Understanding Qualcomm's Snapdragon 810: Performance Preview
by Joshua Ho & Andrei Frumusanu on February 12, 2015 9:00 AM EST- Posted in
- SoCs
- Qualcomm
- Mobile
- Gobi
- Snapdragon 810
Energy Aware Scheduler
Although big.LITTLE has been around for a few years at this point, it’s still worth going over the basics of big.LITTLE in mobile SoCs. Fundamentally, the smartphone SoC space has benefited greatly from playing catch-up to the PC space. At first, SoCs were on lagging process nodes and CPUs were simple and almost entirely in-order in nature. For the first few years, doubling CPU performance every year was possible by adding additional cores, increasing clock speeds, widening the pipeline, and jumping down a process node.
Once we reached the limit for optimizing in-order architectures, the only way to improve performance in a meaningful way was to focus on avoiding stalls in the CPU pipeline. In an in-order CPU architecture, any missing information for executing an instruction means that the CPU must wait for the information to arrive from DRAM or some other storage. Even if a CPU executes incredibly quickly otherwise, it is stuck waiting on dependencies that can significantly degrade performance.
The solution is to execute operations out-of-order. After all, if you have to build a PC, you don’t sit around waiting a few weeks for a graphics card to arrive before building the rest of the PC. Similarly, modern CPUs execute instructions out-of-order to improve performance and avoid stalls. However, implementing this logic in a CPU is far from a trivial matter, as a CPU has to be designed to know which instructions can be executed out-of-order and which must be executed in order. Even instructions with