NVIDIA’s GeForce GTX Titan Review, Part 2: Titan's Performance Unveiled
by Ryan Smith & Rahul Garg on February 21, 2013 9:00 AM ESTTitan’s Compute Performance (aka Ph.D Lust)
Because GK110 is such a unique GPU from NVIDIA when it comes to compute, we’re going to shake things up a bit and take a look at compute performance first before jumping into our look at gaming performance.
On a personal note, one of the great things about working at AnandTech is all the people you get to work with. Anand himself is nothing short of fantastic, but what other review site also has a Brian Klug or a Jarred Walton? We have experts in a number of fields, and as a computer technology site that includes of course includes experts in computer science.
What I’m trying to say is that for the last week I’ve been having to fend off our CS guys, who upon hearing I had a GK110 card wanted one of their own. If you’ve ever wanted proof of just how big a deal GK110 is – and by extension Titan – you really don’t have to look too much farther than that.
Titan, its compute performance, and the possibilities it unlocks is a very big deal for researchers and other professionals that need every last drop of compute performance that they can get, for as cheap as they can get it. This is why on the compute front Titan stands alone; in NVIDIA’s consumer product lineup there’s nothing like it, and even AMD’s Tahiti based cards (7970, etc), while potent, are very different from GK110/Kepler in a number of ways. Titan essentially writes its own ticket here.
In any case, as this is the first GK110 product that we have had access to, we couldn’t help but run it through a battery of tests. The Tesla K20 series may have been out for a couple of months now, but at $3500 for the base K20 card, Titan is the first GK110 card many compute junkies are going to have real access to.
To that end I'd like to introduce our newest writer, Rahul Garg, who will be leading our look at Titan/GK110’s compute performance. Rahul is a Ph.D student specializing in the field of parallel computing and GPGPU technology, making him a prime candidate for taking a critical but nuanced look at what GK110 can do. You will be seeing more of Rahul in the future, but first and foremost he has a 7.1B transistor GPU to analyze. So let’s dive right in.
By: Rahul Garg
For compute performance, we first looked at two common benchmarks: GEMM (measures performance of dense matrix multiplication) and FFT (Fast Fourier Transform). These numerical operations are important in a variety of scientific fields. GEMM is highly parallel and typically compute heavy, and one of the first tests of performance and efficiency on any parallel architecture geared towards HPC workloads. FFT is typically memory bandwidth bound but, depending upon the architecture, can be influenced by inter-core communication bandwidth. Vendors and third-parties typically supply optimized libraries for these operations. For example, Intel supplies MKL for Intel processors (including Xeon Phi) and AMD supplies ACML and OpenCL-based libraries for their CPUs and GPUs respectively. Thus, these benchmarks measure the performance of the combination of both the hardware and software stack.
For GEMM, we tested the performance of NVIDIA's CUBLAS library supplied with CUDA SDK 5.0, on SGEMM (single-precision/fp32 GEMM) and DGEMM (double precision/fp64 GEMM) on square matrices of size 5k by 5k. For SGEMM on Titan, the data reported here was collected with boost disabled. We also conducted the experiments with boost enabled on Titan, but found that the performance was effectively equal to the non-boost case. We assume that it is because our test ran for a very short period of time and perhaps did not trigger boost. Therefore, for the sake of simpler analysis, we report the data with boost disabled on the Titan. If time permits, we may return to the boost issue in a future article for this benchmark.
Apart from the results collected by us for GTX Titan, GTX 680 and GTX 580, we refer to experiments conducted by Matsumoto, Nakasato and Sedukin reported in a technical report filed at the University of Aizu about GEMM on Radeon 7970. Their exact parameters and testbed are different than ours, and we include their results for illustrative purposes, as a ballpark estimate only. The results are below.

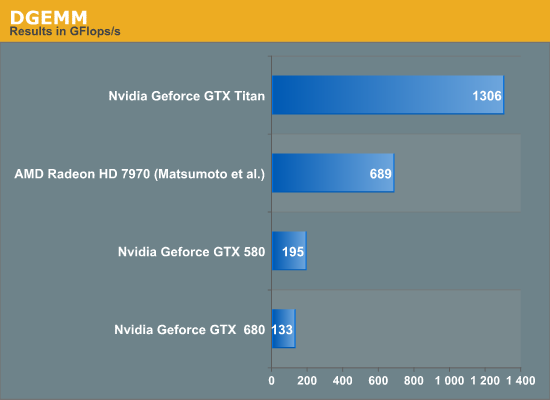
Titan rules the roost amongst the three listed cards in both SGEMM and DGEMM by a wide margin. We have not included Intel's Xeon Phi in this test, but the TItan's achieved performance is higher than the theoretical peak FLOPS of the current crop of Xeon Phi. Sharp-eyed readers will have observed that the Titan achieves about 1.3 teraflops on DGEMM, while the listed fp64 theoretical peak is also 1.3 TFlops; we were not expecting 100% of peak on the Titan in DGEMM. NVIDIA clarified that the fp64 rating for the Titan is a conservative estimate. At 837MHz, the calculated fp64 peak of Titan is 1.5 TFlops. However, under heavy load in fp64 mode, the card may underclock below the listed 837MHz to remain within the power and thermal specifications. Thus, fp64 ALU peak can vary between 1.3 TFlops and 1.5 TFlops and our DGEMM results are within expectations.
