SandForce TRIM Issue & Corsair Force Series GS (240GB) Review
by Kristian Vättö on November 22, 2012 1:00 PM ESTAS-SSD Incompressible Sequential Performance
The AS-SSD sequential benchmark uses incompressible data for all of its transfers. The result is a pretty big reduction in sequential write speed on SandForce based controllers, while other drives continue to work at roughly the same speed as with compressible data.
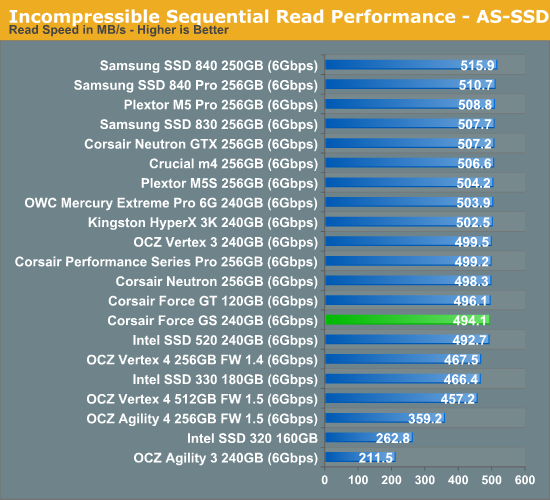
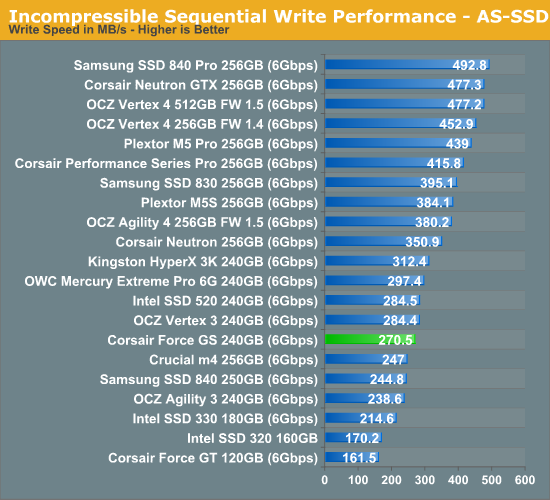
No surprises in incompressible sequential performance. Incompressible write performance is another aspect that SandForce is focusing on with their SF-3000 series; it's too early for concrete numbers but any and all improvements are welcome.








56 Comments
View All Comments
Sivar - Saturday, November 24, 2012 - link
Do you understand how data deduplication works?This is a rhetorical question. Those who have read your comments know the answer.
Please read the Wikipedia article on data deduplication, or some other source, before making further comments.
JellyRoll - Saturday, November 24, 2012 - link
I am repeating the comments above for you, since you referenced the Wiki I would kindly suggest that you might have a look at it yourself before commenting further."the intent of storage-based data deduplication is to inspect large volumes of data and identify large sections – such as entire files or large sections of files – that are identical, in order to store only one copy of it."
This happens without any regard to whether data is compressible or not.
If you have two matching sets of data, be they incompressible or not, they would be subject to deduplicatioin. It would merely require mapping to the same LBA addresses.
For instance, if you have two files that consist of largely incompressible data, but they are still carbon copies of each, they are still subject to data deduplication.
'nar - Monday, November 26, 2012 - link
You contradict yourself dude. You are regurgitating the words, but their meaning isn't sinking in. If you have two sets of incompressible data, then you have just made it compressible, ie. 2=1When the drive is hammered with incompressible data, there is only one set of data. If there were two or more sets of identical data then it would be compressible. De-duplication is a form of compression. If you have incompressible data, it cannot be de-duped.
Write amplification improvements come from compression, as in 2 files=1 file. Write less, lower amplification. Compressible data exhibits this, but incompressible data cannot because no two files are identical. Write amp is still high with incompressible data like everyone else. Your conclusion is backwards. De-duplication can only be applied on compressible data.
The previous article that Anand himself wrote suggested dedupe, it did not state that it was used, as that was not divulged. Either way, dedupe is similar to compression, hence the description. Although vague, it's the best we got from Sandforce to describe what they do.
What Sandforce uses is speculation anyhow, since it deals with trade secrets. If you really want to know you will have to ask Sandforce yourself. Good luck with that. :)
JellyRoll - Tuesday, November 27, 2012 - link
If you were to write 100 exact copies of a file, with each file consisting of incompressible data and 100MB in size, deduplication would only write ONE file, and link back to it repeatedly. The other 99 instances of the same file would not be repeatedly written.That is the very essence of deduplication.
SandForce processors do not exhibit this characteristic, be it 100 files or even only two similar files.
Of course SandForce doesn't disclose their methods, but full on terming it dedupe is misleading at best.
extide - Wednesday, November 28, 2012 - link
DeDuplication IS a form of compression dude. Period!!FunnyTrace - Wednesday, November 28, 2012 - link
SandForce presumably uses some sort of differential information update. When a block is modified, you find the difference between the old data and the new data. If the difference is small, you can just encode it over a smaller number of bits in the flash page. If you do the difference encoding, you cannot gc the old data unless you reassemble and rewrite the new data to a different location.Difference encoding requires more time (extra read, processing, etc). So, you must not do it when the write buffer is close to full. You can always choose whether or not you do differential encoding.
It is definitely not deduplication. You can think of it as compression.
A while back my prof and some of my labmates tried to guess their "DuraWrite" (*rolls eyes*) technology and this is the best guess have come up with. We didn't have the resources to reverse engineer their drive. We only surveyed published literature (papers, patents, presentations).
Oh, and here's their patent: http://www.google.com/patents/US20120054415
JellyRoll - Friday, November 30, 2012 - link
Hallelujah!Thanks funnytrace, i had a strong suspicion that it was data differencing. In the linked patent document it lists this 44 times. Maybe that many repetitions will sink in for some who still believe it is deduplication?
Also, here is a link to data differencing for those that wish to learn..
http://en.wikipedia.org/wiki/Data_differencing
Radoslav Danilak is listed as the inventor, not surprising i believe he was SandForce employee #2. He is now running Skyera, he is an excellent speaker btw.
extide - Saturday, November 24, 2012 - link
It's no different than SAN's and ZFS and other enterprise level storage solutions doing block level de-duplication. It's not magic, and it's not complicated. Why is it so hard to believe? I mean, you are correct that the drive has no idea what bytes go to what file, but it doesn't have to. As long as the controller sends the same data back to the host for a given read on an lba as the host sent to write, it's all gravvy. It doesnt matter what ends up on the flash,.JellyRoll - Saturday, November 24, 2012 - link
Aboslutely correct. However, they have much more powerful processors. You are talking about a very low wattage processor that cannot handle deduplication on this scale. SandForce also does not make the statement that they actually DO deduplication.FunBunny2 - Saturday, November 24, 2012 - link
here: http://thessdreview.com/daily-news/latest-buzz/ken..."Speaking specifically on SF-powered drives, Kent is keen to illustrate that the SF approach to real time compression/deduplication gives several key advantages."
Kent being the LSI guy.