NVIDIA GeForce GTX 680 Review: Retaking The Performance Crown
by Ryan Smith on March 22, 2012 9:00 AM ESTCompute: What You Leave Behind?
As always our final set of benchmarks is a look at compute performance. As we mentioned in our discussion on the Kepler architecture, GK104’s improvements seem to be compute neutral at best, and harmful to compute performance at worst. NVIDIA has made it clear that they are focusing first and foremost on gaming performance with GTX 680, and in the process are deemphasizing compute performance. Why? Let’s take a look.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. Note that this is a DX11 DirectCompute benchmark.

Remember when NVIDIA used to sweep AMD in Civ V Compute? Times have certainly changed. AMD’s shift to GCN has rocketed them to the top of our Civ V Compute benchmark, meanwhile the reality is that in what’s probably the most realistic DirectCompute benchmark we have has the GTX 680 losing to the GTX 580, never mind the 7970. It’s not by much, mind you, but in this case the GTX 680 for all of its functional units and its core clock advantage doesn’t have the compute performance to stand toe-to-toe with the GTX 580.
At first glance our initial assumptions would appear to be right: Kepler’s scheduler changes have weakened its compute performance relative to Fermi.
Our next benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. We’re now using a development build from the version 2.0 branch, and we’ve moved on to a more complex scene that hopefully will provide a greater challenge to our GPUs.

CivV was bad; SmallLuxGPU is worse. At this point the GTX 680 can’t even compete with the GTX 570, let alone anything Radeon. In fact the GTX 680 has more in common with the GTX 560 Ti than it does anything else.
On that note, since we weren’t going to significantly change our benchmark suite for the GTX 680 launch, NVIDIA had a solid hunch that we were going to use SmallLuxGPU in our tests, and spoke specifically of it. Apparently NVIDIA has put absolutely no time into optimizing their now all-important Kepler compiler for SmallLuxGPU, choosing to focus on games instead. While that doesn’t make it clear how much of GTX 680’s performance is due to the compiler versus a general loss in compute performance, it does offer at least a slim hope that NVIDIA can improve their compute performance.
For our next benchmark we’re looking at AESEncryptDecrypt, an OpenCL AES encryption routine that AES encrypts/decrypts an 8K x 8K pixel square image file. The results of this benchmark are the average time to encrypt the image over a number of iterations of the AES cypher.

