NVIDIA's GeForce GTX Titan, Part 1: Titan For Gaming, Titan For Compute
by Ryan Smith on February 19, 2013 9:01 AM ESTTitan For Compute
Titan, as we briefly mentioned before, is not just a consumer graphics card. It is also a compute card and will essentially serve as NVIDIA’s entry-level compute product for both the consumer and pro-sumer markets.
The key enabler for this is that Titan, unlike any consumer GeForce card before it, will feature full FP64 performance, allowing GK110’s FP64 potency to shine through. Previous NVIDIA cards either had very few FP64 CUDA cores (GTX 680) or artificial FP64 performance restrictions (GTX 580), in order to maintain the market segmentation between cheap GeForce cards and more expensive Quadro and Tesla cards. NVIDIA will still be maintaining this segmentation, but in new ways.
| NVIDIA GPU Comparison | ||||||
| Fermi GF100 | Fermi GF104 | Kepler GK104 | Kepler GK110 | |||
| Compute Capability | 2.0 | 2.1 | 3.0 | 3.5 | ||
| Threads/Warp | 32 | 32 | 32 | 32 | ||
| Max Warps/SM(X) | 48 | 48 | 64 | 64 | ||
| Max Threads/SM(X) | 1536 | 1536 | 2048 | 2048 | ||
| Register File | 32,768 | 32,768 | 65,536 | 65,536 | ||
| Max Registers/Thread | 63 | 63 | 63 | 255 | ||
| Shared Mem Config |
16K 48K |
16K 48K |
16K 32K 48K |
16K 32K 48K |
||
| Hyper-Q | No | No | No | Yes | ||
| Dynamic Parallelism | No | No | No | Yes | ||
We’ve covered GK110’s compute features in-depth in our look at Tesla K20 so we won’t go into great detail here, but as a reminder, along with beefing up their functional unit counts relative to GF100, GK110 has several feature improvements to further improve compute efficiency and the resulting performance. Relative to the GK104 based GTX 680, Titan brings with it a much greater number of registers per thread (255), not to mention a number of new instructions such as the shuffle instructions to allow intra-warp data sharing. But most of all, Titan brings with it NVIDIA’s Kepler marquee compute features: HyperQ and Dynamic Parallelism, which allows for a greater number of hardware work queues and for kernels to dispatch other kernels respectively.
