Apple's Cyclone Microarchitecture Detailed
by Anand Lal Shimpi on March 31, 2014 2:10 AM EST
The most challenging part of last year's iPhone 5s review was piecing together details about Apple's A7 without any internal Apple assistance. I had less than a week to turn the review around and limited access to tools (much less time to develop them on my own) to figure out what Apple had done to double CPU performance without scaling frequency. The end result was an (incorrect) assumption that Apple had simply evolved its first ARMv7 architecture (codename: Swift). Based on the limited information I had at the time I assumed Apple simply addressed some low hanging fruit (e.g. memory access latency) in building Cyclone, its first 64-bit ARMv8 core. By the time the iPad Air review rolled around, I had more knowledge of what was underneath the hood:
As far as I can tell, peak issue width of Cyclone is 6 instructions. That’s at least 2x the width of Swift and Krait, and at best more than 3x the width depending on instruction mix. Limitations on co-issuing FP and integer math have also been lifted as you can run up to four integer adds and two FP adds in parallel. You can also perform up to two loads or stores per clock.
With Swift, I had the luxury of Apple committing LLVM changes that not only gave me the code name but also confirmed the size of the machine (3-wide OoO core, 2 ALUs, 1 load/store unit). With Cyclone however, Apple held off on any public commits. Figuring out the codename and its architecture required a lot of digging.
Last week, the same reader who pointed me at the Swift details let me know that Apple revealed Cyclone microarchitectural details in LLVM commits made a few days ago (thanks again R!). Although I empirically verified many of Cyclone's features in advance of the iPad Air review last year, today we have some more concrete information on what Apple's first 64-bit ARMv8 architecture looks like.
Note that everything below is based on Apple's LLVM commits (and confirmed by my own testing where possible).
| Apple Custom CPU Core Comparison | ||||||
| Apple A6 | Apple A7 | |||||
| CPU Codename | Swift | Cyclone | ||||
| ARM ISA | ARMv7-A (32-bit) | ARMv8-A (32/64-bit) | ||||
| Issue Width | 3 micro-ops | 6 micro-ops | ||||
| Reorder Buffer Size | 45 micro-ops | 192 micro-ops | ||||
| Branch Mispredict Penalty | 14 cycles | 16 cycles (14 - 19) | ||||
| Integer ALUs | 2 | 4 | ||||
| Load/Store Units | 1 | 2 | ||||
| Load Latency | 3 cycles | 4 cycles | ||||
| Branch Units | 1 | 2 | ||||
| Indirect Branch Units | 0 | 1 | ||||
| FP/NEON ALUs | ? | 3 | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 64KB I$ + 64KB D$ | ||||
| L2 Cache | 1MB | 1MB | ||||
| L3 Cache | - | 4MB | ||||
As I mentioned in the iPad Air review, Cyclone is a wide machine. It can decode, issue, execute and retire up to 6 instructions/micro-ops per clock. I verified this during my iPad Air review by executing four integer adds and two FP adds in parallel. The same test on Swift actually yields fewer than 3 concurrent operations, likely because of an inability to issue to all integer and FP pipes in parallel. Similar limits exist with Krait.
I also noted an increase in overall machine size in my initial tinkering with Cyclone. Apple's LLVM commits indicate a massive 192 entry reorder buffer (coincidentally the same size as Haswell's ROB). Mispredict penalty goes up slightly compared to Swift, but Apple does present a range of values (14 - 19 cycles). This also happens to be the same range as Sandy Bridge and later Intel Core architectures (including Haswell). Given how much larger Cyclone is, a doubling of L1 cache sizes makes a lot of sense.
On the execution side Cyclone doubles the number of integer ALUs, load/store units and branch units. Cyclone also adds a unit for indirect branches and at least one more FP pipe. Cyclone can sustain three FP operations in parallel (including 3 FP/NEON adds). The third FP/NEON pipe is used for div and sqrt operations, the machine can only execute two FP/NEON muls in parallel.