Next, we consider the percentage of fp32 peak achieved by the respective SGEMM implementations. These are plotted below.
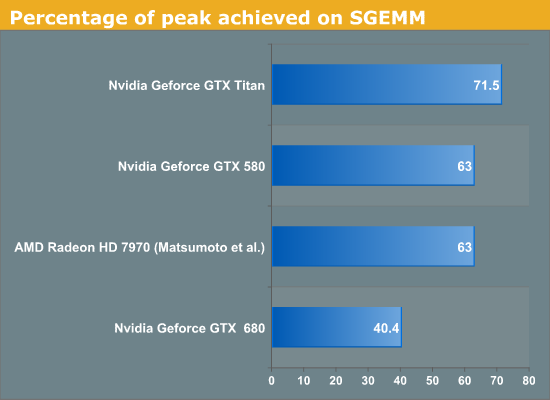
Titan achieves about 71% of its peak while GTX 680 only achieves about 40% of the peak. It is clear that while both GTX 680 and Titan are said to be Kepler architecture chips, Titan is not just a bigger GTX 680. Architectural tweaks have been made that enable it to reach much higher efficiency than the GTX 680 on at least some compute workloads. GCN based Radeon 7970 obtains about 63% of peak on SGEMM using Matsumoto et al. algorithm, and Fermi based GTX 580 also obtains about 63% of peak using CUBLAS.
For FFT, we tested the performance of 1D complex-to-complex inplace transforms of size 225 using the CUFFT library. Results are given below.
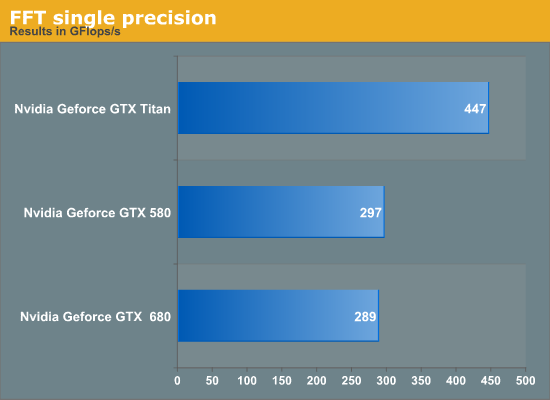
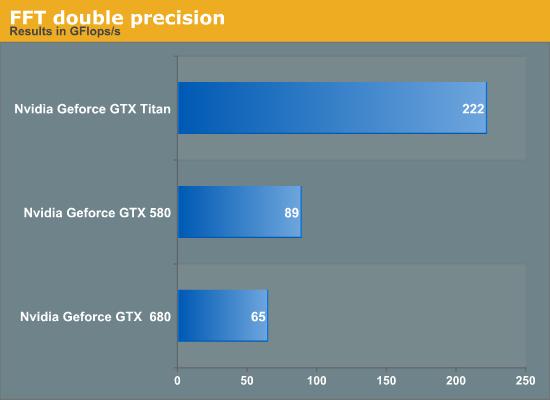
Titan outperforms the GTX 680 in FFT by about 50% in single-precision. We suspect this is primarily due to increased memory bandwidth on Titan compared to GTX 680 but we have not verified this hypothesis. GTX 580 has a slight lead over the GTX 680. Again, if time permits, we may return to the benchmark for a deeper analysis. Titan achieves about 3.4x the performance of GTX 680 but this is not surprising given the poor fp64 execution resources on the GTX 680.
We then looked at an in-house benchmark called SystemCompute, developed by our own Ian Cutress. The benchmark tests the performance on a variety of sample kernels that are representative of some scientific computing applications. Ian described the CPU version of these benchmarks in a previous article. Ian wrote the GPU version of the benchmarks in C++ AMP, which is a relatively new GPGPU API introduced by Microsoft in VS2012.