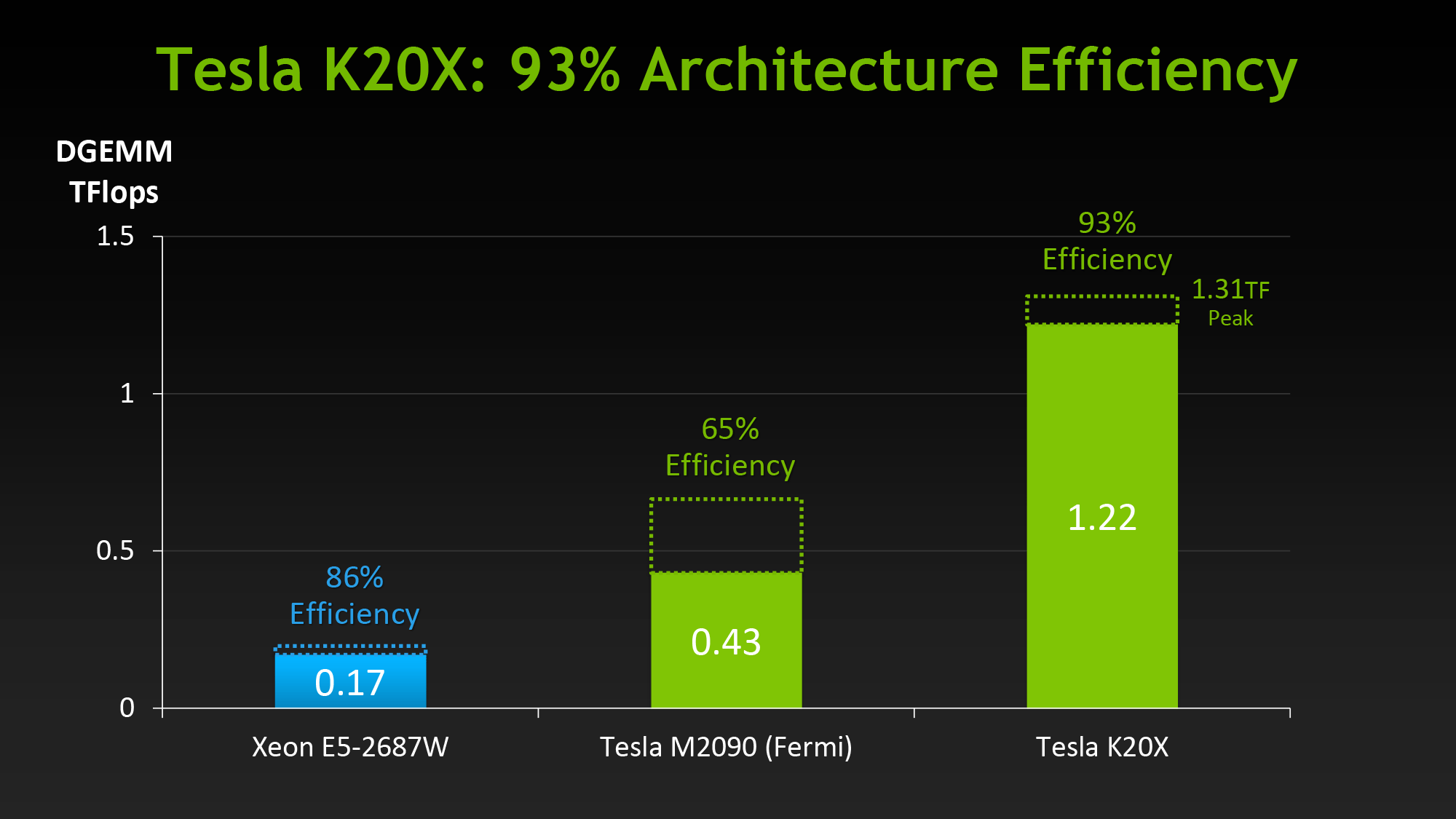
With that said, there is a catch. NVIDIA has stripped GK110 of some of its reliability and scalability features in order to maintain the Tesla/GeForce market segmentation, which means Titan for compute is left for small-scale workloads that don’t require Tesla’s greater reliability. ECC memory protection is of course gone, but also gone is HyperQ’s MPI functionality, and GPU Direct’s RDMA functionality (DMA between the GPU and 3rd party PCIe devices). Other than ECC these are much more market-specific features, and as such while Titan is effectively locked out of highly distributed scenarios, this should be fine for smaller workloads.
There is one other quirk to Titan’s FP64 implementation however, and that is that it needs to be enabled (or rather, uncapped). By default Titan is actually restricted to 1/24 performance, like the GTX 680 before it. Doing so allows NVIDIA to keep clockspeeds higher and power consumption lower, knowing the apparently power-hungry FP64 CUDA cores can’t run at full load on top of all of the other functional units that can be active at the same time. Consequently NVIDIA makes FP64 an enable/disable option in their control panel, controlling whether FP64 is operating at full speed (1/3 FP32), or reduced speed (1/24 FP32).
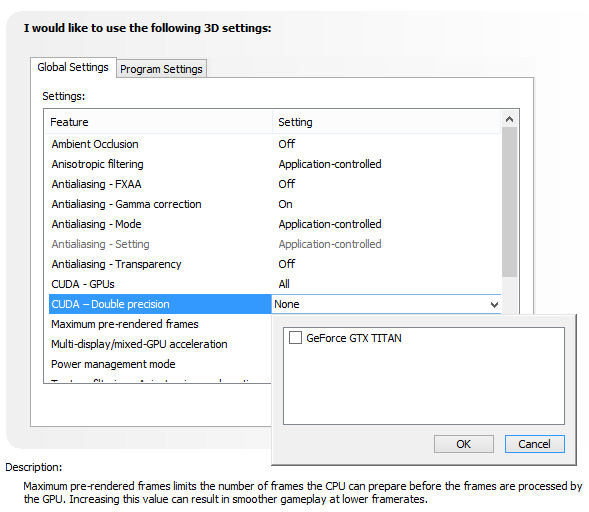
The penalty for enabling full speed FP64 mode is that NVIDIA has to reduce clockspeeds to keep everything within spec. For our sample card this manifests itself as GPU Boost being disabled, forcing our card to run at 837MHz (or lower) at all times. And while we haven't seen it first-hand, NVIDIA tells us that in particularly TDP constrained situations Titan can drop below the base clock to as low as 725MHz. This is why NVIDIA’s official compute performance figures are 4.5 TFLOPS for FP32, but only 1.3 TFLOPS for FP64. The former is calculated around the base clock speed, while the latter is calculated around the worst case clockspeed of 725MHz. The actual execution rate is still 1/3.
