NVIDIA's GeForce GTX Titan, Part 1: Titan For Gaming, Titan For Compute
by Ryan Smith on February 19, 2013 9:01 AM ESTTitan For Compute
Titan, as we briefly mentioned before, is not just a consumer graphics card. It is also a compute card and will essentially serve as NVIDIA’s entry-level compute product for both the consumer and pro-sumer markets.
The key enabler for this is that Titan, unlike any consumer GeForce card before it, will feature full FP64 performance, allowing GK110’s FP64 potency to shine through. Previous NVIDIA cards either had very few FP64 CUDA cores (GTX 680) or artificial FP64 performance restrictions (GTX 580), in order to maintain the market segmentation between cheap GeForce cards and more expensive Quadro and Tesla cards. NVIDIA will still be maintaining this segmentation, but in new ways.
| NVIDIA GPU Comparison | ||||||
| Fermi GF100 | Fermi GF104 | Kepler GK104 | Kepler GK110 | |||
| Compute Capability | 2.0 | 2.1 | 3.0 | 3.5 | ||
| Threads/Warp | 32 | 32 | 32 | 32 | ||
| Max Warps/SM(X) | 48 | 48 | 64 | 64 | ||
| Max Threads/SM(X) | 1536 | 1536 | 2048 | 2048 | ||
| Register File | 32,768 | 32,768 | 65,536 | 65,536 | ||
| Max Registers/Thread | 63 | 63 | 63 | 255 | ||
| Shared Mem Config |
16K 48K |
16K 48K |
16K 32K 48K |
16K 32K 48K |
||
| Hyper-Q | No | No | No | Yes | ||
| Dynamic Parallelism | No | No | No | Yes | ||
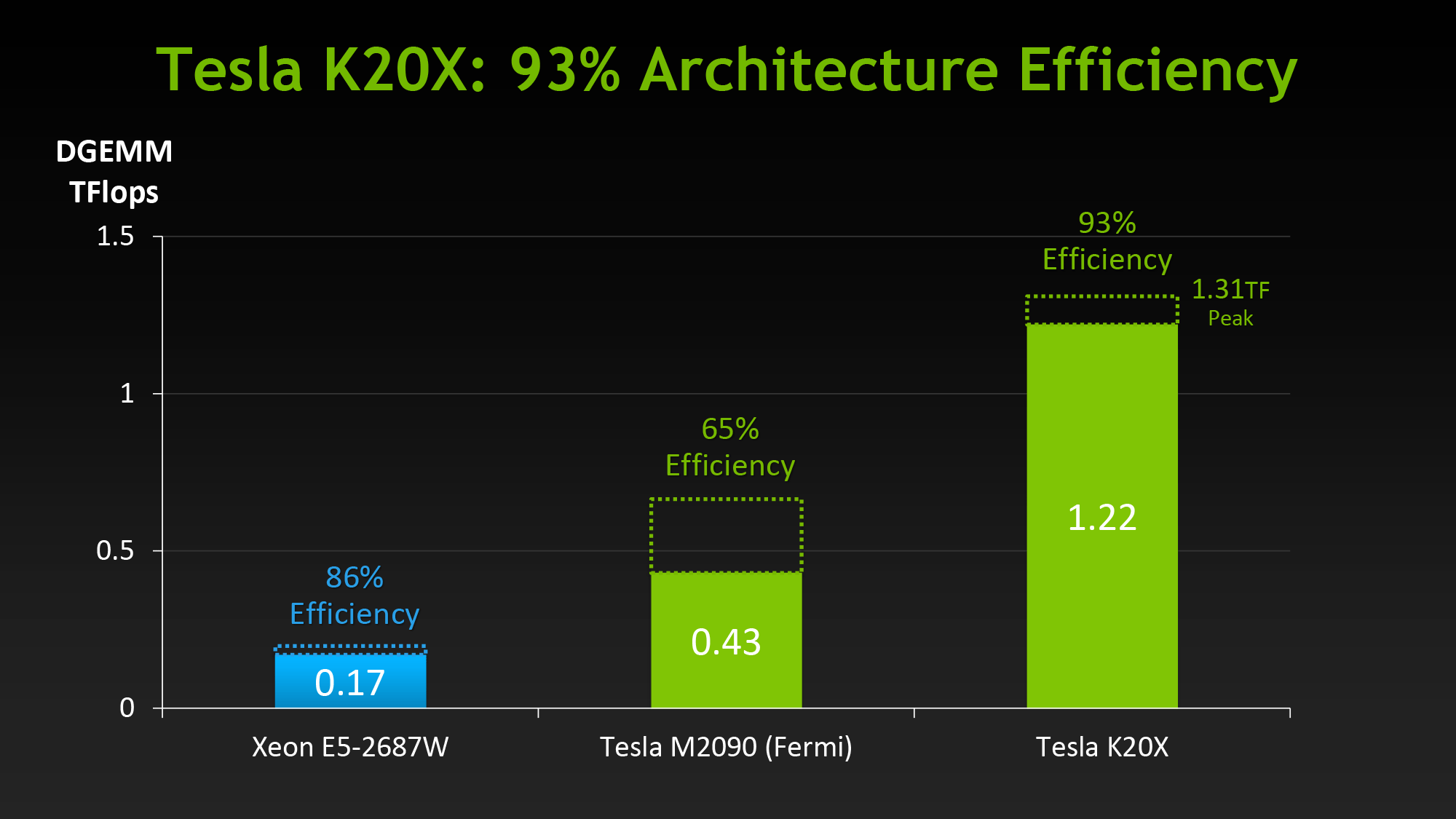
We’ve covered GK110’s compute features in-depth in our look at Tesla K20 so we won’t go into great detail here, but as a reminder, along with beefing up their functional unit counts relative to GF100, GK110 has several feature improvements to further improve compute efficiency and the resulting