The Apple iPad Pro Review
by Ryan Smith, Joshua Ho & Brandon Chester on January 22, 2016 8:10 AM ESTSoC Analysis: On x86 vs ARMv8
Before we get to the benchmarks, I want to spend a bit of time talking about the impact of CPU architectures at a middle degree of technical depth. At a high level, there are a number of peripheral issues when it comes to comparing these two SoCs, such as the quality of their fixed-function blocks. But when you look at what consumes the vast majority of the power, it turns out that the CPU is competing with things like the modem/RF front-end and GPU.
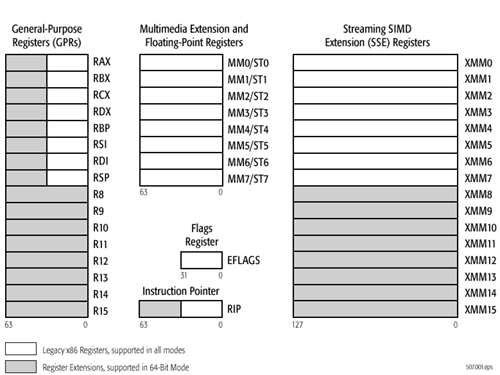
x86-64 ISA registers
Probably the easiest place to start when we’re comparing things like Skylake and Twister is the ISA (instruction set architecture). This subject alone is probably worthy of an article, but the short version for those that aren't really familiar with this topic is that an ISA defines how a processor should behave in response to certain instructions, and how these instructions should be encoded. For example, if you were to add two integers together in the EAX and EDX registers, x86-32 dictates that this would be equivalent to 01d0 in hexadecimal. In response to this instruction, the CPU would add whatever value that was in the EDX register to the value in the EAX register and leave the result in the EDX register.
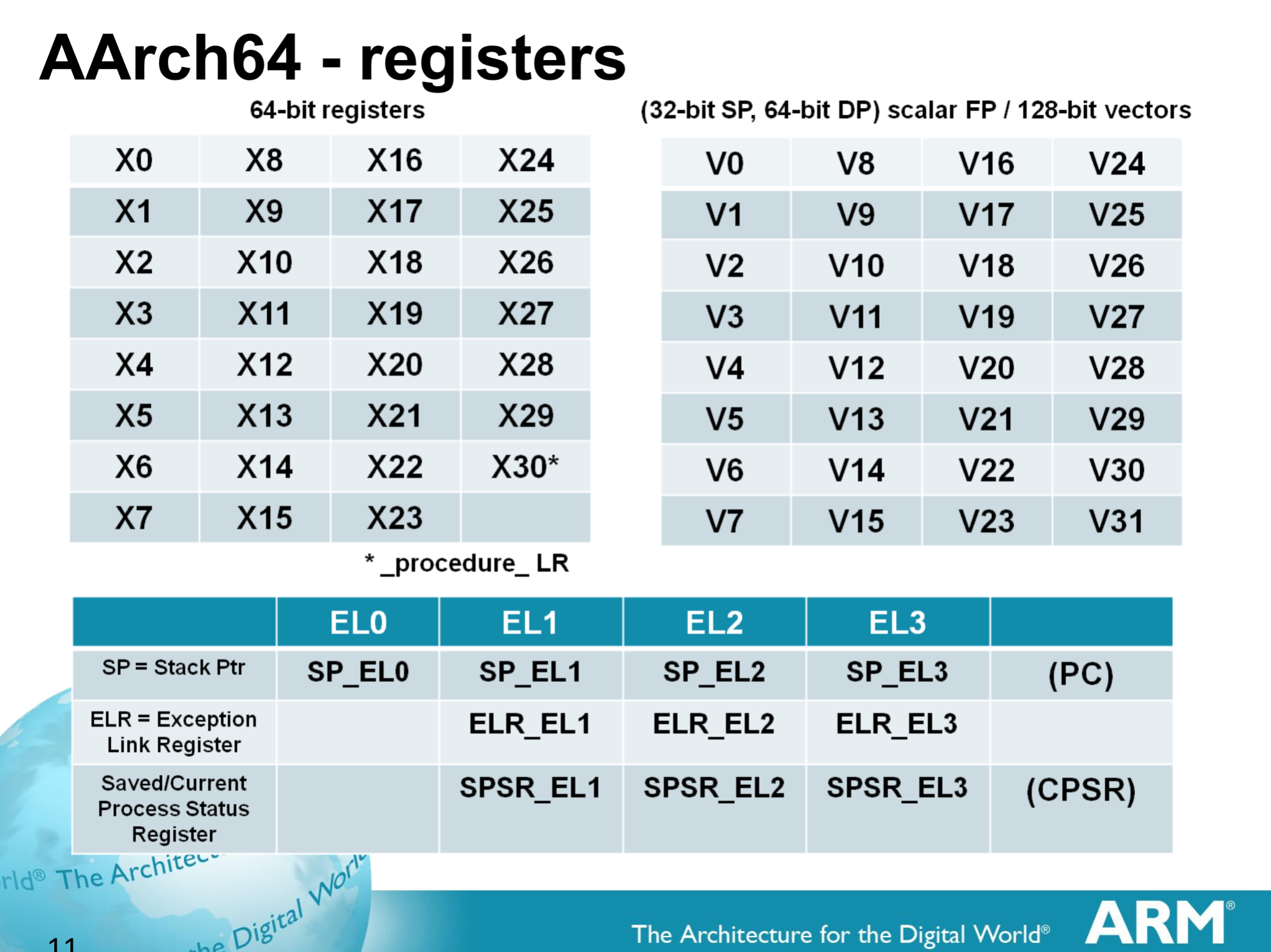
ARMv8 A64 ISA Registers