I also found references to buffer sizes for each unit, which I'm assuming are the number of micro-ops that feed each unit. I don't believe Cyclone has a unified scheduler ahead of all of its execution units and instead has statically partitioned buffers in front of each port. I've put all of this information into the crude diagram below:
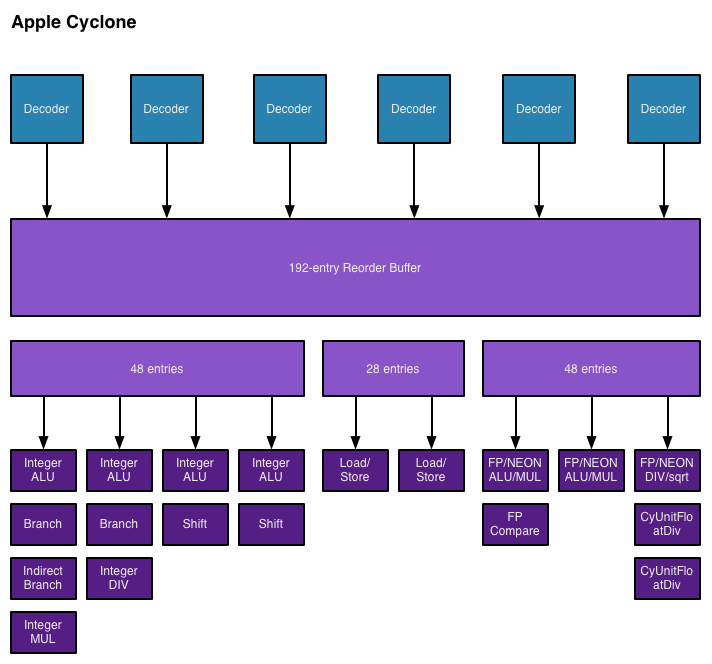
Unfortunately I don't have enough data on Swift to really produce a decent comparison image. With six decoders and nine ports to execution units, Cyclone is big. As I mentioned before, it's bigger than anything else that goes in a phone. Apple didn't build a Krait/Silvermont competitor, it built something much closer to Intel's big cores. At the launch of the iPhone 5s, Apple referred to the A7 as being "desktop class" - it turns out that wasn't an exaggeration.
Cyclone is a bold move by Apple, but not one that is without its challenges. I still find that there are almost no applications on iOS that really take advantage of the CPU power underneath the hood. More than anything Apple needs first party software that really demonstrates what's possible. The challenge is that at full tilt a pair of Cyclone cores can consume quite a bit of power. So for now, Cyclone's performance is really used to exploit race to sleep and get the device into a low power state as quickly as possible. The other problem I see is that although Cyclone is incredibly forward looking, it launched in devices with only 1GB of RAM. It's very likely that you'll run into memory limits before you hit CPU performance limits if you plan on keeping your device for a long time.

It wasn't until I wrote this piece that Apple's codenames started to make sense. Swift was quick, but Cyclone really does stir everything up. The earlier than expected introduction of a consumer 64-bit ARMv8 SoC caught pretty much everyone off guard (e.g. Qualcomm's shift to vanilla ARM cores for more of its product stack).
The real question is where does Apple go from here? By now we know to expect an "A8" branded Apple SoC in the iPhone 6 and iPad Air successors later this year. There's little benefit in going substantially wider than Cyclone, but there's still a ton of room to improve performance. One obvious example would be through frequency scaling. Cyclone is clocked very conservatively (1.3GHz in the 5s/iPad mini with Retina Display and 1.4GHz in the iPad Air), assuming Apple moves to a 20nm process later this year it should be possible to get some performance by increasing clock speed scaling without a power penalty. I suspect Apple has more tricks up its sleeve than that however. Swift and Cyclone were two tocks in a row by Intel's definition, a third in 3 years would be unusual but not impossible (Intel sort of committed to doing the same with Saltwell/Silvermont/Airmont in 2012 - 2014).
