The NVIDIA GeForce GTX 980 Review: Maxwell Mark 2
by Ryan Smith on September 18, 2014 10:30 PM ESTCompute
On the other hand compared to our Kepler cards GTX 980 introduces a bunch of benefits. Higher CUDA core occupancy is going to be extremely useful in compute benchmarks. So will the larger L2 cache and the 96KB per SMM of shared memory. Even more important, compares to GK104 (GTX 680/770) GTX 980 inherits the compute enhancements that were introduced in GK110 (GTX 780/780 Ti) including changes that relieved pressure on register file bandwidth and capacity. So although GTX 980 is not strictly a compute card – it is first and foremost a graphics card – it has a lot of resources available to spend on compute.
As always we’ll start with LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
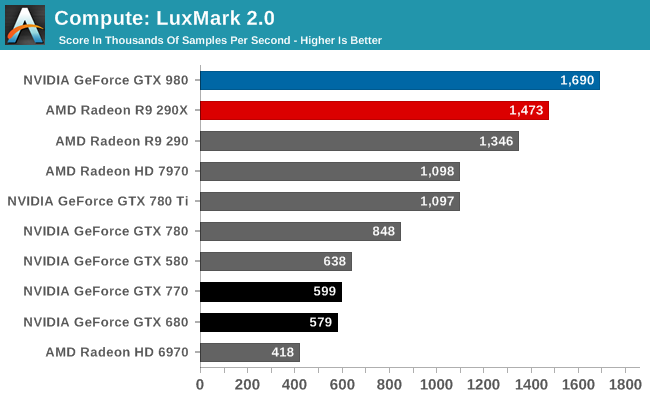
Out of the gate GTX 980 takes off like a rocket. AMD’s cards could easily best even GTX 780 Ti here, but GTX 980 wipes out AMD’s lead and then some. At 1.6M samples/sec, GTX 980 Ti is 15% faster than R9 290X and 54% faster than GTX 780 Ti. This, as it’s important to remind everyone, is for a part that technically only has 71% of the CUDA cores of GTX 780 Ti. So per CUDA core, GTX 980 delivers over 2x the LuxMark performance of GTX 780 Ti. Meanwhile against GTX 680 and GTX 780 the lead is downright silly. GTX 980 comes close to tripling its GK104 based predecessors.
I’ve spent some time pondering this, and considering that GTX 750 Ti looked very good in this test as well it’s clear that Maxwell’s architecture has a lot to do with this. I don’t know if NVIDIA hasn’t also been throwing in some driver optimizations here, but a big part is being played by parts of the architecture. GTX 750 Ti and GTX 980 both share the general architecture and 2MB of L2 cache, while it seems like we can run out GTX 980’s larger 96KB shared memory since GTX 750 Ti did not have that. This may just come down to those CUDA core occupancy improvements, especially if you start comparing GTX 980 to GTX 780 Ti.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. We’re not due for a benchmark suite refresh until the end of the year, however as CLBenchmark does not know what to make of GTX 980 and is rather old overall, we’ve upgraded to CompBench 1.5 for this review.
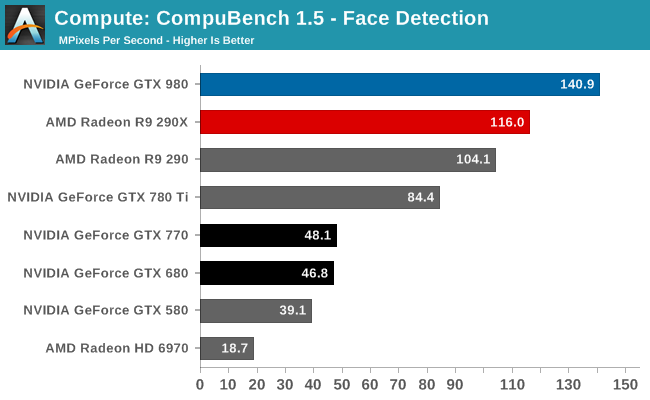
The first sub-benchmark is Face Detection, which like LuxMark puts GTX 980 in a very good light. It’s quite a bit faster than GTX 780 Ti or R9 290X, and comes close to trebling GTX 680.
