Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
The Silvermont Module and Caches
Like AMD’s Bobcat and Jaguar designs, Silvermont is modular. The default Silvermont building block is a two-core/two-thread design. Each core is equally capable and there’s no shared execution hardware. Silvermont supports up to 8-core configurations by placing multiple modules in an SoC.
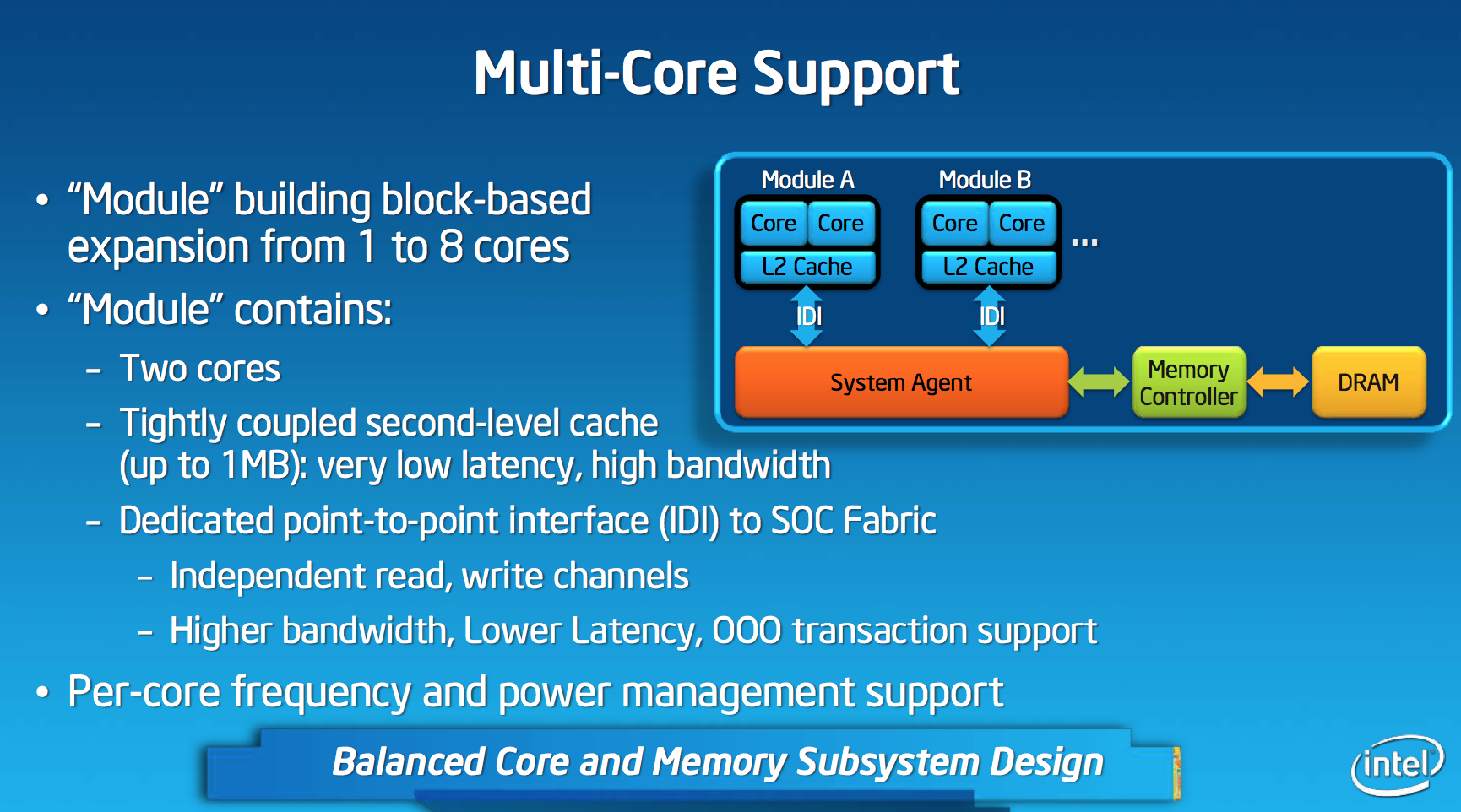
Each module features a shared 1MB L2 cache, a 2x increase over the core:cache ratio of existing Atom based processors. Despite the larger L2, access latency is reduced by 2 clocks. The default module size gives you clear indication as to where Intel saw Silvermont being most useful. At the time of its inception, I doubt Intel anticipated such a quick shift to quad-core smartphones otherwise it might’ve considered a larger default module size.
L1 cache sizes/latencies haven’t changed. Each Silvermont core features a 32KB L1 data cache and 24KB L1 instruction cache.
Silvermont Supports Independent Core Frequencies: Vindication for Qualcomm?
In all Intel Core based microprocessors, all cores are tied to the same frequency - those that aren’t in use are simply shut off (power gated) to save power. Qualcomm’s multi-core architecture has always supported independent frequency planes for all CPUs in the SoC, something that Intel has always insisted was a bad idea. In a strange turn of events, Intel joins Qualcomm in offering the ability to run each core in a Silvermont module at its own independent frequency. You could have one Silvermont core running at 2.4GHz and another one running at 1.2GHz. Unlike Qualcomm’s implementation, Silvermont’s independent frequency planes are optional. In a split frequency case, the shared L2 cache always runs at the higher of the two frequencies. Intel believes the flexibility might be useful in some low cost Silvermont implementations where the OS actively uses core pinning to keep threads parked on specific cores. I doubt we’ll see this on most tablet or smartphone implementations of the design.