The fundamental difference between x86 and ARM is that x86 is a relatively complex ISA, while ARM is relatively simple by comparison. One key difference is that ARM dictates that every instruction is a fixed number of bits. In the case of ARMv8-A and ARMv7-A, all instructions are 32-bits long unless you're in thumb mode, which means that all instructions are 16-bit long, but the same sort of trade-offs that come from a fixed length instruction encoding still apply. Thumb-2 is a variable length ISA, so in some sense the same trade-offs apply. It’s important to make a distinction between instruction and data here, because even though AArch64 uses 32-bit instructions the register width is 64 bits, which is what determines things like how much memory can be addressed and the range of values that a single register can hold. By comparison, Intel’s x86 ISA has variable length instructions. In both x86-32 and x86-64/AMD64, each instruction can range anywhere from 8 to 120 bits long depending upon how the instruction is encoded.
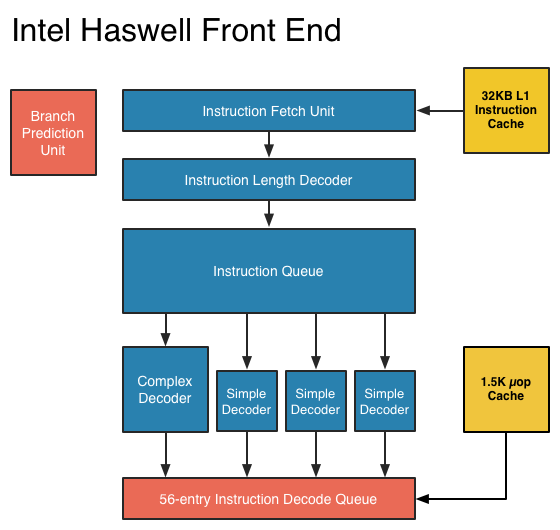
At this point, it might be evident that on the implementation side of things, a decoder for x86 instructions is going to be more complex. For a CPU implementing the ARM ISA, because the instructions are of a fixed length the decoder simply reads instructions 2 or 4 bytes at a time. On the other hand, a CPU implementing the x86 ISA would have to determine how many bytes to pull in at a time for an instruction based upon the preceding bytes.