dependencies that have yet to be resolved can be executed speculatively, which can save a great deal of time if the results of this speculation are used. As a result of this speculative execution and the logic needed to implement out-of-order execution (OoOE), the number of transistors and interconnects grows dramatically, which means power consumption grows dramatically as well.
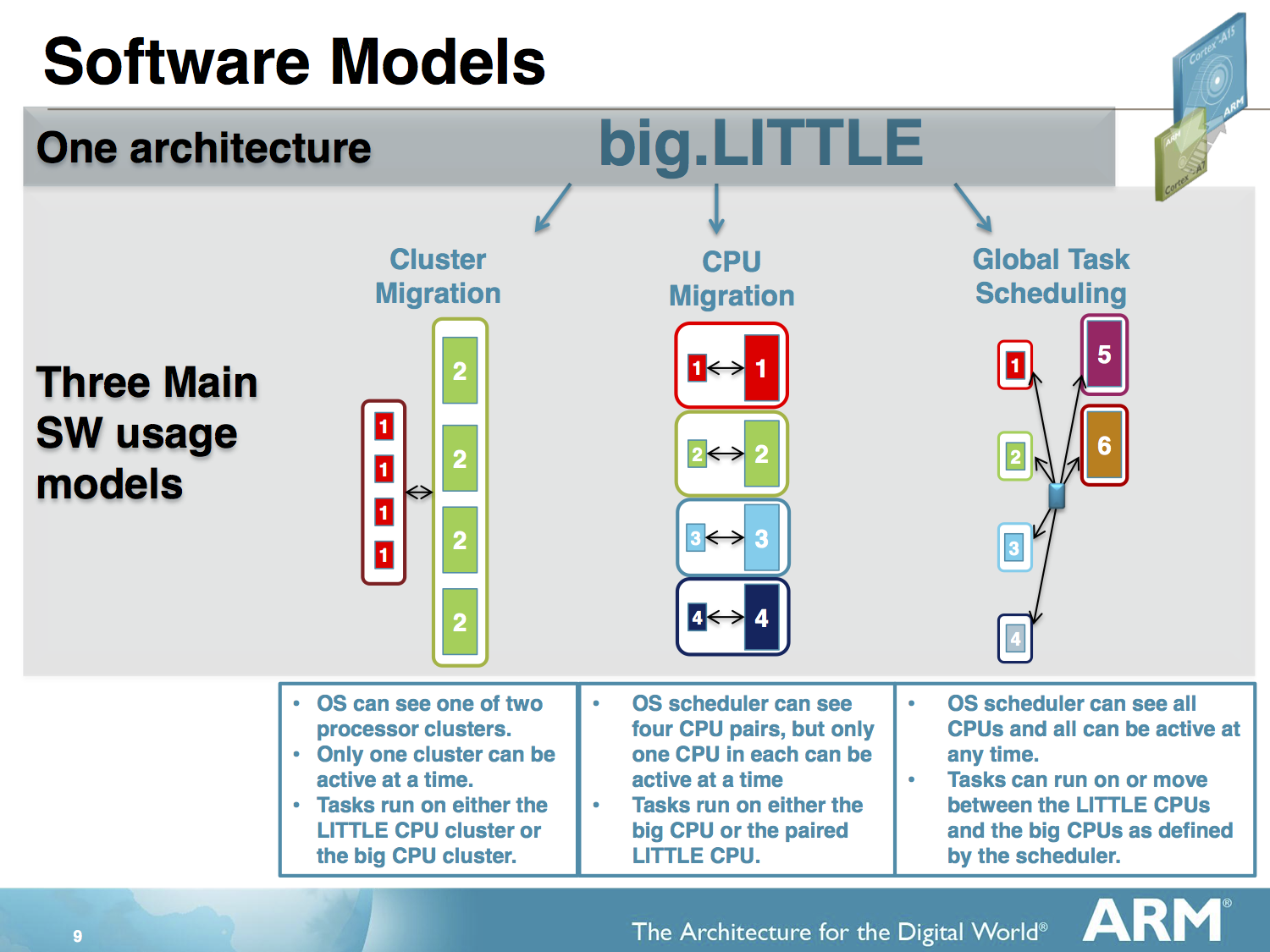
It is in the context of this fundamental problem that big.LITTLE came to be. While there are multiple solutions to solving the power problem that comes with OoOE, ARM currently sees big.LITTLE as the best solution. Fundamentally, big.LITTLE seeks to use in-order, low power processors for the vast majority of computing in mobile, but switches tasks to big, out-of-order processors when a task is too much for the little cores to handle. In theory, this seems to be the ideal solution as it makes it possible to retain the power-saving advantages of in-order cores and the performance advantages of big OoOE cores.
Meanwhile it should be noted that there are other ways of using two heterogeneous CPU clusters, such as cluster migration, which was employed in the first Samsung Exynos bL SoCs and is still employed in NVIDIA's Tegra X1. But for now we will only focus on big.LITTLE HMP operation, which allows all cores to be active and exposed to the operating system. To translate this simple idea into reality is a difficult task. Currently, the de-facto solution in the mobile space for big.LITTLE is the ARM and Linaro developed Global Task Scheduling, which relies on a per-entity load tracking (PELT) mechanism with two load thresholds that decide if a process should be migrated to a corresponding cluster.