performance. Relative to the GK104 based GTX 680, Titan brings with it a much greater number of registers per thread (255), not to mention a number of new instructions such as the shuffle instructions to allow intra-warp data sharing. But most of all, Titan brings with it NVIDIA’s Kepler marquee compute features: HyperQ and Dynamic Parallelism, which allows for a greater number of hardware work queues and for kernels to dispatch other kernels respectively.
With that said, there is a catch. NVIDIA has stripped GK110 of some of its reliability and scalability features in order to maintain the Tesla/GeForce market segmentation, which means Titan for compute is left for small-scale workloads that don’t require Tesla’s greater reliability. ECC memory protection is of course gone, but also gone is HyperQ’s MPI functionality, and GPU Direct’s RDMA functionality (DMA between the GPU and 3rd party PCIe devices). Other than ECC these are much more market-specific features, and as such while Titan is effectively locked out of highly distributed scenarios, this should be fine for smaller workloads.
There is one other quirk to Titan’s FP64 implementation however, and that is that it needs to be enabled (or rather, uncapped). By default Titan is actually restricted to 1/24 performance, like the GTX 680 before it. Doing so allows NVIDIA to keep clockspeeds higher and power consumption lower, knowing the apparently power-hungry FP64 CUDA cores can’t run at full load on top of all of the other functional units that can be active at the same time. Consequently NVIDIA makes FP64 an enable/disable option in their control panel, controlling whether FP64 is operating at full speed (1/3 FP32), or reduced speed (1/24 FP32).
