Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
OoOE
You’re going to come across the phrase out-of-order execution (OoOE) a lot here, so let’s go through a quick refresher on what that is and why it matters.
At a high level, the role of a CPU is to read instructions from whatever program it’s running, determine what they’re telling the machine to do, execute them and write the result back out to memory.
The program counter within a CPU points to the address in memory of the next instruction to be executed. The CPU’s fetch logic grabs instructions in order. Those instructions are decoded into an internally understood format (a single architectural instruction sometimes decodes into multiple smaller instructions). Once decoded, all necessary operands are fetched from memory (if they’re not already in local registers) and the combination of instruction + operands are issued for execution. The results are committed to memory (registers/cache/DRAM) and it’s on to the next one.
In-order architectures complete this pipeline in order, from start to finish. The obvious problem is that many steps within the pipeline are dependent on having the right operands immediately available. For a number of reasons, this isn’t always possible. Operands could depend on other earlier instructions that may not have finished executing, or they might be located in main memory - hundreds of cycles away from the CPU. In these cases, a bubble is inserted into the processor’s pipeline and the machine’s overall efficiency drops as no work is being done until those operands are available.
Out-of-order architectures attempt to fix this problem by allowing independent instructions to execute ahead of others that are stalled waiting for data. In both cases instructions are fetched and retired in-order, but in an OoO architecture instructions can be executed out-of-order to improve overall utilization of execution resources.
The move to an OoO paradigm generally comes with penalties to die area and power consumption, which is one reason the earliest mobile CPU architectures were in-order designs. The ARM11, ARM’s Cortex A8, Intel’s original Atom (Bonnell) and Qualcomm’s Scorpion core were all in-order. As performance demands continued to go up and with new, smaller/lower power transistors, all of the players here started introducing OoO variants of their architectures. Although often referred to as out of order designs, ARM’s Cortex A9 and Qualcomm’s Krait 200/300 are mildly OoO compared to Cortex A15. Intel’s Silvermont joins the ranks of the Cortex A15 as a fully out of order design by modern day standards. The move to OoO alone should be good for around a 30% increase in single threaded performance vs. Bonnell.
Pipeline
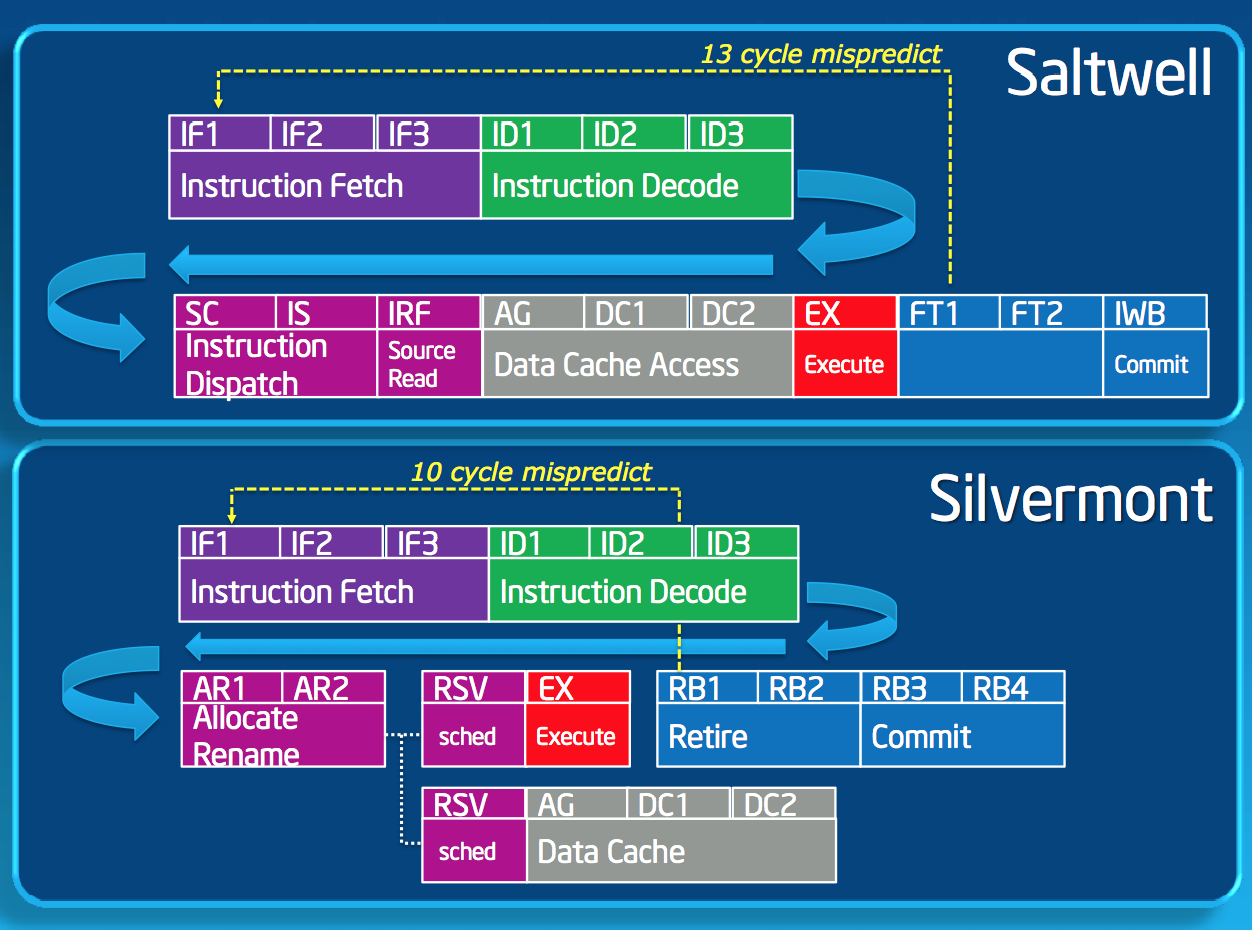
Silvermont changes the Atom pipeline slightly. Bonnell featured a 16 stage in-order pipeline. One side effect to the design was that all operations, including those that didn’t have cache accesses (e.g. operations whose operands were in registers), had to go through three data cache access stages even though nothing happened during those stages. In going out-of-order, Silvermont allows instructions to bypass those stages if they don’t need data from memory, effectively shortening the mispredict penalty from 13 stages down to 10. The integer pipeline depth now varies depending on the type of instruction, but you’re looking at a range of 14 - 17 stages.