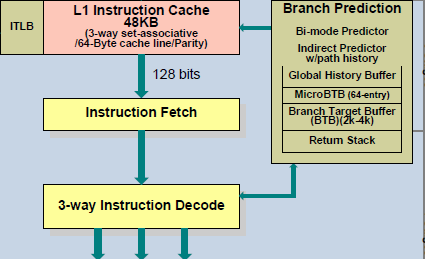
A57 Front-End Decode, Note the lack of uop cache
While it might sound like the x86 ISA is just clearly at a disadvantage here, it’s important to avoid oversimplifying the problem. Although the decoder of an ARM CPU already knows how many bytes it needs to pull in at a time, this inherently means that unless all 2 or 4 bytes of the instruction are used, each instruction contains wasted bits. While it may not seem like a big deal to “waste” a byte here and there, this can actually become a significant bottleneck in how quickly instructions can get from the L1 instruction cache to the front-end instruction decoder of the CPU. The major issue here is that due to RC delay in the metal wire interconnects of a chip, increasing the size of an instruction cache inherently increases the number of cycles that it takes for an instruction to get from the L1 cache to the instruction decoder on the CPU. If a cache doesn’t have the instruction that you need, it could take hundreds of cycles for it to arrive from main memory.
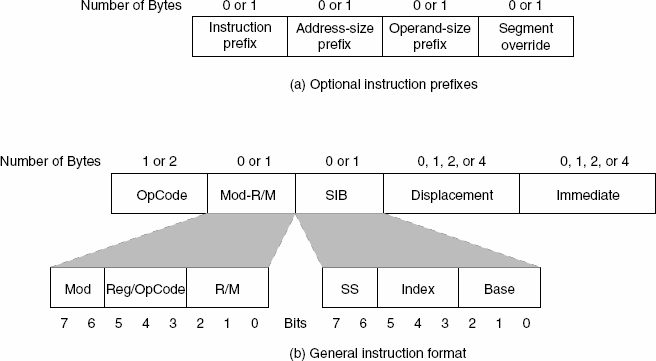
Of course, there are other issues worth considering. For example, in the case of x86, the instructions themselves can be incredibly complex. One of the simplest cases of this is just some cases of the add instruction, where you can have either a source or destination be in memory, although both source and destination cannot be in memory. An example of this might be addq (%rax,%rbx,2), %rdx, which could take 5 CPU cycles to happen in something like Skylake. Of course, pipelining and other tricks can make the throughput of such instructions much higher but that's another topic that can't be properly addressed within the scope of this article.
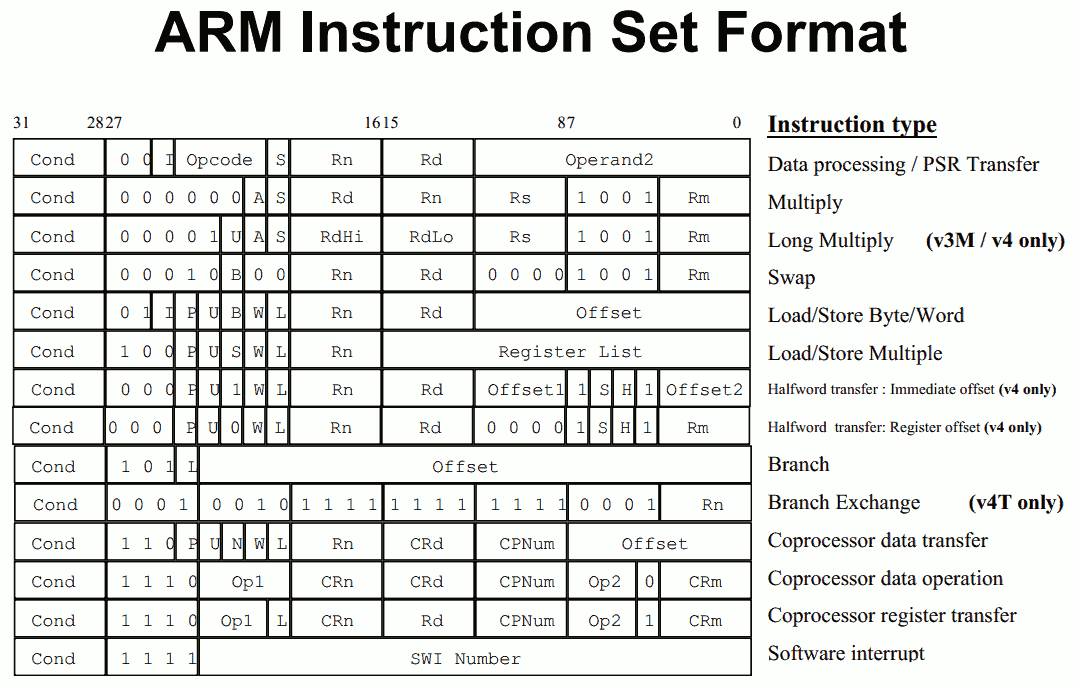
By comparison, the ARM ISA has no direct equivalent to this instruction. Looking at our example of an add instruction, ARM would require a load instruction before the add instruction. This has two notable implications. The first is that this once again is an advantage for an x86 CPU in terms of instruction density because fewer bits are needed to express a single instruction. The second is that for a “pure” CISC CPU you now have a barrier for a number of performance and power optimizations as any instruction dependent upon the result from the current instruction wouldn’t be able to be pipelined or executed in parallel.
