The NVIDIA GeForce GTX 980 Review: Maxwell Mark 2
by Ryan Smith on September 18, 2014 10:30 PM ESTCompute
On the other hand compared to our Kepler cards GTX 980 introduces a bunch of benefits. Higher CUDA core occupancy is going to be extremely useful in compute benchmarks. So will the larger L2 cache and the 96KB per SMM of shared memory. Even more important, compares to GK104 (GTX 680/770) GTX 980 inherits the compute enhancements that were introduced in GK110 (GTX 780/780 Ti) including changes that relieved pressure on register file bandwidth and capacity. So although GTX 980 is not strictly a compute card – it is first and foremost a graphics card – it has a lot of resources available to spend on compute.
As always we’ll start with LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
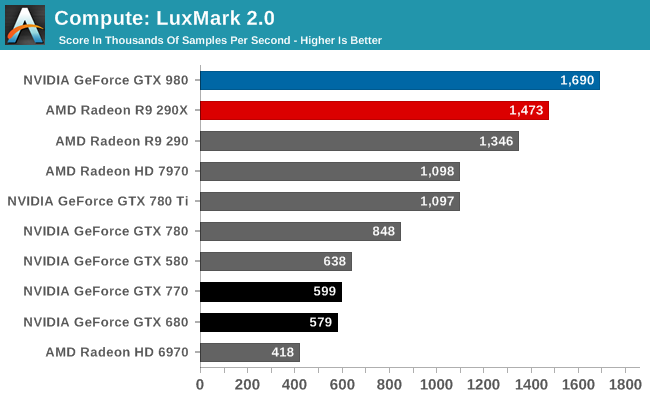
Out of the gate GTX 980 takes off like a rocket. AMD’s cards could easily best even GTX 780 Ti here, but GTX 980 wipes out AMD’s lead and then some. At 1.6M samples/sec, GTX 980 Ti is 15% faster than R9 290X and 54% faster than GTX 780 Ti. This, as it’s important to remind everyone, is for a part that technically only has 71% of the CUDA cores of GTX 780 Ti. So per CUDA core, GTX 980 delivers over 2x the LuxMark performance of GTX 780 Ti. Meanwhile against GTX 680 and GTX 780 the lead is downright silly. GTX 980 comes close to tripling its GK104 based predecessors.
I’ve spent some time pondering this, and considering that GTX 750 Ti looked very good in this test as well it’s clear that Maxwell’s architecture has a lot to do with this. I don’t know if NVIDIA hasn’t also been throwing in some driver optimizations here, but a big part is being played by parts of the architecture. GTX 750 Ti and GTX 980 both share the general architecture and 2MB of L2 cache, while it seems like we can run out GTX 980’s larger 96KB shared memory since GTX 750 Ti did not have that. This may just come down to those CUDA core occupancy improvements, especially if you start comparing GTX 980 to GTX 780 Ti.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. We’re not due for a benchmark suite refresh until the end of the year, however as CLBenchmark does not know what to make of GTX 980 and is rather old overall, we’ve upgraded to CompBench 1.5 for this review.
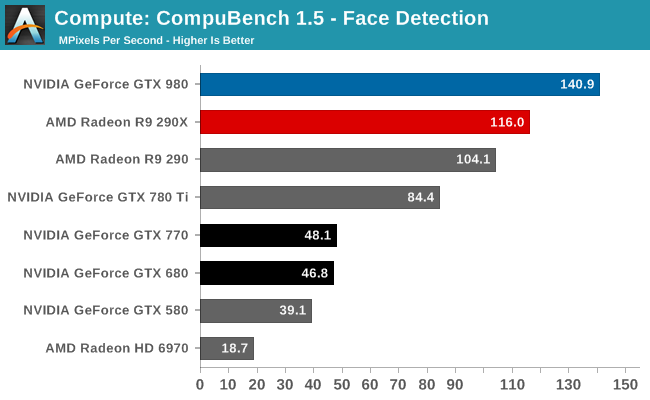
The first sub-benchmark is Face Detection, which like LuxMark puts GTX 980 in a very good light. It’s quite a bit faster than GTX 780 Ti or R9 290X, and comes close to trebling GTX 680.