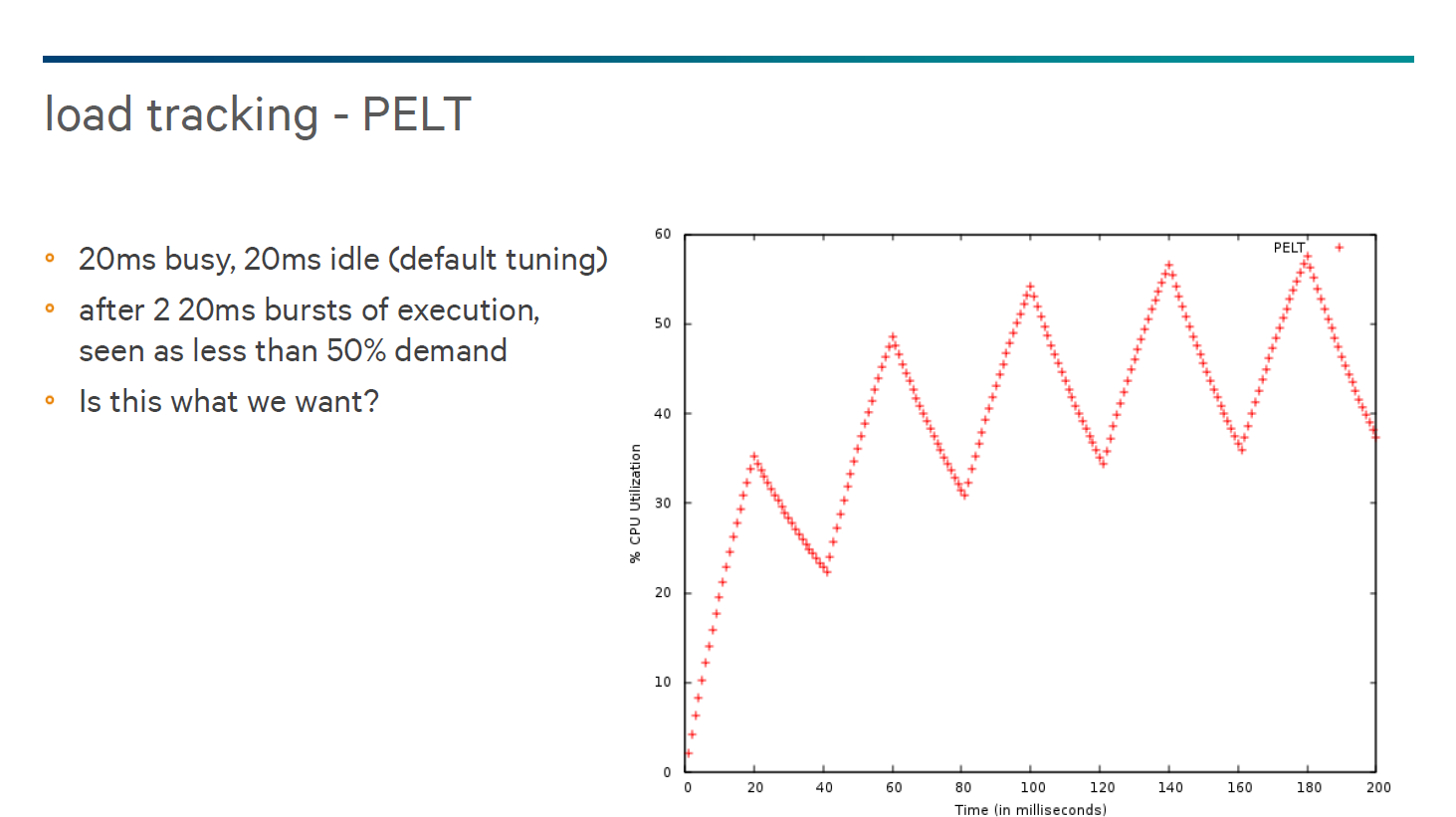
There’s a significant amount of terminology flying around regarding how this works, and we've covered the mechanic in our Huawei Honor 6 review and more in depth in our recent ARM A57/A53 investigation of the Galaxy Note 4 with the Exynos 5433. To recap, at its core, the per-entity load tracking is the main mechanism at hand needed to make thread placement work in GTS.
This system is designed to track load per task by weighting recent load the greatest, and slowly reducing the impact of previous load by a decay factor, which is a geometric series by default. Unfortunately, this load metric does have some disadvantages. Primarily, if a task idles for a long period of time and suddenly demands a significant load, in a race to sleep scenario per-entity load tracking can take a significant amount of time to reach a given up differential to migrate a thread from the small cores to the big cores. Similarly, it can take a significant time for a system with per-entity load tracking system to view a task that has reached idle to migrate a task down to the little cores. This system is also completely unaware of the real-world energy characteristics of the CPU cores, as load is the only real consideration that comes into the scheduler.