The final issue here is that x86 just has an enormous number of instructions that have to be supported due to backwards compatibility. Part of the reason why x86 became so dominant in the market was that code compiled for the original Intel 8086 would work with any future x86 CPU, but the original 8086 didn’t even have memory protection. As a result, all x86 CPUs made today still have to start in real mode and support the original 16-bit registers and instructions, in addition to 32-bit and 64-bit registers and instructions. Of course, to run a program in 8086 mode is a non-trivial task, but even in the x86-64 ISA it isn't unusual to see instructions that are identical to the x86-32 equivalent. By comparison, ARMv8 is designed such that you can only execute ARMv7 or AArch32 code across exception boundaries, so practically programs are only going to run one type of code or the other.
Back in the 1980s up to the 1990s, this became one of the major reasons why RISC was rapidly becoming dominant as CISC ISAs like x86 ended up creating CPUs that generally used more power and die area for the same performance. However, today ISA is basically irrelevant to the discussion due to a number of factors. The first is that beginning with the Intel Pentium Pro and AMD K5, x86 CPUs were really RISC CPU cores with microcode or some other logic to translate x86 CPU instructions to the internal RISC CPU instructions. The second is that decoding of these instructions has been increasingly optimized around only a few instructions that are commonly used by compilers, which makes the x86 ISA practically less complex than what the standard might suggest. The final change here has been that ARM and other RISC ISAs have gotten increasingly complex as well, as it became necessary to enable instructions that support floating point math, SIMD operations, CPU virtualization, and cryptography. As a result, the RISC/CISC distinction is mostly irrelevant when it comes to discussions of power efficiency and performance as microarchitecture is really the main factor at play now.








408 Comments
View All Comments
willis936 - Monday, January 25, 2016 - link
I am very interested in energy per calculation comparisons between the A9X and the Core M. Yes Core M will beat out the A9X from a power perspective but are both within the same power budget? If so then Intel has done some impressive work.Constructor - Monday, January 25, 2016 - link
That's not even cut and dried. The Anandtech performance comparison leaves quite a number of question marks. It looks a lot as if some of the tests were written originally so autovectorization would work with known desktop compilers but LLVM for iOS just didn't catch on to it.The drastic swings between the various tests are not very plausible otherwise.
Which makes that comparison utterly useless if that's the case. And that the testers didn't even bother to check the generated code is highly disappointing.
Icecreamfarmer - Monday, January 25, 2016 - link
I just registered to post this but I have a question?How so cant you draw diagonal lines with a surface 3?
