can exist in the pipeline at once, but only one instruction may be active at any given stage
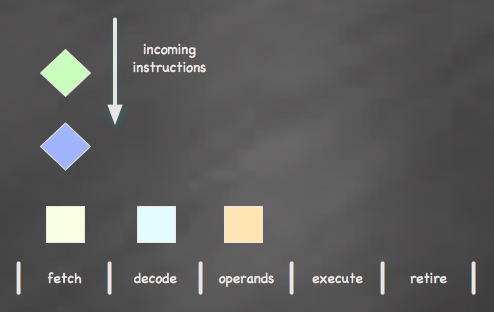
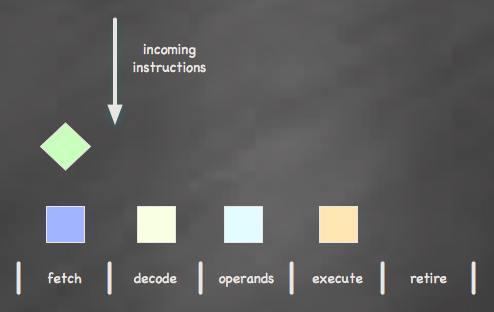


Each one of these stages should take the same amount of time for the processor to work efficiently; the length of time required at the longest stage actually determines the clock speed of the CPU. If the most complex stage in my example above is the decode stage and it requires 3ns to complete, then my CPU can run no faster than 333MHz (1 / 3ns).
To reach faster frequencies, we need to speed up each stage of the pipeline. You can speed up a stage by implementing some sweet new algorithms, or simply by splitting up complicated stages into simpler ones and increasing the number of stages in your pipeline.
In our previous example, the decode stage required 3ns to complete but if we split decode into three separate stages, each requiring 1ns, then we remove that bottleneck. Let’s say we do that but now some of our other stages become the bottleneck; with a target of a 1ns clock period (1ns spent per stage) we go from five stages to eight:
Fetch
Decode 1
Decode 2
Decode 3
Fetch Operands
Execute 1
Execute 2
Write Output
Now, with each stage running at 1ns, our maximum clock speed goes up from 333MHz to 1000MHz (1GHz). Sweet. Right?
With less work being done in each stage, we reach a higher clock speed, but we also depend on each stage being full in order to operate at peak efficiency.

5-stage pipeline (top) vs 8-stage pipeline (bottom). The 8 stage pipe is more desirable, but also requires more instructions to fill.
In the first CPU example we had a 5 stage pipeline, which meant that we needed to have the pipe full of 5 instructions at any given time to be operating at peak efficiency of 1 instruction completed every cycle. The second example has a ginormous 8 stage pipeline, which requires 8 instructions in the pipe for peak efficiency. In both cases you can only get one instruction out of the pipe every cycle, but the second chip can give us more completed instructions in say, 10 seconds.
Now think for a moment about the time periods we’re talking about here. The first CPU had a clock period of 3ns, where each stage took 3ns to complete. The second CPU had a clock period of 1ns. A single trip to main memory can easily take 60ns for a CPU with a very fast on-die memory controller, or over 100ns otherwise. For the sake of argument let’s say that we’re talking about a 100ns trip to main memory. Remember the Fetch Operands stage? Well if those operands are located in main memory that stage won’t take 3ns to complete, but rather 103ns since it has to get the operands from main memory.
Modern processors will perform a context switch upon any memory access to avoid stalling the pipeline for such an absurd length of time. The contents of the pipeline get flushed and filled with another thread while the data request goes off to main memory. Once the data is ready, the processor switches contexts once more and continues on its execution path. Here’s the problem: it takes time to refill the pipeline, and the longer the pipeline, the longer it takes to refill it. This is a bad, but regular occurrence in a microprocessor. Our instruction throughput drops from its 1 instruction per clock peak to 0; not good.
Other scenarios can create interruptions in the normal flow of things within our microprocessor. Some instructions may take multiple cycles at a single stage to complete. More complex arithmetic may spend significantly longer at the execute stage while the operation works out. With an in-order microprocessor, all instructions behind it must wait.
Again, the more stages in your pipeline, the bigger the penalty for a stall. But when the pipeline is full, a deeper pipeline will give us a higher clock speed and better overall performance - we just need to worry about keeping the pipeline full (which takes a great deal of additional transistors). And yes, there is an upper limit to how deep you can pipeline your processor before you start running into diminishing returns in both a performance and power sense, this was ultimately the downfall of the Pentium 4’s architecture.