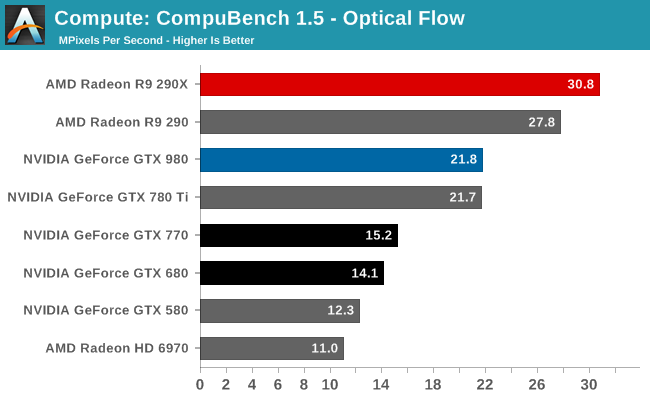
The second sub-benchmark of Optical Flow on the other hand sees AMD put GTX 980 in its place. GTX 980 fares only as well as GTX 780 Ti here, which means performance per CUDA core is up, but not enough to offset the difference in cores. And it doesn’t get GTX 980 anywhere close to beating R9 290X. As a computer vision test this can be pretty memory bandwidth intensive, so this may be a case of GTX 980 succumbing to its lack of memory bandwidth rather than a shader bottleneck.
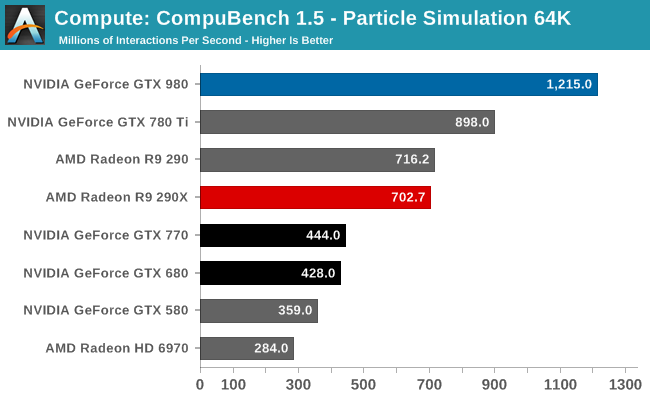
The final sub-benchmark of the particle simulation puts GTX 980 back on top, and by quite a lot. NVIDIA does well in this benchmark to start with – GTX 780 Ti is the number 2 result – and GTX 980 only improves on that. It’s 35% faster than GTX 780 Ti, 73% faster than R9 290X, and GTX 680 is nearly trebled once again. CUDA core occupancy is clearly a big part of these results, though I wonder if the L2 cache and shared memory increase may also be playing a part compared to GTX 780 Ti.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
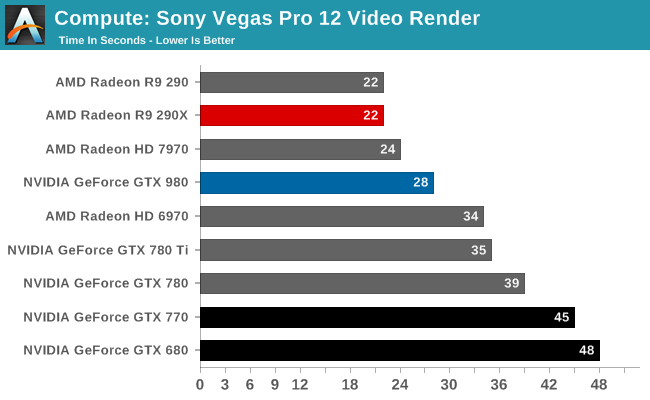
Traditionally a benchmark that favored AMD, the GTX 980 doesn’t manage to beat the R9 290X, but it closes the gap significantly compared to GTX 780 Ti. This test is a mix of simple shaders and blends, so it’s likely we’re seeing a bit of both here. More ROPs for more blending, and improved shader occupancy for when the task is shader-bound.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.


This is another success story for the GTX 980. In both single precision tests the GTX 980 comes out on top, holding a significant lead over the R9 290X. Furthermore we’re seeing some big performance gains over GTX 780 Ti, and outright massive gains over GTX 680, to the point that GTX 980 comes just short of quadrupling GTX 680’s performance in single precision explicit. This test is basically all about shading/compute, so we expect we’re seeing a mix of improvements to CUDA core occupancy, shared memory/cache improvements, and against GTX 680 those register file improvements.