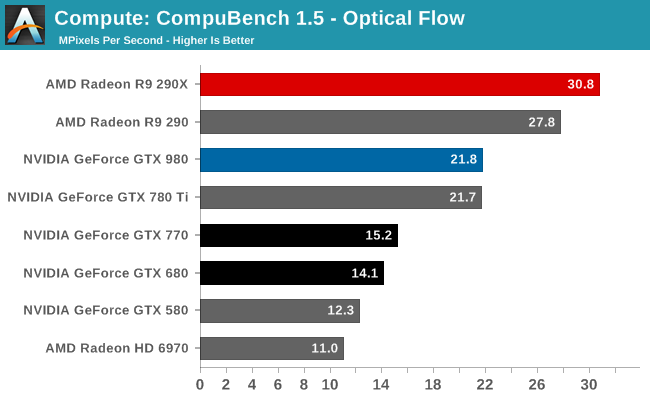
The second sub-benchmark of Optical Flow on the other hand sees AMD put GTX 980 in its place. GTX 980 fares only as well as GTX 780 Ti here, which means performance per CUDA core is up, but not enough to offset the difference in cores. And it doesn’t get GTX 980 anywhere close to beating R9 290X. As a computer vision test this can be pretty memory bandwidth intensive, so this may be a case of GTX 980 succumbing to its lack of memory bandwidth rather than a shader bottleneck.
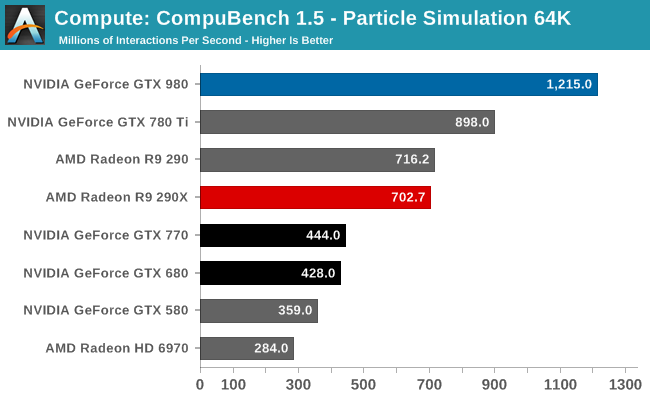
The final sub-benchmark of the particle simulation puts GTX 980 back on top, and by quite a lot. NVIDIA does well in this benchmark to start with – GTX 780 Ti is the number 2 result – and GTX 980 only improves on that. It’s 35% faster than GTX 780 Ti, 73% faster than R9 290X, and GTX 680 is nearly trebled once again. CUDA core occupancy is clearly a big part of these results, though I wonder if the L2 cache and shared memory increase may also be playing a part compared to GTX 780 Ti.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
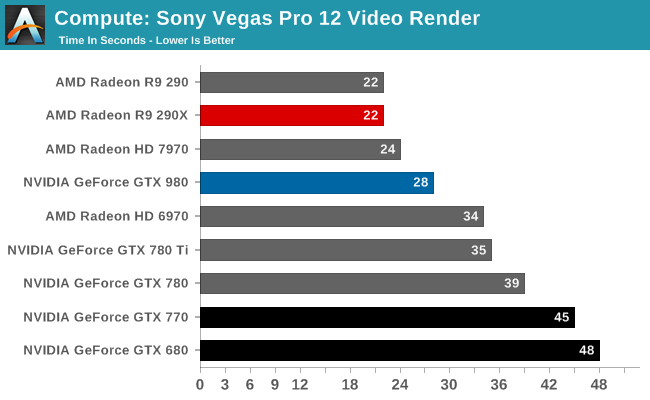
Traditionally a benchmark that favored AMD, the GTX 980 doesn’t manage to beat the R9 290X, but it closes the gap significantly compared to GTX 780 Ti. This test is a mix of simple shaders and blends, so it’s likely we’re seeing a bit of both here. More ROPs for more blending, and improved shader occupancy for when the task is shader-bound.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.