From FSB to IDI
Atom and all of its derivatives have a nasty secret: they never really got any latency benefits from integrating a memory controller on die. The first implementation of Atom was a 3-chip solution, with the memory controller contained within the North Bridge. The CPU talked to the North Bridge via a low power Front Side Bus implementation. This setup should sound familiar to anyone who remembers Intel architectures from the late 90s up to the mid 2000s. In pursuit of integration, Intel eventually brought the memory controller and graphics onto a single die. Historically, bringing the memory controller onto the same die as the CPU came with a nice reduction in access latency - unfortunately Atom never enjoyed this. The reasoning? Atom never ditched the FSB interface.
Even though Atom integrated a memory controller, the design logically looked like it did before. Integration only saved Intel space and power, it never granted it any performance. I suspect Intel did this to keep costs down. I noticed the problem years ago but completely forgot about it since it’s been so long. Thankfully, with Silvermont the FSB interface is completely gone.
Silvermont instead integrates the same in-die interconnect (IDI) that is used in the big Core based processors. Intel’s IDI is a lightweight point to point interface that’s far lower overhead than the old FSB architecture. The move to IDI and the changes to the system fabric are enough to improve single threaded performance by low double digits. The gains are even bigger in heavily threaded scenarios.
Another benefit of moving away from a very old FSB to IDI is increased flexibility in how Silvermont can clock up/down. Previously there were fixed FSB:CPU ratios that had to be maintained at all times, which meant the FSB had to be lowered significantly when the CPU was running at very low frequencies. In Silvermont, the IDI and CPU frequencies are largely decoupled - enabling good bandwidth out of the cores even at low frequency levels.
The System Agent
Silvermont gains an updated system agent (read: North Bridge) that’s much better at allowing access to main memory. In all previous generation Atom architectures, virtually all memory accesses had to happen in-order (Clover Trail had some minor OoO improvements here). Silvermont’s system agent now allows reordering of memory requests coming in from all consumers/producers (e.g. CPU cores, GPU, etc...) to optimize for performance and quality of service (e.g. ensuring graphics demands on memory can regularly pre-empt CPU requests when necessary).








174 Comments
View All Comments
Jaybus - Monday, May 13, 2013 - link
In the full Win 8 tablet market, I don't think any low power SoC is going to be adequate to compete against 13 W Ivy Bridge.1d107 - Tuesday, May 7, 2013 - link
Did I miss memory bandwidth comparison with A6X? Will it support hi-res displays with acceptable performance? And by performance I mean not playing Angry birds on a so 1366x768 or even 1080p, but smooth scrolling and fast text rendering on a 3840x2400 screen. This would be cool for a descent Windows tablet with an external display attached.I'm afraid that by the time Silvermont is released and incorporated into actual products, Apple will have iPad 5 already shipping with A7X chip that will have twice the battery life, while maintaining better performance than A6X. They will need it for the iPad mini, but full-sized iPads will benefit also.
fteoath64 - Tuesday, May 7, 2013 - link
One cannot know what the A7X can deliver but can take a couple of guesses. Here: 1) Optimise Swift further with pipeline shortening but still staying on A9 architecture, 2) Leap to A15 dual core with minimal optimization. On gpu side, it becomes more tricky as Pvr554 being used is Max out at 4 cores, they would have to either jack that up(6 cores ?) or jack up the clock rate.Remember that S800 and T4 products are yet to be announced so there is some time to watch the progression.
Intel's key weakness here is STILL on gpu side. To put 3 cores of PVR 554 would eat a lot of power while giving it respectable performance. Going 1/4 HD4000 is just a dumb idea as the drivers are very bad and will remain so. Again too much power budget to slot in 8EU on SIlvermont quad.
On thing is for sure: Silvermont is going to make a wicked NAS cpu!.
thunng8 - Wednesday, May 8, 2013 - link
1) Swift is not A9 architecture.2) A7X will likely get the next generation PVR graphics chip (SGX Series 6 aka Rogue).
nunomoreira10 - Wednesday, May 8, 2013 - link
considering the power budget, 1/4 hd4000 is quite goodhd4000 consumes around 10w during games, 1/4 with clock cut down and power improvements we should expect 1-2w which is the max they could allow.
drivers are good for the games normally played on tablets.
BSMonitor - Tuesday, May 7, 2013 - link
Awesome review! This is the one we have been waiting for from Windows Phone / Windows Tablets!!Anand, is it the next Lumia that Intel has scored a design win?? x86 Windows 8 on a next gen Lumia??
warezme - Wednesday, May 8, 2013 - link
Sounds like Intel is going hammer time on the mobile SOC arena. It's gonna get ugly but very interesting.futbol4me - Wednesday, May 8, 2013 - link
Can someone out there answer a few questions for me?(1) If Intel Atom powered tablet were running android, do APPS available on Google Play need to be recompiled for the platform?
(2) Will a Windows8 Intel Atom powered tablet have enough horsepower to run android effectively as a Virtual Machine?
Do you think there is enough
biertourist - Wednesday, May 8, 2013 - link
To answer Question #2: Yes. Current Intel Atom tablets can run Android apps ala the "BlueStacks" app currently.rootheday - Thursday, May 9, 2013 - link
re #1, Android apps written in Dalvik/Java require no recompile because they are compiled against a virtual machine spec. Android apps written as "native" against ARM instruction set -> Intel has implemented a binary translation capability called Houdini that converts them to x86 on the fly and optimizes them in the background.