Double precision on the other hand is going to be the GTX 980’s weak point for obvious reasons. GM204 is a graphics GPU first and foremost, so it only has very limited 1:32 rate FP64 performance, leaving it badly outmatched by anything with a better rate. This includes GTX 780/780 Ti (1:24), AMD’s cards (1:8 FP64), and even ancient GTX 580 (1:8). If you want to do real double precision work, NVIDIA clearly wants you buying their bigger, compute-focused products such as GTX Titan, Quadro, and Tesla.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
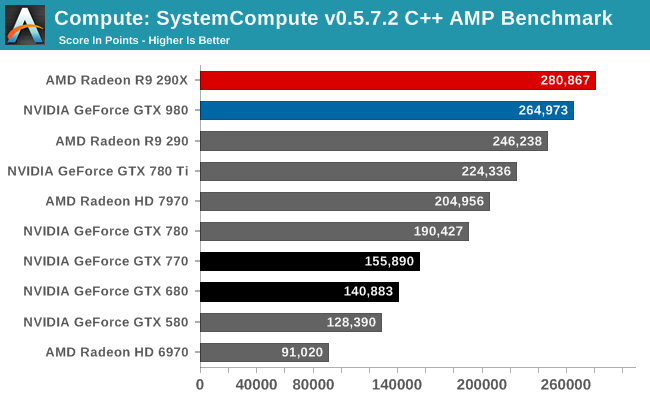
Once again NVIDIA’s compute performance is showing a strong improvement, even under DirectCompute. 17% over GTX 780 Ti and 88% over GTX 680 shows that NVIDIA is getting more work done per CUDA core than ever before. Though this won’t be enough to surpass the even faster R9 290X.
Overall, while NVIDIA can’t win every compute benchmark here, the fact that they are winning so many and by so much – and otherwise not terribly losing the rest – shows that NVIDIA and GM204 have corrected the earlier compute deficiencies in GK104. As an x04 part GM204 may still be first and foremost consumer graphics, but if it’s faced with a compute workload most of the time it’s going to be able to power on through it just as well as it does with games and other graphical workloads.
It would be nice to see GPU compute put to better use than it is today, and having strong(er) compute performance in consumer parts is going to be one of the steps that needs to happen for that outcome to occur.








274 Comments
View All Comments
jmunjr - Friday, September 19, 2014 - link
Wish you had done a GTX 970 review as well like many other sites since way more of us care about that card than the 980 since it is cheaper.Gonemad - Friday, September 19, 2014 - link
Apparently, if I want to run anything under the sun in 1080p cranked to full at 60fps, I will need to get me one GTX 980 and a suitable system to run with it, and forget mid-ranged priced cards.That should put an huge hole in my wallet.
Oh yes, the others can run stuff at 1080p, but you have to keep tweaking drivers, turning AA on, turning AA off, what a chore. And the milennar joke, yes it RUNS Crysis, at the resolution I'd like.
Didn't, by any chance, the card actually benefit of being fabricated at 28nm, by spreading its heat over a larger area? If the whole thing, hipothetically, just shrunk to 14nm, wouldn't all that 165W of power would be dissipated over a smaller area (1/4 area?), and this thing would hit the throttle and stay there?
Or by being made smaller, it would actually dissipate even less heat and still get faster?
Yojimbo - Friday, September 19, 2014 - link
I think that it depends on the process. If Dennard scaling were to be in effect, then it should dissipate proportionally less heat. But to my understanding, Dennard scaling has broken down somewhat in recent years, and so I think heat density could be a concern. However, I don't know if it would be accurate to say that the chip benefited from the 28nm process, since I think it was originally designed with the 20nm process in mind, and the problem with putting the chip on that process had to do with the cost and yields. So, presumably, the heat dissipation issues were already worked out for that process..?AnnonymousCoward - Friday, September 26, 2014 - link
The die size doesn't really matter for heat dissipation when the external heat sink is the same size; the thermal resistance from die to heat sink would be similar.danjw - Friday, September 19, 2014 - link
I would love to see these built on Intel's 14nm process or even the 22nm. I think both Nvidia and AMD aren't comfortable letting Intel look at their technology, despite NDAs and firewalls that would be a part of any such agreement.Anyway, thanks for the great review Ryan.
Yojimbo - Friday, September 19, 2014 - link
Well, if one goes by Jen-Hsun Huang's (Nvidia's CEO) comments of a year or two ago, Nvidia would have liked Intel to manufacture their SOCs for them, but it seems Intel was unwilling. I don't see why they would be willing to have them manufacture SOCs and not GPUs being that at that time they must have already had the plan to put their desktop GPU technology into their SOCs, unless the one year delay between the parts makes a difference.r13j13r13 - Friday, September 19, 2014 - link
hasta que no salga la serie 300 de AMD con soporte nativo para directx 12Arakageeta - Friday, September 19, 2014 - link
No interpretation of the compute graphs whatsoever? Could you at least report the output of CUDA's deviceQuery tool?texasti89 - Friday, September 19, 2014 - link
I'm truly impressed with this new line of GPUs. To be able to acheive this leap on efficiency using the same transistor feature size is a great incremental achievement. Bravo TSMC & Nvidia. I feel comfortable to think that we will soon get this amazing 980 performance level on game laptops once we scale technology to the 10nm process. Keep up the great work.stateofstatic - Friday, September 19, 2014 - link
Spoiler alert: Intel is building a new fab in Hillsboro, OR specifically for this purpose...