This is another success story for the GTX 980. In both single precision tests the GTX 980 comes out on top, holding a significant lead over the R9 290X. Furthermore we’re seeing some big performance gains over GTX 780 Ti, and outright massive gains over GTX 680, to the point that GTX 980 comes just short of quadrupling GTX 680’s performance in single precision explicit. This test is basically all about shading/compute, so we expect we’re seeing a mix of improvements to CUDA core occupancy, shared memory/cache improvements, and against GTX 680 those register file improvements.

Double precision on the other hand is going to be the GTX 980’s weak point for obvious reasons. GM204 is a graphics GPU first and foremost, so it only has very limited 1:32 rate FP64 performance, leaving it badly outmatched by anything with a better rate. This includes GTX 780/780 Ti (1:24), AMD’s cards (1:8 FP64), and even ancient GTX 580 (1:8). If you want to do real double precision work, NVIDIA clearly wants you buying their bigger, compute-focused products such as GTX Titan, Quadro, and Tesla.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
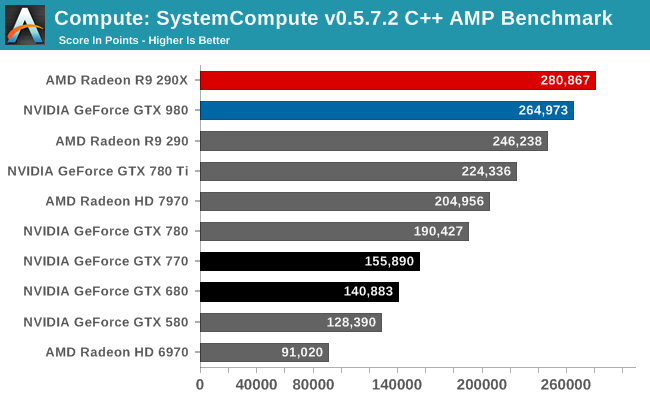
Once again NVIDIA’s compute performance is showing a strong improvement, even under DirectCompute. 17% over GTX 780 Ti and 88% over GTX 680 shows that NVIDIA is getting more work done per CUDA core than ever before. Though this won’t be enough to surpass the even faster R9 290X.
Overall, while NVIDIA can’t win every compute benchmark here, the fact that they are winning so many and by so much – and otherwise not terribly losing the rest – shows that NVIDIA and GM204 have corrected the earlier compute deficiencies in GK104. As an x04 part GM204 may still be first and foremost consumer graphics, but if it’s faced with a compute workload most of the time it’s going to be able to power on through it just as well as it does with games and other graphical workloads.
It would be nice to see GPU compute put to better use than it is today, and having strong(er) compute performance in consumer parts is going to be one of the steps that needs to happen for that outcome to occur.








274 Comments
View All Comments
garadante - Sunday, September 21, 2014 - link
What might be interesting is doing a comparison of video cards for a specific framerate target to (ideally, perhaps it wouldn't actually work like this?) standardize the CPU usage and thus CPU power usage across greatly differing cards. And then measure the power consumed by each card. In this way, couldn't you get a better example ofgaradante - Sunday, September 21, 2014 - link
Whoops, hit tab twice and it somehow posted my comment. Continued:couldn't you get a better example of the power efficiency for a particular card and then meaningful comparisons between different cards? I see lots of people mentioning how the 980 seems to be drawing far more watts than it's rated TDP (and I'd really like someone credible to come in and state how heat dissipated and energy consumed are related. I swear they're the exact same number as any energy consumed by transistors would, after everything, be released as heat, but many people disagree here in the comments and I'd like a final say). Nvidia can slap whatever TDP they want on it and it can be justified by some marketing mumbo jumbo. Intel uses their SDPs, Nvidia using a 165 watt TDP seems highly suspect. And please, please use a nonreference 290X in your reviews, at least for a comparison standpoint. Hasn't it been proven that having cooling that isn't garbage and runs the GPU closer to high 60s/low 70s can lower power consumption (due to leakage?) something on the order of 20+ watts with the 290X? Yes there's justification in using reference products but lets face it, the only people who buy reference 290s/290Xs were either launch buyers or people who don't know better (there's the blower argument but really, better case exhaust fans and nonreference cooling destroys that argument).
