The Radeon R9 280X Review: Feat. Asus & XFX - Meet The Radeon 200 Series
by Ryan Smith on October 8, 2013 12:01 AM ESTCompute
Jumping into compute, as with our synthetic benchmarks we aren’t expecting too much new here. Outside of DirectCompute GK104 is generally a poor compute GPU, which makes everything very easy for the Tahiti based 280X. At the same time compute is still a secondary function for these products, so while important the price cuts that go with the 280X are not quite as meaningful here.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
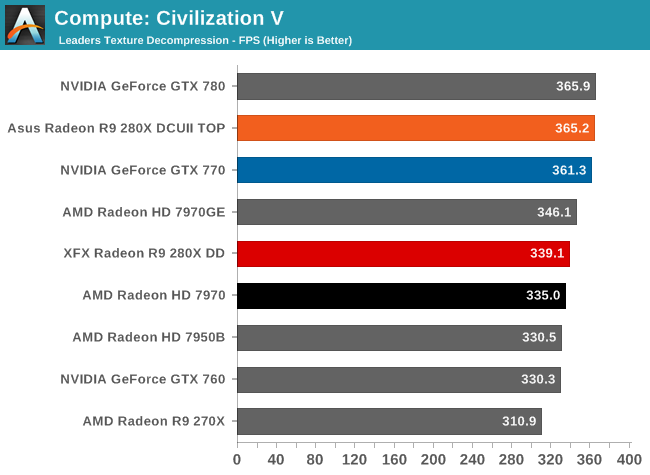
With Civilization V we’re finding that virtually every high-end GPU is running into the same bottleneck. We’ve reached the point where even GPU texture compression is CPU-bound.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
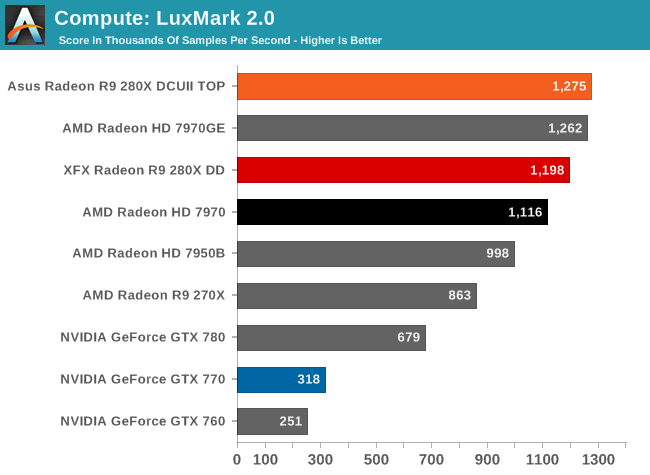
AMD simply rules the roost when it comes to LuxMark, so the only thing close to 280X here are other Tahiti parts.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
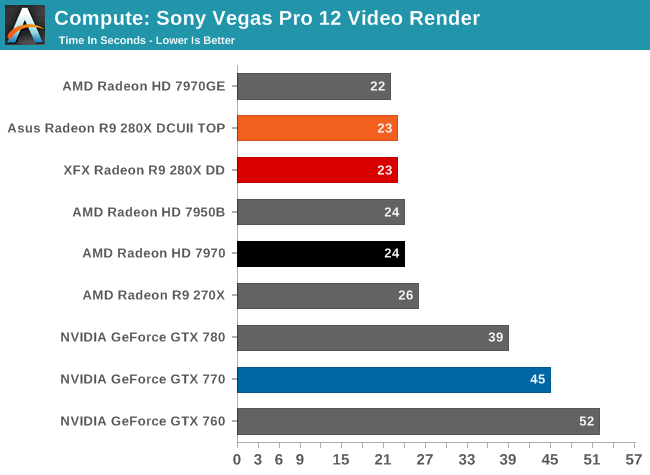
Again AMD’s strong compute performance shines through, with 280X easily topping the chart.
Our 4th benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


Despite the significant differences in these two workloads, in both cases 280X comes out easily on top.
Moving on, our 5th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.