Unfortunately there’s not much else we can say about compute performance at this time, as to go much farther than this requires being able to reference specific performance figures. So we’ll follow this up on Thursday with those figures and a performance analysis.








157 Comments
View All Comments
tipoo - Tuesday, February 19, 2013 - link
It seems if you were targetting maximum performance, being able to decouple them would make sense, as the GPU would both have higher thermal headroom as well as run cooler on average with the fan working harder, thus letting it hit the boost clocks higher.Ryan Smith - Tuesday, February 19, 2013 - link
You can always manually adjust the fan curve. NVIDIA is simply moving it with the temperature target by default.Golgatha - Tuesday, February 19, 2013 - link
WTF nVidia!? Seriously, WTF!?$1000 for a video card. Are they out of the GD minds!?
imaheadcase - Tuesday, February 19, 2013 - link
No, read the article you twat.tipoo - Tuesday, February 19, 2013 - link
If they released a ten thousand dollar card, what difference would it make to you? This isn't' exactly their offering for mainstream gamers.jackstar7 - Tuesday, February 19, 2013 - link
I understand that my setup is a small minority, but I have to agree with the review about the port configuration. Not moving to multi-mDP on a card of this level just seems wasteful. As long as we're stuck with DVI, we're stuck with bandwidth limits that are going to stand in the way of 120Hz for higher resolutions (as seen on the Overlords and Catleap Extremes). Now I have to hope for some AIB to experiment with a $1000 card, or more likely wait for AMD to catch up to this.akg102 - Tuesday, February 19, 2013 - link
I'm glad Ryan got to experience this Nvidia circle jerk 'first-hand.'Arakageeta - Tuesday, February 19, 2013 - link
The Tesla- and Quadro-line GPUs have two DMA copy engines. This allows the GPU to simultaneously send and receive data on the full-duplex PCIe bus. However, the GeForce GPUs traditionally have only one DMA copy engine. Does the Titan have one or two copy engines? Since Titan has Tesla-class DP, I thought it might also have two copy engines.You can run the "deviceQuery" command that is a part of the CUDA SDK to find out.
Ryan Smith - Tuesday, February 19, 2013 - link
1 copy engine. The full output of DeviceQuery is below.CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX TITAN"
CUDA Driver Version / Runtime Version 5.0 / 5.0
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 6144 MBytes (6442123264 bytes)
(14) Multiprocessors x (192) CUDA Cores/MP: 2688 CUDA Cores
GPU Clock rate: 876 MHz (0.88 GHz)
Memory Clock rate: 3004 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Max Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536,65536), 3
D=(4096,4096,4096)
Max Layered Texture Size (dim) x layers 1D=(16384) x 2048, 2D=(16384,16
384) x 2048
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Mo
del)
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 3 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simu
ltaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 5.0, CUDA Runtime Versi
on = 5.0, NumDevs = 1, Device0 = GeForce GTX TITAN
tjhb - Tuesday, February 19, 2013 - link
Thank you!It seems to me NVIDIA are being incredibly generous to CUDA programmers with this card. I can hardly believe they've left FP64 capability at the full 1/3. (The ability to switch between 1/24 at a high clock and 1/3 at reduced clock seems ideal.) And we get 14/15 SMXs (a nice round number).
Do you know whether the TCC driver can be installed for this card?