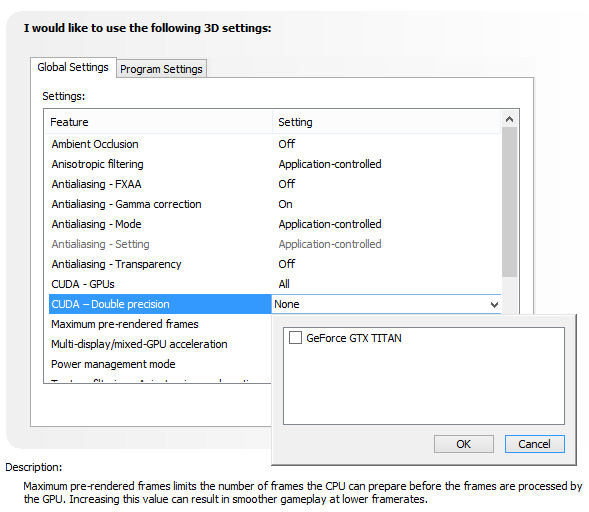
The penalty for enabling full speed FP64 mode is that NVIDIA has to reduce clockspeeds to keep everything within spec. For our sample card this manifests itself as GPU Boost being disabled, forcing our card to run at 837MHz (or lower) at all times. And while we haven't seen it first-hand, NVIDIA tells us that in particularly TDP constrained situations Titan can drop below the base clock to as low as 725MHz. This is why NVIDIA’s official compute performance figures are 4.5 TFLOPS for FP32, but only 1.3 TFLOPS for FP64. The former is calculated around the base clock speed, while the latter is calculated around the worst case clockspeed of 725MHz. The actual execution rate is still 1/3.
Unfortunately there’s not much else we can say about compute performance at this time, as to go much farther than this requires being able to reference specific performance figures. So we’ll follow this up on Thursday with those figures and a performance analysis.








157 Comments
View All Comments
hammer256 - Tuesday, February 19, 2013 - link
Ryan's analysis of the target market for this card is spot on: this card is for small scale HPC type workloads, where the researcher just want to build a desktop-like machine with a few of those cards. I know that's what I use for my research. To me, this is the real replacement of the GTX 580 for our purposes. The price hike is not great, but when put to context of the K20X, it's a bargain. I'm lusting to get 8 of these cards and get a Tyan GPU server.Gadgety - Tuesday, February 19, 2013 - link
While gamers see little benefit, it looks like this is the card for GPU rendering, provided the software developers at VRay, Octane and others find a way to tap into this. So one of these can replace the 3xGTX580 3GBs.chizow - Tuesday, February 19, 2013 - link
Nvidia has completely lost their minds. Throwing in a minor bone with the non-neutered DP performance does not give them license to charge $1K for this part, especially when DP on previous flagship parts carried similar performance relative to Tesla.First the $500 for a mid-range ASIC in GTX 680, then $1200 GTX 690 and now a $1000 GeForce Titan. Unbelievable. Best of luck Nvidia, good luck competing with the next-gen consoles at these price points, or even with yourselves next generation.
While AMD is still at fault in all of this for their ridiculous launch pricing for the 7970, these recent price missteps from Nvidia make that seem like a distant memory.
ronin22 - Wednesday, February 20, 2013 - link
Bullshit of a typical NV hater.The compute-side of the card isn't a minor bone, it's its prime feature, along with the single-chip GTX690-like performance.
"especially when DP on previous flagship parts carried similar performance relative to Tesla"
Bullshit again.
Give me a single card that is anywhere near the K20 in DP performance and we'll talk.
You don't understand the philosophy of this card, as many around here.
Thanksfully, the real intended audience is already recognizing the awesomeness of this card (read previous comments).
You can go back to playing BF3 on your 79xx, but please close the door behind you on your way out ;)
chizow - Wednesday, February 20, 2013 - link
Heh, your ignorant comments couldn't be further from the truth about being an "NV hater". I haven't bought an ATI/AMD card since the 9700pro (my gf made the mistake of buying a 5850 though, despite my input) and previously, I solely purchased *multiple* Nvidia cards in this flagship market for the last 3 generations.I have a vested interest in Nvidia in this respect as I enjoy their products, so I've never rooted for them to fail, until now. It's obvious to me now that between AMD's lackluster offerings and ridiculous launch prices along with Nvidia's greed with their last two high-end product launches (690 and Titan), that they've completely lost touch with their core customer base.
Also, before you comment ignorantly again, please look up the DP performance of GTX 280 and GTX 480/580 relative to their Tesla counterparts. You will see they are still respectable, ~1/8th of SP performance, which was still excellent compared to the completely neutered 1/32 DP of GK104 Kepler. That's why there is still a high demand for flagship Fermi parts and even GT200 despite their overall reputation as a less desirable part due to their thermal characteristics.