So basically I want to see real, meaningful comparisons of efficiencies for different cards at some specific framerate target to standardize CPU usage. Perhaps even monitoring CPU usage over the course of the test and reporting average, minimum, peak usage? Even using monitoring software to measure CPU power consumption in watts (as I'm fairly sure there are reasonably accurate ways of doing this already, as I know CoreTemp reports it as its probably just voltage*amperage, but correct me if I'm wrong) and reported again average, minimum, peak usage would be handy. It would be nice to see if Maxwell is really twice as energy efficient as GCN1.1 or if it's actually much closer. If it's much closer all these naysayers prophesizing AMD's doom are in for a rude awakening. I wouldn't put it past Nvidia to use marketing language to portray artificially low TDPs.
silverblue - Sunday, September 21, 2014 - link
Apparently, compute tasks push the power usage way up; stick with gaming and it shouldn't.fm123 - Friday, September 26, 2014 - link
Don't confuse TDP with power consumption, they are not the same thing. TDP is for designing the thermal solution to maintain the chip temperature. If there is more headroom in the chip temperature, then the system can operate faster, consuming more power."Intel defines TDP as follows: The upper point of the thermal profile consists of the Thermal Design Power (TDP) and the associated Tcase value. Thermal Design Power (TDP) should be used for processor thermal solution design targets. TDP is not the maximum power that the processor can dissipate. TDP is measured at maximum TCASE"
https://www.google.com/url?sa=t&source=web&...
NeatOman - Sunday, September 21, 2014 - link
I just realized that the GTX 980 has a TDP of 165 watts, my Corsair CX430 watt PSU is almost overkill!, that's nuts. That's even enough room to give the whole system a very good stable overclock. Right now i have a pair of HD 7850's @ stock speed and a FX-8320 @ 4.5Ghz, good thing the Corsair puts out over 430 watts perfectly clean :)Nfarce - Sunday, September 21, 2014 - link
While a good power supply, you are leaving yourself little headroom with 430W. I'm surprised you are getting away with it with two 7850s and not experiencing system crashes.ET - Sunday, September 21, 2014 - link
The 980 is an impressive feat of engineering. Fewer transistors, fewer compute units, less power and better performance... NVIDIA has done a good job here. I hope that AMD has some good improvements of its own under its sleeve.garadante - Sunday, September 21, 2014 - link
One thing to remember is they probably save a -ton- of die area/transistors by giving it only what, 1/32 double precision rate? I wonder how competitive in terms of transistors/area an AMD GPU would be if they gutted double precision compute and went for a narrower, faster memory controller.Farwalker2u - Sunday, September 21, 2014 - link
I am looking forward to your review of the GTX 970 once you have a compatible sample in hand.I would like to see the results of the Folding @Home benchmarks. It seems that this site is the only one that consistently use that benchmark in its reviews.
As a "Folder" I'd like to see any indication that the GTX 970, at a cost of $330 and drawing less watts than a GTX 780; may out produce both the 780 ($420 - $470) and the 780Ti ($600). I will be studying the Folding @ Home: Explicit, Single Precision chart which contains the test results of the GTX 970.
Wolfpup - Monday, September 22, 2014 - link
Wow, this is impressive stuff. 10% more performance from 2/3 the power? That'll be great for desktops, but of course even better for notebooks. Very impressed they could pulll off that kind of leap on the same process!They've already managed to significantly bump up the top end mobile part from GTX 680 -> 880, but within a year or so I bet they can go quite a bit higher still.
Oh well, it was nice having a top of the line mobile GPU for a while LOL
If 28nm hit in 2012 though, doesn't that make 2015 its third year? At least 28nm seems to be a really good process, vs all the issues with 90/65nm, etc., since we're stuck on it so long.
Isn't this Moore's Law hitting the constraints of physical reality though? We're taking longer and longer to get to progressively smaller shrinks in die size, it seems like...
Oh well, 22nm's been great with Intel and 28's been great with everyone else!