Microsoft's implementation of AMP compiles down to DirectCompute shaders. These are all single-precision benchmarks and should run on any DX11 capable GPU. The benchmarks include 2D and 3D finite difference solvers, 3d particle movement, n-body benchmark and a simple matrix multiplication algorithm. Boost is enabled on both the Titan and GTX 680 for this benchmark. We give the score reported by the benchmark for both cards, and report the speedup of the Titan over 680. Speedup greater than 1 implies Titan is faster, while less than 1 implies a slowdown.
| Benchmark | GTX 580 | GTX 680 | GTX Titan |
Speedup of Titan over GTX 680 |
| 2D FD | 9053 | 8445 | 12461 | 1.47 |
| 3D FD | 3133 | 3827 | 5263 | 1.37 |
| 3DPmo | 41722 | 26955 | 40397 | 1.49 |
| MatMul | 172 | 197 | 229 | 1.16 |
| nbody | 918 | 1517 | 2418 | 1.59 |
The benchmarks show between 16% and 60% improvement, with the most improvement coming from the relatively FLOP-heavy n-body benchmark. Interestingly, GTX 580 wins over the Titan in 3DPMo and wins over the 680 in 3DPmo and 2D.
Overall, GTX Titan is an impressive accelerator from compute perspective and posts large gains over its predecessors.








337 Comments
View All Comments
CeriseCogburn - Saturday, February 23, 2013 - link
Stop whining along with the rest of them, grow a set, get a job, and buy two of them.Might do you some good.
Alucard291 - Sunday, February 24, 2013 - link
Unlike you, I have a job :)chizow - Sunday, February 24, 2013 - link
Good point, I'd tend to agree with that assessment as anyone who actually works for their money would not be so eager to part with it so quickly in $1K denominations for what amounts to a glorified pinball machine.He's probably a kid who has never had to work a day in his life or a basement dweller who has no hope of ever buying one of these anyways.
CeriseCogburn - Sunday, February 24, 2013 - link
And now with the pure troll, the lying idiot conspiracist nVidia hater takes on the pure personal attack for a big fat ZERO score.Congratulations, you and your pure troll can high five each other and both be wrong anyway, for another yer or two, or the rest of your whining crybaby posting PC herd idiot mentality lives.
Alucard291 - Friday, March 8, 2013 - link
No no kid. You're the "pure troll here"So yeah go get a job and buy two of them. For yourself. Stop being angry at us for not being able to afford it
~lol~
wiyosaya - Thursday, February 21, 2013 - link
While I understand your frustrations, IMHO, this is a card aimed at those wanting the compute performance of a Tesla at 1/3 the cost. As I see it, nVidia shot themselves in the foot for compute performance with the 680, and as such, I bet that 680 sales were less than expected primarily because of its crappy compute performance in comparison to say even a 580. This may have been their strategy, though, as they might have expected $3,500 Teslas to fly off the shelf.I am also willing to bet that Teslas did not fly off the shelf, and that in order to maintain good sales, they have basically dropped the price of the first GK110s to something that is reasonable with this card. Once can now buy 3.5 Titan's for the price of the entry level GK110 Tesla, and I highly expect nVidia to make a profit rather than the killing that they might have thought possible on the GK110 Teslas.
That said, I bet that nVidia gets a sht load of orders for this card from new HPC builders and serious CAD/CAE workstation suppliers. Many CAD/CAE software packages like SolidWorks and Maple support GPGPUs in their code making this card a bargain for their builds.
My apologies, to all the gamers here but us compute nerds are drooling over this card. I only wish I could afford one to put in my i7-3820 build from July. It is more than 2x what I paid for a 580 back then, and the 580 buy was for its compute performance.
atlr - Thursday, February 21, 2013 - link
wiyosaya, I am trying to come up to speed on comparing compute performance between Nvidia and AMD options. Is the Titan drool-worthy only for software that only uses CUDA and not OpenCL? This reminds me of the days of Glide versus OpenGL APIs.trajan2448 - Friday, February 22, 2013 - link
AMDs fps numbers are overstated. They figured out a trick to make runt frames, or frames which are not actually rendered to trigger the fps monitor as a real fully rendered frame. This is real problem for AMD much worse than the latency problem. Crossfire is a disaster which is why numerous reviewers including Tech Report have written that Crossfire produces higher fps but feels less smooth than Nvidia.Check this article out. http://www.pcper.com/reviews/Graphics-Cards/NVIDIA...
chizow - Saturday, February 23, 2013 - link
That's an awesome analysis by PCPer, thanks for linking that. Might end up being the biggest driver cheat scandal in history. Runt framesgate lol.CeriseCogburn - Saturday, February 23, 2013 - link
HUGE amd cheat.It's their standard operating procedure.
The fanboys will tape their mouths, gouge out their eyes and stick fingers in their ears and chant: "I'm not listening".