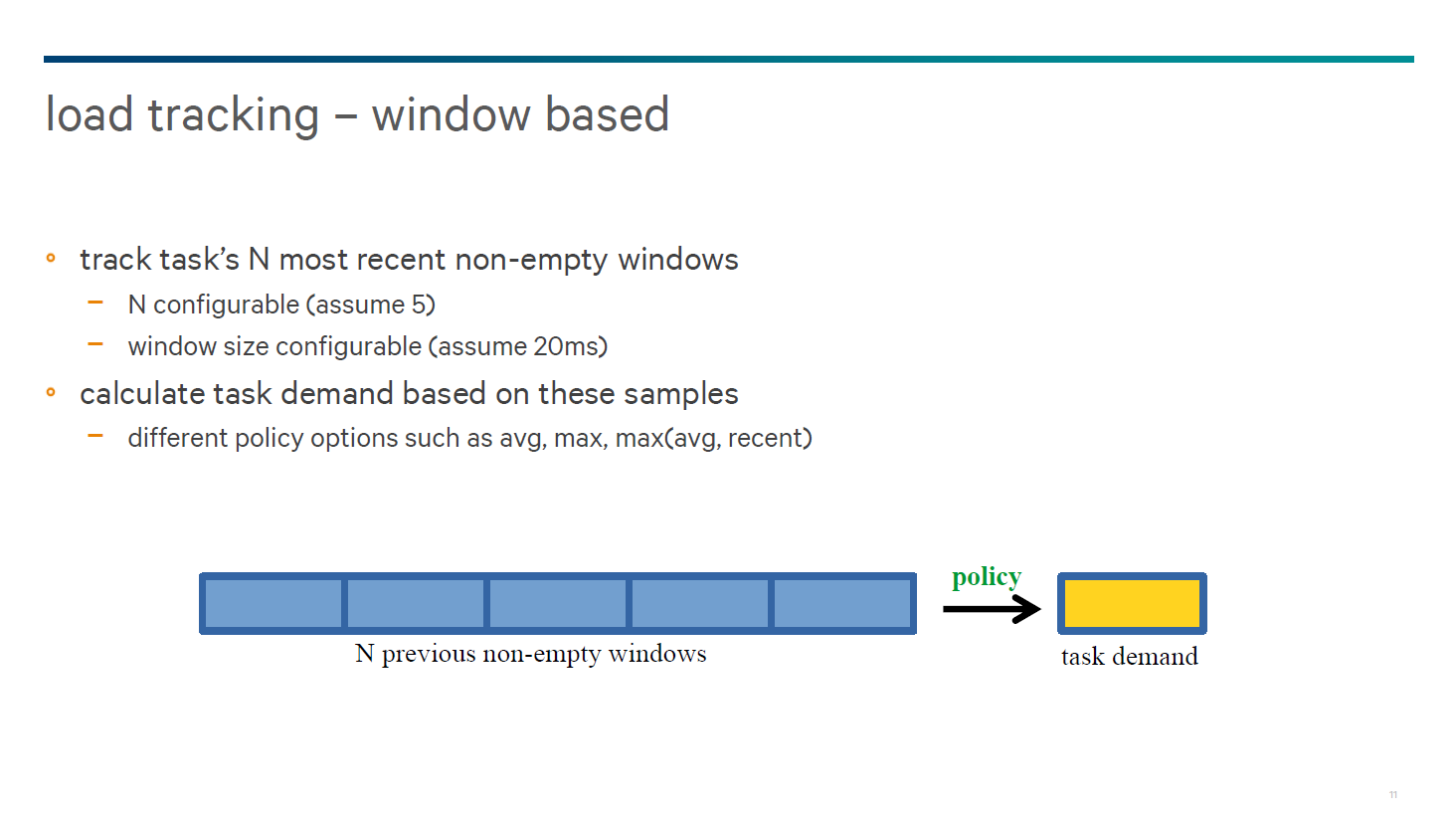
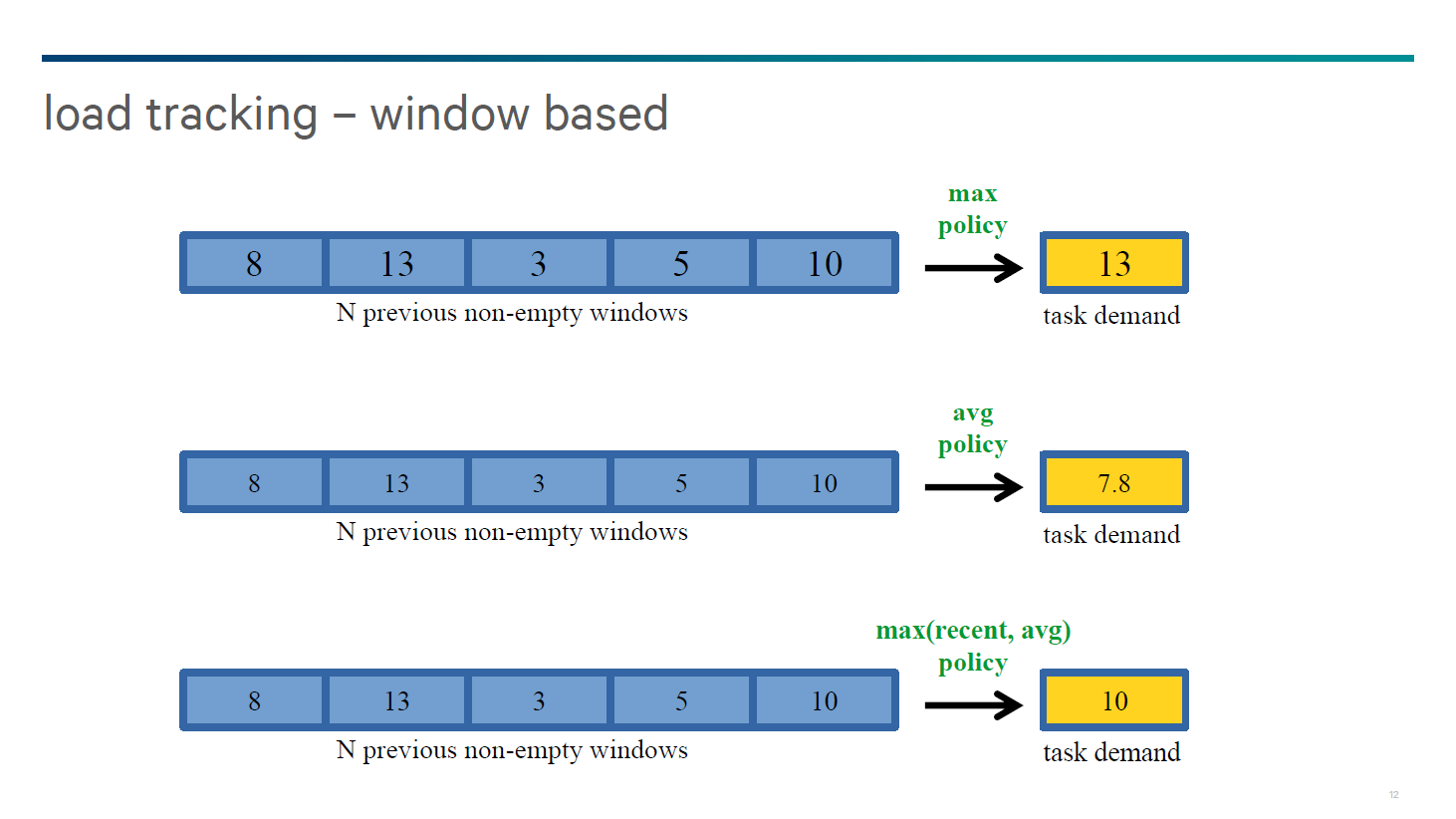
For the Snapdragon 810, Qualcomm has fundamentally done away with per-entity load tracking, and uses a window-based system instead. While we weren’t told the size of each window or how many non-idle windows were retained, the load tracking system uses the average of load across all of the recent windows while also looking at the recent maximum value to determine if there is a task that suddenly requires a significant amount of CPU power. This means that there’s a much shorter waiting period for core scheduling when a thread that goes from mostly or completely idle to a high load or vice versa.