60 Comments
View All Comments
lightzout - Saturday, July 11, 2009 - link
My wife actually offered to give me her 3g if she got the the 3gs but I didnt think it was worth it. She asked me this morning how it was better and I didnt know (didnt admit it of course)Now I want her 3G "free" and she really does need the 3gs since since is always multitasking/social/mail..me, including aim.
I thought the 3gs would have some radical new gps stuff but the compass is not impressive. Nothing to get me geeked on to the tune of $200. For my purposes having the older iphone would make travel and remodeling job estimating easier over my tattered razr.
My media mogul mamacita however needs that sleek new 3gs like yesterday as every gripe she has about the 3g phone seems to have been addressed somehow.
Great write-up!
Only regret is when I saw the new screen and sleek size of the 3gs at the apple store a couple days ago it does screem "arent I beautiful?" but that is what apple does so well right?
MrBowmore - Saturday, July 11, 2009 - link
Give the magic, or hero another chance!Your numbers for those phones are whacked, its faster than the 3G at alot of things. Try to kill all the backgroundapps. (yes, it multitasks)
RadnorHarkonnen - Friday, July 10, 2009 - link
Very good analisys.I was just surprised ARM CPUs still made on 90nm and 65nm. With the performance and power saving 55nm and 45 nm processes i would imagine they would jump the bandwagon fast.
nubie - Thursday, July 9, 2009 - link
Some people can't drop $600 in a lump or $2600 over 3 years on something as stupid as a cellphone. No matter what it can do.Besides the fact that Apple is killing all support for proper hardware acceleration and access to OpenGL 2.0, whatever.
Can we get more Android and G1 coverage? Please?
psonice - Friday, July 10, 2009 - link
Like the guy above said, you buy a phone, you either pay a lot upfront, or you get it with a contract. Either way you'll still need to pay a ton of money each month to for your voice and data. You could get a cheap phone that only makes calls and costs almost nothing, but that's not the same is it?And what's this about apple not supporting hardware acceleration / opengl es 2.0??? Almost everything in the gui is hardware accelerated. And there's very good opengl es 1.1/2.0 support in the sdk, hence the ton of hardware accelerated games. There may not be much supporting es2.0 yet, but that's because the first 2.0 capable device has only just been released.
Affectionate-Bed-980 - Friday, July 10, 2009 - link
You know what? The cost is:$199 up front
$70 / year * 24 months
= $1680 + $199
But let's face it, most of you already have cell phones. A quick look at a WinMo phone like the HTC Touch Pro is $70 / month too at minimum ($39.99 voice + $30 data. Same with a Blackberry.
SO WHY THE HELL ARE YOU COMPLAINING?
So if $1880 is too much for you, don't get a cell phone period.
Stop complaining. The iPhone is actually pretty damn cheap. You're locked in a contract, but even if you had another phone WHY WOULD YOU GO DATALESS?
araczynski - Thursday, July 9, 2009 - link
i'll care about the iphone/ipod when they start sporting VGA screens. if my digital camera can have a 3" 640x480 display, so should these overpriced toys.psonice - Friday, July 10, 2009 - link
Higher res screens look pretty, but 640x480 needs 2x more power to fill than 480x320. The screen is more than acceptable already, so I'd take faster running apps/games and longer battery life over more pixels any day.Kougar - Thursday, July 9, 2009 - link
Thanks for the informative crash course in CPU instructions, that filled in some gaps I didn't understand. It's nice to now understand how some aspects of the design fit into or affect the rest of the design.Unfortunately, you've only drummed up the excitement factor for Intel's Sandy Bridge... from some general info that's been around and based on what you've given it sound like the potential is very much there for some very significant performance jumps. So much for Gulftown's allure!
christinme7890 - Thursday, July 9, 2009 - link
I love the attention to detail when describing the CPUs and the graphics processor and stuff. Very cool. I hate that other people are dissing the iphone hardware. If you don't like Macs rules get a pre. Plain and simple. I for one support these people that want to sell their apps for a good price and are trying to make it big in the dev world. Kudos and I will buy your apps.I will be honest, I am sick of the multitasking argument. You do hit on a point that needs to be addressed imho by Apple and that is that there is no good app for chatting. I really think that Apple needs to include their own IM App that stays on in the background (if you want it to) and collects all your SMS, MMS, IM, facebook, Twitter, etc messages. This would be great. While it would be great I recognize that this would totally sap the power on the iphone. If you had all this info push to your phone, the servers would be constantly sending you messages every second. As for multitasking, I don't really care to have it. There are areas where I wish I had it but it is not necessary. Not to mention that the palm pre has a horrible battery life...plain horrible. I hear people talk like they need 3 backup batteries just to get through the day.
I have noticed myself that the compass is a little sketchy. There was a time on 07/04 that a friend and I were lost in the city walking around and we used my maps app to find where we are and I tried to get the compass to work to make reading the map easy and it wouldn't work. The map wouldn't rotate and it was frustrating. Oh well.
Your review of the camera was spot on. It will never replace my uber camera but when I am out and about doing whatever it does great for quick and easy pics. And the movie functions are awesome as well. Now if only you could cut out middle pieces of a movie. Hopefully soon.
I love the speed of the 3gs. I notice, not tested but notice, a large speed increase and I absolutely love it.
The one major place the 3GS has over the pre is the App store. No company has been able to implement an app store like Apple. I get all my multimedia from one source (itunes) which is great....Movies, podcasts, video, audio, apps, etc...all in one place is the best thing that apple has done in forever. I will not argue prices or app submission ethics because I truly believe that apple keeps the People as their top priority.
Great article.