Branch prediction improves tremendously with Silvermont, a staple of any progressive microprocessor architecture. Silvermont takes the gshare branch predictor of Bonnell and significantly increased the size of all associated data structures. Silvermont also added an indirect branch predictor. The combination of the larger predictors and the new indirect predictor should increase branch prediction accuracy.
Couple better branch prediction with a lower mispredict latency and you’re talking about another 5 - 10% increase in IPC over Bonnell.








174 Comments
View All Comments
Kevin G - Monday, May 6, 2013 - link
Actually I've gotten the impression from Anandtech that Intel has been so tardy on providing chips for the mobile market that they may have lost the fight before even showing up. Intel may have good designs and the best foundries but that doesn't matter if ARM competitors arrive first with 'good enough' designs to gobble up all the market share. There is a likely a bit of frustration here constantly hearing about good tech that never reaches its potential.There was the recent line in the news article here about Intel's CEO choice about how Intel is foundry that makes x86 processors. That choice was likely selected due to Intel's future of becoming an open foundry to 3rd party designs. Intel has done this to a limited degree already. They recently signed a deal with Microsemi to manufacture FPGA's on Intel's 22 nm process. Presumably future Microsemi ARM based SoC + FGPA chips will also be manufactured by Intel as well.
Kidster3001 - Tuesday, May 7, 2013 - link
Intel has publicly stated that it's foundry business will never make products for a competitor. That means no ARM SoC's in Intel fabs.Kevin G - Tuesday, May 7, 2013 - link
Intel isn't active in the FPGA area, well there than manufacturing them for a handful of 3rd parties. The inclusion of an ARM core inside a SOC + FGPA design wouldn't be seen as a direct competitor. Indirectly it definitely would be a competitor but then again just the FPGA alone would be an indirect competitor.name99 - Monday, May 6, 2013 - link
Actually the REAL history is- Intel article appears. All the ARM fans whine about how unfair and awful it is, and how it refers to a chip that will only be released in six months.
- ARM article appears. All the Intel fans whine about how unfair and awful it is, and how it refers to a chip that will only be released in six months.
- Apple (CPU) article appears. Non-Apple ARM and Intel fans both whine about how unfair it is (because of tight OS integration or something, and Apple is closed so it doesn't count).
Repeat every six months...
Bob Todd - Tuesday, May 7, 2013 - link
Winner winner chicken dinner. I love how butt hurt people get about any article comparing CPU or GPU performance of two or more competitors (speculatively or not). I have devices with Krait, Swift, Tegra 3, Bobcat, Llano, Ivy Bridge, etc. They all made sense at the time for one reason or another or I wouldn't have them. I'm excited about Slivermont, just like I'm excited about Jaguar, and whatever Apple/Samsung/Qualcom/Nvidia cook up next on the ARM side. It's an awesome time to be into mobile gadgets. Now I'll sit back and laugh at the e-peen waiving misguided fanboyism...axien86 - Monday, May 6, 2013 - link
Acer is shipping new V5 ultraportables based on AMD's Jaguar high performance per watt technology in 30 days. AMD is 10 to 20 times smaller than Intel, but with design wins from Sony, Microsoft and now many other OEMs, they are delivering real performance for real value.
By contrast Intel really has nothing to show, but endless public relations to compensate for a history of company that has been upstaged by smaller companies like AMD in forging real innovations in computing.
A5 - Monday, May 6, 2013 - link
If by "high performance per watt" you mean "less performance in a higher TDP" than sure. Intel trounces AMD in notebooks for a reason.As for the Sony/MS stuff, I doubt Intel even bid for those contracts.
kyuu - Monday, May 6, 2013 - link
I hope you're kidding. Bobcat-based designs have been superior to Atom for forever, and if you take graphics performance into account, then Atom has been nothing short of laughable. I wouldn't be surprised if Silvermont beats Jaguar in CPU performance, but it'll be a small delta, and Jaguar is coming out a full half-year ahead of Silvermont.It's also nice that Intel might get GPU performance around the level of the iPad 4's SoC by the end of the year, but I believe AMD's mobile graphics already handily surpass that and the ARM world will have moved on to solutions that handily surpass that by then as well. So, yet again, Intel will be well behind the GPU curve. It won't be laughably bad anymore, though, at least.
And I really love that last line. "Intel didn't get some design wins? Well, psh, they totally didn't even want those anyway."
kyuu - Monday, May 6, 2013 - link
Oh, and also not sure why you brought notebooks up when we're talking about architectures for very low-power devices like tablets, netbooks, and maybe some ultrathins. No one would claim that Trinity/Richland is at the same level of CPU performance as Ivy Bridge/Haswell. Personally, though, I'd still prefer an AMD solution for a notebook for the superior graphics, lower price, and more-than-adequate CPU performance.xTRICKYxx - Tuesday, May 7, 2013 - link
This is where I want AMD to come into play. Their low power CPU's are so much better than Atom ever was, and always had superior graphics.