This scenario is common throughout smartphones and can be as simple as reading a web page and then opening a new link. The average metric over all of the windows is used to determine whether a thread needs to continue to run on a big core, or whether it can be safely moved down to a little core. In addition, this window-based system accounts for cases where cores are throttled from their maximum frequencies, which means that processes may stay on little cores even if the load for a task is high for a little core if it would perform worse on a throttled big core.
While there are some areas where we can compare and contrast current GTS solutions and Qualcomm’s solution for the Snapdragon 810, there are areas where no comparisons can be made at all. Although ARM is working on an energy model and an energy aware scheduler, we haven’t seen this working in any shipping SoC.
For the Snapdragon 810, there is an energy model for all CPUs that controls for changing power consumption with temperature and can provide a metric of performance per watt at all frequency states. However, unlike ARM’s energy cost model there’s no tracking for the power cost of a task that increases frequency on the cluster (synchronous architectures require that all CPUs run at the same frequency), nor are wake ups tracked and accounted for in energy modeling.

To be fair, there are a lot of aspects that are shared with the latest GTS mechanism such as packing small tasks onto already awake CPUs in order to avoid the cost of waking a CPU from a power collapse state. However, on the Snapdragon 810 there are evaluations throughout the execution of task to be able to move a task to a big core if its load increases from when the task first started, or if it’s necessary to move a thread from one big core to another big core depending upon the perf/W for each big core. In addition, if a single core is running a small load or task the scheduler can move the thread to another core and allow the other core to go to sleep and save power. The scheduler is also said to be aware of the power cost of migration.
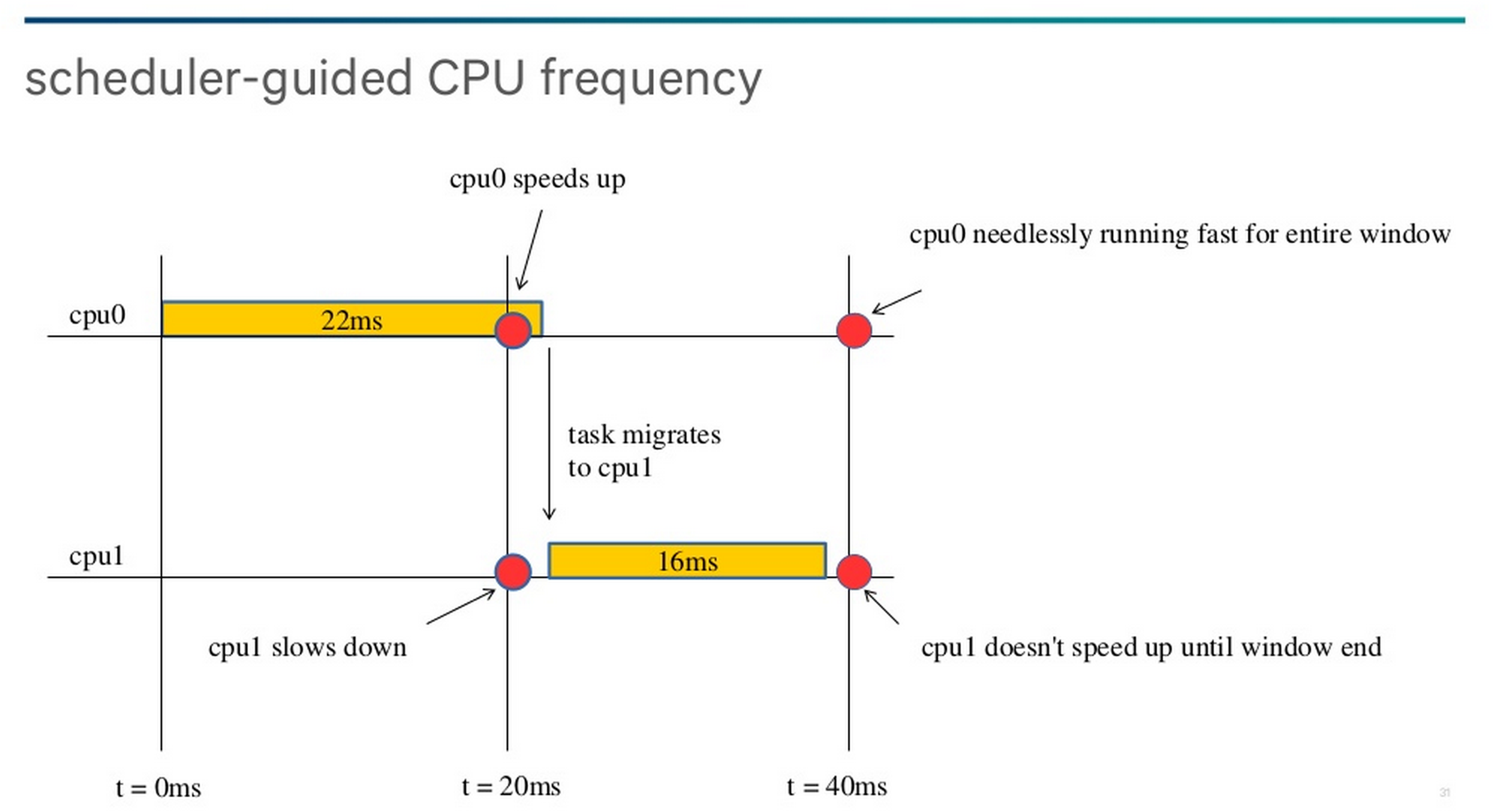