Lastly, I won't be playing BF3 on a 7970, try a pair of GTX 670s in SLI. There's a difference between supporting a company through sound purchasing decisions and stupidly pissing away $1K for something that cost $500-$650 in the past.
The philosophy of this card is simple: Rob stupid people of their money. I've seen enough of this in the past from the same target audience and generally that feeling of "awesomeness" is quickly replaced by buyer's remorse as they realize that slightly higher FPS number in the upper left of their screen isn't worth the massive number on their credit card statement.
CeriseCogburn - Sunday, February 24, 2013 - link
That one's been pissing acid since the 680 launch, failed and fails to recognize the superior leap of the GTX580 over the prior gen, which gave him his mental handicap believing he can get something for nothing, along with sucking down the master amd fanboy Charlie D's rumor about the "$350" flagship nVidia card blah blah blah 680 blah blah second tier blah blah blah.So instead the rager now claims he wasted near a grand on two 670's - R O F L - the lunatics never end here man.
bamboo69 - Tuesday, February 19, 2013 - link
Origin is using EK Waterblocks? i hope they arentt nickel plated, their nickel blocks flakeKnock24 - Wednesday, February 20, 2013 - link
I've seen it mentioned in the article that Titan has HyperQ support, but I've also read the opposite elsewhere.Can anyone confirm that HyperQ is supported? I'm guessing the simpleHyperQ Cuda SDK example might reveal if it's supported or not.
torchedguitar - Wednesday, February 20, 2013 - link
HyperQ actually means two separate things... One part is the ability to have a process act as a server, providing access to the GPU for other MPI processes. This is supported on Linux using Tesla cards (e.g. K20X) only, so it won't work on GTX Titan (it does work on Titan the supercomputer, though). The other part of HyperQ is that there are multiple hardware queues available for managing the work on multiple CUDA streams. GTX Titan DOES support this part, although I'm not sure just how many of these will be enabled (it's a tradeoff, having more hardware streams allows more flexibility in launching concurrent kernels, but also takes more memory and takes more time to initialize). The simpleHyperQ sample is a variation of the concurrentKernels sample (just look at the code), and it shows how having more hardware channels cuts down on false dependencies between kernels in different streams. You put things in different stream because they have no dependencies on each other, so in theory nothing in stream X should ever get stuck waiting for something in stream Y. When that does happen due to hitting limits of the hardware, it's a false dependency. An example would be when you try to time a kernel launch by wrapping it with CUDA event records (this is the simpleHyperQ sample). GPUs before GK110 only have one hardware stream, and if you take a program that launches kernels concurrently in separate streams, and wrap all the kernels with CUDA event records, you'll see that suddenly the kernels run one-at-a-time instead of all together. This is because in order to do the timing for the event, the single hardware channel queues up the other launches while waiting for each kernel to finish, then it records the end time in the event, then goes on to the next kernel. With HyperQ's addition of more hardware streams, you get around this problem. Run the simpleHyperQ sample on a 580 or a 680 through a tool like Nsight and look at the timeline... You'll see all the work in the streams show up like stair steps -- even though they're in different streams, they happen one at a time. Now run it on a GTX Titan or a K20 and you'll see many of the kernels are able to completely overlap. If 8 hardware streams are enabled, the app will finish 8x faster, or if 32 are enabled, 32x faster.Now, this sample is extremely contrived, just to illustrate the feature. In reality, overlapping kernels won't buy you much speedup if you're already launching big enough kernels to use the GPU effectively. In that case, there shouldn't much room left for overlapping kernels, except when you have unbalanced workloads where many threads in a kernel finish quickly but a few stragglers run way longer. With HyperQ, you greatly increase your chances that kernels in other streams can immediately start using the resources freed up when some of the threads in a kernel finish early, instead of waiting for all threads in the kernel to finish before starting the next kernel.
vacaloca - Monday, March 4, 2013 - link
I wanted to say that you hit the nail on the head... I just tested the simpleHyperQ example, and indeed, the Titan has 8 hardware streams enabled. For every multiple higher than 8, and the "Measured time for sample" goes up.