Depending on the mode and the precision, we can have wildly different results. The 280X does well in FP32 explicit, for example, but in implicit mode the 280X is now caught between the GTX 770 and GTX 760. But if we move to double precision then AMD’s native ¼ FP64 execution speed gives them a significant advantage here.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

Although not by any means a blowout, yet again the 280X vies for the top here. When it comes to compute, the Tahiti based 280X is generally unopposed by anything in its price range.








151 Comments
View All Comments
Dribble - Tuesday, October 8, 2013 - link
Didn't you read the article - it is a 7970GE give or take a little on clocks (depending on what 280 you buy). The only new card is the 290 all the others are the same cards you could already buy. The news is lower prices, although as 7970's were already at lower prices then AMD recommended not sure how much real change there will be.The biggest downer for AMD fans will be the end of the 7950, which was always the price/performance king.
Da W - Tuesday, October 8, 2013 - link
It's gonna be the R9 280 (no X).I might just go and buy two 7950 right now. I'm not sure a single Hawaii priced near a 780 is worth it, crossfire issues notwithstanding.
Very disappointing. Specs I saw floating here and there pointed to 270X being more like a Tahiti XL.
zeock9 - Tuesday, October 8, 2013 - link
Didn't you read my comment - 7970GE can already be had for the same price, so it's the same card for more money because 280X doesn't come with the Never Settle bundle.Trying to charge more buck for less bang just because it has a new name is a effing shame of a business practice.
ninjaquick - Tuesday, October 8, 2013 - link
What do you expect? AMD is not releasing a new architecture this time around. They have a very efficient design in GCN, they will not go changing it. Mark my words, the 370X is going to be a die shrunk 7970 GHz, and the 460X is going to be the same, or just a 'rebadged' 370X. AMD's GCN is a bottom-up modular design, not a top-down big chip first design.HisDivineOrder - Tuesday, October 8, 2013 - link
Mantle is going to require they not stray too far from GCN and the way the cards are currently laid out. Otherwise, you'd have games suddenly having cards they're "Mantle compatible" with and cards they aren't.You won't see huge shifts in how the GCN is laid out post GCN 1.1 if they want to keep low level access working smoothly for the foreseeable future. Then again, perhaps they'll do the shift and just shift back to supporting their high level (drivers) instead once Mantle craters on impact because nVidia and Intel start throwing their money around...
Either way, I'm pretty sure Mantle is a cost-cutting tool to help de-emphasize driver development on the consumer side and help keep up with performance gains by aggressive nVidia and intel release cycles that AMD doesn't have the money to fight.
roastmeat - Tuesday, July 21, 2015 - link
Ha, well what do you knowThe 370 is a rebadge
chizow - Tuesday, October 8, 2013 - link
"AMD has been very explicit in not calling these rebadges, and technically they are correct, but all of these products should be very familiar to our regular readers."So how are these not rebadges/rebrands again and how is it technically correct to not call them rebadges? I just find it funny that AMD was so explicit about not calling them as such, I mean it's clear both parties have a history of rebranding, but let's call a spade a spade here.
Nvidia was pounded by AMD fanboys and the press alike for it's rebranding of G92, but any single iteration from G92 certainly had more changes than the non-existent changes we see with this R7/R9 rebrand stack.
Ryan Smith - Tuesday, October 8, 2013 - link
A rebadge would be something like the 5770 to 6770. Same card, same clocks, same TDP. These are new SKUs, based on existing GPUs, under a new name.chizow - Tuesday, October 8, 2013 - link
lol I guess we have some revisionist history that needs to be written then. Not blaming you of course for public perception, just saying, these were not the standards in G92's day as it easily cleared this very low standard of different clockspeeds/TDP/card design, as every single G92 incarnation surpassed these requirements.In any case, I did appreciate the in-depth coverage of Mantle, possible benefits, repercussions, downsides. Excellent coverage and commentary on all angles, as usual. Look forward to more detail about it in the future.
Gigaplex - Tuesday, October 8, 2013 - link
If the silicon isn't any different, the only distinction is in the board itself and the firmware setting the speeds etc, then it's a rebadge in my books. Nothing stopping OEMs from changing these around, and this does in fact happen with the OC cards. What is the difference between a rebadged chip with an OC vs one of these?