Finally, the scheduler in Snapdragon 810 is used to help guide the CPU frequency governor policy by notifying the frequency governor appropriately to avoid cases where a task is migrated to another CPU and causes inefficient behavior. For example, if a task is at 100% load and is migrated in the middle of a sampling window to another core, the original core isn’t kept at an unnecessarily high frequency, and the core that the task was migrated to will go to the right frequency for the aggregate load of the task. This appears to be somewhat of a mitigation for the window-based system, as ARM’s scheduler uses events to handle these issues without having to resort these patchwork fixes.
In terms of how the power arbitration is actually implemented compared to traditional power management mechanisms in existing SoCs, Qualcomm replaces the old Intel-developed CPUIdle "Menu" and "Ladder" governors. These worked based on the achieved and target residency time of the individual idle states of a CPU core. Qualcomm's solution is a completely new approach (called the Low-Power-Mode CPUIdle driver, or LPM) as it ignores the time characteristic in its entirety and looks only at energy modeling. For this, the SoC's drivers need to have precise arbitration data to be able to properly model the SoC's real power consumption without actually measuring it. Thankfully Qualcomm does this, and it's the most complete model of a commercially available SoC's power characteristics to date.

We not only see the energy models for the various CPU and cluster idle states, but also the idle states of the CCI, something which is lacking in GTS's software stack.
Ultimately, while it’s clear that Qualcomm’s solution to the big.LITTLE problem has its inefficiencies, their solution appears to be far superior to anything else with big.LITTLE on the market. And as previously mentioned in our Note 4 Exynos review, ARM’s energy aware scheduler is still far from implementation on a shipping SoC. This issue is only compounded by ARM’s need to make a solution that works for all big.LITTLE SoCs, and OEM adoption is often slow in these scenarios. While the Snapdragon 810 could be behind other SoCs in process technology, advantages in areas such as the thread scheduler could narrow the gap.