Looking at Cyclone makes one thing very clear: the rest of the players in the ultra mobile CPU space didn't aim high enough. I wonder what happens next round.








182 Comments
View All Comments
ssj3gohan - Monday, March 31, 2014 - link
The problem here is that you can't just go on and try to scale performance by making the processor wider and wider. They're already going into an extremely (silicon) expensive route now by adding the largest possible caches and widest possible non-execution resources they can fit onto an ARM core. There is no room here - there is, but it's not worth it unless they say 'fuck it, we won't care about cost at all anymore'.The next steps will really have to be architectural changes to the processor, moving it more in the direction of Intel/AMD. Wider (multi-module?) RAM interfaces actually feeding into the processor and GPU, not being divided down like they are right now (high synthetic bandwidth but disappointing practical bandwidth). Smarter branch prediction for better single core IPC. But most of all, they are probably just going to build a whole bunch of extensions over ARMv8 to fix the hoops the compilers need to jump through to get anything done.
Another big stickler would be power consumption. ARM, even the best implementations of ARMv8, is still a good half to whole order of magnitude worse in the performance per watt game, and it gets much worse at active idle. There are no proper hardware 'system agents' in these processors, all the power management is done in software which is absolutely horrid. I wouldn't be surprised if Apple be the first to foray into some analogy of desktop C-states, maybe even beating ACPI at its own game and making a more modern power management interface. Split power planes can finally be a thing, which allows them to take in more I/O onto the main die. PCIe, NVMe and proper DDR4L support?
Another thing they may try given the budget they have is, but this is just wishful thinking and I wouldnt ever dream of this happening, Apple integrating 4G and WiFi? The only reason I'm even saying this is because we are finally in a spot where 3G and 802.11a/b/g is not necessary anymore, so you are not dependent on the big players in the field anymore that give you their patent protection. 4G and 802.11n/ac are fairly easy to get into and make your own implementation. But yeah, that would be crazy. I'm sure they will squeeze every last cent out of their CPU/GPU team investments before they start thinking about wireless.
jeffkibuule - Monday, March 31, 2014 - link
I've always thought as soon as Verizon Wireless no longer requires CDMA for voice, Apple dumps Qualcomm, goes in-house with wireless, and integrates the cellular baseband in house. It always felt like because of timing and scaling issues, the IPhone had to use n-1 of the best chips Qualcomm had.Infy102 - Monday, March 31, 2014 - link
Theoretically speaking, if you were to overclock that Cyclone thing into around 4GHz or so, would it come close to performance of Intel's Core CPUs?bj_murphy - Monday, March 31, 2014 - link
I'm no expert, but I think you'd see rapidly increasing diminishing returns by scaling clock speed that high on a mobile architecture, even one as wide as this. There's a general theory (found somewhere on this site) that a particular CPU architecture can only scale within a power envelope of approximately an order of magnitude (1-10W, or 10-100W for example). It all depends how much power would be required to hit the clock speed.ats - Monday, March 31, 2014 - link
It really really depends on the workloads. The Intel CPUs have a lot of work in the Uncore to allow them to scale to such frequencies. The Intel CPUs also have a lot of work in the memory pipeline. As you increase frequency, you become more and more bottle necked on the average number of loads and store you can have outstanding. Most of the mobile CPUs haven't really worked the whole memory pipeline issue as much as the desktop and server CPUs.grahaman27 - Monday, March 31, 2014 - link
No because overclocking alone does very little. You would end up encountering massive bottlenecks across the entire chip that would make it appear as if over clocking is not doing anything at all.name99 - Monday, March 31, 2014 - link
Here's a better way to say it.If you down clock an x86 to Cyclone speeds, how does the performance compare? The experiment can be done (just buy an i3 running at 1.3GHz and prevent it from turboing) and performance is comparable. So yay Apple. BUT
the fact remains that Intel is able to hit 4GHz and Apple is not. There are a few different aspects to this. One is process and (maybe) circuits --- physically running the core at 4GHz. Apple could probably do this if they wanted, though they might burn more power at 4GHz than Intel does.