I just tried it several times with and without ruler but they are flawless?
Could you explain?
VictorBd - Tuesday, January 26, 2016 - link
Surface diagonals: The MS N-Trig pen tech manifests a subtle but distinct anomaly when drawing slow diagonal lines in that the lines waver a bit. If you search on this you can see it demonstrated. It is a genuine defect in the current tech. For my use case it is not a concern. I use the pen extensively for interview and meeting note taking (and for light sketching for fun).For my own purposes, the SP4 provides the most compelling overall device available on the market at this time: the power, form factor, desktop docking, OS and apps, ports, and pen when taken all together cannot be matched. It is my primary device every day all day.
At night when I just want to consume web, video, or music, I use an iPad Air 2. Perfect for that. I bought and returned an iPad Pro. I could never try to do production work on it. And it's price and bulk are not worth the beauty of its screen. So I'm keeping the Air for casual consumption. But for work its the SP4 (with a Toshiba dynaPad as a light backup).
Constructor - Tuesday, January 26, 2016 - link
There also seem to be problems properly following the pen near the edges of the screen, even requiring calibration by the user, apparently.The Apple Pencil has neither of those problems. It works very precisely and consistently in any direction and right up to the edges.
VictorBd - Tuesday, January 26, 2016 - link
I initially had pen issues at the edge with the SP4, but it was completely resolved for me by a pen calibration reset. The only thing left is the subtle diagonal - which does not impact me.I also note that the iPad's palm rejection isn't perfect. It allowed my palm to make marks on the screen in OneNote, and it will register finger input as drawing from your "non pen hand" as well in some apps. And right now there's no way to switch off touch input while using the pen so you can grab it however you want. (Another IOS "protected garden" limitation.)
Constructor - Tuesday, January 26, 2016 - link
Nope. The Procreate app, for instance, ignores my fingers completely for any drawing tools but I can still simultaneously draw with the Pencil and operate the UI with my fingers (such as the opacity and size sliders, or the two- and three-finger undo/redogestures.That bit about the "protected garden" is pure rubbish – iOS provides separate APIs for the Pencil and apps already make use of that.
By the way: Palm rejection (in apps where you can't disable finger touch drawing on the canvas) can be trained to some degree. if you're setting your palm clearly on the glass with a larger area touching the surface, it works best. Avoid just light touches with a knuckle of your pinkie finger, for instance (which is when palm rejection can't distinguish it from an intended finger touch), but actually fully rest your hand on the glass for drawing and trust palm rejection to filter that out.
VictorBd - Tuesday, January 26, 2016 - link
Glad to hear that Procreate has done it right. Users will benefit greatly if other apps follow suit. Until they do (and many likely will not)On my other point, I think it unlikely that Apple will either provide or allow others to provide (in the controlled garden of the app store) a utility that toggles the touch input off and on while using the pen. If you haven't used a pen tablet with this feature it may not be obvious at first. But many of those who do discover and use it find it to be a "game changer." All of a sudden your tablet can be handled like a physical piece of paper without any concern for unintended touch inputs. It is the first thing I install on a pen tablet. If iPad Pro had it the experience for me would greatly improve. But I predict that Apple won't allow it. But there is much to the iPad Pro to love no doubt.
VictorBd - Tuesday, January 26, 2016 - link
EDIT: "Until they do.... I don't think Apple will allow the touch toggle ability....."Constructor - Tuesday, January 26, 2016 - link
Your theory is completely wrong. Apple doesn't "disallow" anything!Any app can distinguish between passive finger touch and active Pencil dtection at their own discretion. The APIs already provide that distinction, and I have no idea where you get that idea from that Apple would have any interest to interfere with that.
Again: In Procreate I can simultaneously draw with the Pencil and during the same time move the size slider with a finger while the Pencil keeps drawing – there is no "toggling" of any kind.
It is purely on the application to decide how to treat fingers on the one hand (ahem) and the Pencil on the other – and both are clearly distinguishable at the same time!