119 Comments
View All Comments
warreo - Wednesday, February 18, 2015 - link
HAHAHA Tchamber you are a jewel. Thanks for making my morning. Here I was wondering if a week later anybody else had anything intelligent to say....Your analogy of the 5433 as a Lamborghini and the Snapdragons as Corvette/Camaro/GT500 is horrible. Period. Anybody who reads this site should know that. If you really want to get into an argument with someone, you should actually know what you're talking about before insulting them.
As for me, I wasn't talking to down to anyone. I gave AT my observations and also did in fact summarize my own conclusions if you'd bothered to read my comments in totality. Just because I disagree with them doesn't mean I'm talking down to them. You, however, should run along back to pre-school and learn how not to be a prick to others.
djvita - Thursday, February 12, 2015 - link
found some typoslast paragraph GPU performance "Qualcomm has narrowedmuch"
CPU performance
PNG Comp ST 0.82 MP/s 1110 MP/s 1.11 MP/s 35%
is 1110 correct? found the difference to be very high....
All in all, preliminar benchamrks looks good. Seems anandtech will need a flex2/mi note pro or the upcoming htc m9 in MWC (for sony no rumors, until july i think, lg g4 maybe in may. S6 wont be qualcomm)
Ratman6161 - Thursday, February 12, 2015 - link
Another typo:There are three tables at the top of the CPU Performance page. The last column in the first table says: Snapdragon % Advantage which clearly isn't correct because just in the first line the Samsung has about a 2 to one advantage it says the snapdragon advantage is 608%. I assume you actually meant this column to say but S810 > S805 % Advantage like in the second two tables.
djvita - Thursday, February 12, 2015 - link
they fixed them all now, it was 1.11SydneyBlue120d - Thursday, February 12, 2015 - link
Very interesting article. Do you think it is possibile the Galaxy S6 devices will use the MDM9x45 modem?deathBOB - Thursday, February 12, 2015 - link
Subjective impressions? Andrei pointed out that the Exynos was subjectively faster than the 805. How does the 810 fare?MrCommunistGen - Thursday, February 12, 2015 - link
Thanks for the informative article! The scope of the article as a whole goes far beyond a Preview of Snapdragon 810, specifically the sections on RF and Qualcomm's scheduler.That in mind, I'll hold off on passing judgement on S810's performance until we see shipping silicon. Between pre-release drivers and differences in chassis/thermals "Performance Preview" *is* spot on for the whole benchmarks section.
Even though S810 is Qualcomm's stopgap and there's only so much you can do (for better or worse) to the performance of off the shelf A57/A53 cores, I'm glad they're still in the game - or at least not out of it. Even as a preview, it is clear that Adreno 430's performance is more than just an iterative increase over Adreno 420.
Regardless of how S810 shakes out, I'm sure Qualcomm is baking all of their learnings from working on this SoC into their in-house ARMv8-A design
Mr.r9 - Thursday, February 12, 2015 - link
Even though this is a preview and drivers/Kernel will definitely improve....I still feel that the 810 will underwhelm.djvita - Thursday, February 12, 2015 - link
considering I still have an msm8960 device, this will be a huge jump for me.tviceman - Thursday, February 12, 2015 - link
This performance preview just reaffirms two of my beliefs.1) It's a shame that Nvidia couldn't get more products with Tegra K1 in it, seeing how K1 has been on the market for many months and generally outperforms the 805 (sometimes by a wide margin)
2) It's a shame that Tegra X1 will likely suffer the same limited release fate that Tegra K1 suffered, even if manufacturers were to downclock Tegra X1 to meet smaller TDP demands. X1, even if downclocked, will run circles around 805.