A second is that running your core three times faster means that delays for memory are three times as long. Reducing the cost of these delays is where most of the work goes in a modern CPU. You want a large low latency L3 cache, you want a memory controller that limits delays when you do have to talk to RAM, you want very sophisticated pre fetchers. Intel is probably to certainly ahead of Apple in all three areas, but there's no reason to believe that Intel has some sort of magic that isn't available to Apple once they start concentrating on this area.
The larger claims above like "would end up encountering massive bottlenecks across the entire chip" are misleading and unhelpful. Essentially what happens is that when you miss in cache, you fairly rapidly fill up the ROB and then you're blocked, unable to do anything until the memory is serviced. Since Apple and Intel have equally sized ROBs, they will hit this point at pretty much the same time on any cache miss. Where Intel probably have an advantage (for now) is
- miss in cache much less often (better pre fetchers, larger faster L3)
- while the ROB is being filled up Intel MAY (not necessarily, but possibly) allow for more additional in-flight memory requests to be generated, ie can support higher level MLP.
The next great leap forward in CPUs is to support enough out-of-order processing to just keep working while servicing a request to memory. There are a variety of proposals for how to do this with names like kilo-instruction processing and continual flow pipelines. The common idea is to have an auxiliary buffer into which you slide all instructions dependent on the memory miss until the memory returns, at which point you wake up these instructions. This is not at all trivial for a few reasons. One is that it is dependent on extraordinarily good branch prediction, since executing 1000+ instructions based on speculation is not much good if, around instruction 200 you speculated incorrectly. Another is that there are nasty technical issues surrounding how you handle registers and in particular register renaming after you wake up the instructions that were sleeping waiting on memory.
If Apple want to really show us that they've surpassed Intel, they'll be the first to ship a processor of this class. I could see it happening simply because they have so much less baggage they have to deal with --- they can focus all their attention on getting the hard part of KIP working, not on low-level crap like how this feature is going to screw up 286 mode or interact weirdly with SMM.
grahaman27 - Monday, March 31, 2014 - link
"Essentially what happens is that when you miss in cache, you fairly rapidly fill up the ROB and then you're blocked, unable to do anything until the memory is serviced. "thats a bottleneck. and it wont just happen for the CPU cache, but the memory controller, RAM throughput, ect. Sounds like a massive bottleneck to me.
name99 - Monday, March 31, 2014 - link
Not at all. Go read what the ROB actually does. In particular, no, the memory controller, RAM throughput etc will NOT lock up.A large part of the goal of the ROB and all the Out of Order mechanism is to maximize MLP --- ie to fire up as many memory requests as possible all to be serviced during these periods while the ROB is full. The caches and mem controller have nothing to do with the ROB and its filling up or otherwise.
Kevin G - Monday, March 31, 2014 - link
Apple likely tunes any prefetchers for burst operations into main memory and heavily relies on the L3 cache. The SoC likes to put the DRAM to sleep when ever possible so the prefetchers would ideally be doing burst reads most of the time to maximize sleep time. This is not optimal from a performance perspective but rather power. At 4 Ghz, such tuning would be detrimental to overall performance given how many cycles main memory would be. It would also help explain the similarly sized ROBs.I'd argue that the next leap forward for Apple's designs would be SMT. By being able to run two threads simultaneously (or just a quick context switch), work may still be performed while one thread stalls on a memory read. Staying dual core in a phone still makes sense from a power perspective if Apple can add SMT with such a wide design. Going wider would still make sense in light of wide SMT (>4 way), though this may not be power optimal.
I differ in that I see the next big thing from an architectural stand point will be out-of-order instruction retirement. Currently OoO execution still keeps the illusion of a linear serial stream of instructions. Breaking that has some interesting ramifications for performance. The only chip to do so was Sun (erm Oracle's) Rock chip that taped out but never shipped.