Starting with our AES encryption benchmark NVIDIA begins a recovery. GTX 680 is still technically slower than GTX 580, but only marginally so. If nothing else it maintains NVIDIA’s general lead in this benchmark, and is the first sign that GTX 680’s compute performance isn’t all bad.
For our fourth compute benchmark we wanted to reach out and grab something for CUDA, given the popularity of NVIDIA’s proprietary API. Unfortunately we were largely met with failure, for similar reasons as we were when the Radeon HD 7970 launched. Just as many OpenCL programs were hand optimized and didn’t know what to do with the Southern Islands architecture, many CUDA applications didn’t know what to do with GK104 and its Compute Capability 3.0 feature set.
To be clear, NVIDIA’s “core” CUDA functionality remains intact; PhysX, video transcoding, etc all work. But 3rd party applications are a much bigger issue. Among the CUDA programs that failed were NVIDIA’s own Design Garage (a GTX 480 showcase package), AccelerEyes’ GBENCH MatLab benchmark, and the latest Folding@Home client. Since our goal here is to stick to consumer/prosumer applications in reflection of the fact that the GTX 680 is a consumer card, we did somewhat limit ourselves by ruling out a number of professional CUDA applications, but there’s no telling that compatibility there would fare any better.
We ultimately started looking at Distributed Computing applications and settled on PrimeGrid, whose CUDA accelerated GENEFER client worked with GTX 680. Interestingly enough it primarily uses double precision math – whether this is a good thing or not though is up to the reader given the GTX 680’s anemic double precision performance.
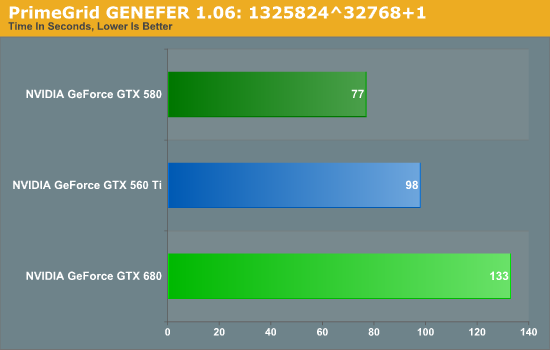
Because it’s based around double precision math the GTX 680 does rather poorly here, but the surprising bit is that it did so to a larger degree than we’d expect. The GTX 680’s FP64 performance is 1/24th its FP32 performance, compared to 1/8th on GTX 580 and 1/12th on GTX 560 Ti. Still, our expectation would be that performance would at least hold constant relative to the GTX 560 Ti, given that the GTX 680 has more than double the compute performance to offset the larger FP64 gap.
Instead we found that the GTX 680 takes 35% longer, when on paper it should be 20% faster than the GTX 560 Ti (largely due to the difference in the core clock). This makes for yet another test where the GTX 680 can’t keep up with the GTX 500 series, be it due to the change in the scheduler, or perhaps the greater pressure on the still-64KB L1 cache. Regardless of the reason, it is becoming increasingly evident that NVIDIA has sacrificed compute performance to reach their efficiency targets for GK104, which is an interesting shift from a company that was so gung-ho about compute performance, and a slightly concerning sign that NVIDIA may have lost faith in the GPU Computing market for consumer applications.
Finally, our last benchmark is once again looking at compute shader performance, this time through the Fluid simulation sample in the DirectX SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.
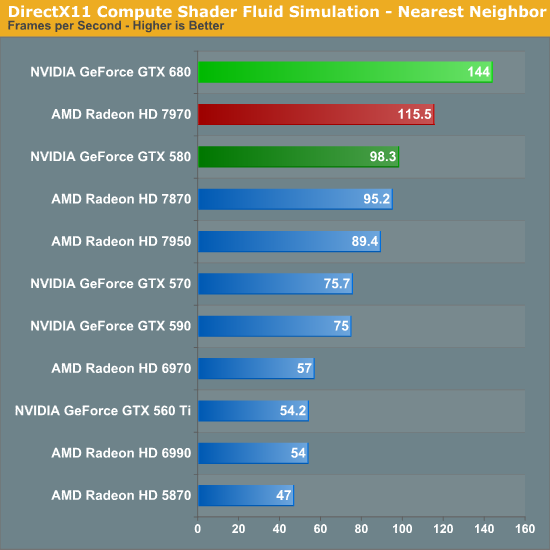
Redemption at last? In our final compute benchmark the GTX 680 finally shows that it can still succeed in some compute scenarios, taking a rather impressive lead over both the 7970 and the GTX 580. At this point it’s not particularly clear why the GTX 680 does so well here and only here, but the fact that this is a compute shader program as opposed to an OpenCL program may have something to do with it. NVIDIA needs solid compute shader performance for the games that use it; OpenCL and even CUDA performance however can take a backseat.








404 Comments
View All Comments
Slayer68 - Saturday, March 24, 2012 - link
Being able to run 3 screens off of one card is new for Nvidia. Barely even mentioned it in your review. It would be nice to see Nvidia surround / Eyefinity compared on these new cards. Especially interested in scaling at 5760 x 1080 between a 680 and 7970.....ati666 - Saturday, March 24, 2012 - link
does the gtx680 still have the same anisotropic filtering pattern like the gtx470/480/570/580 (octagonal pattern) or is it like AMDs HD7970 all angle-independent anisotropic filtering (circular pattern)?Ryan Smith - Saturday, March 24, 2012 - link
It's not something we were planning on publishing, but it is something we checked. It's still the same octagon pattern as Fermi. It would be nice if NVIDIA did have angle-independent AF, but to be honest the difference between that and what NVIDIA does has been so minor that it's not something we've ever been able to create a noticeable issue with in the real world.Now Intel's AF on the other hand...
ati666 - Saturday, March 24, 2012 - link
thank for the reply, now i can finally make a decision to buy hd7970 or gtx680..CeriseCogburn - Saturday, March 24, 2012 - link
Yes I thank him too for finally coming clean and noting the angle independent amd algorithm he's been fanboy over for a long time has absolutely no real world gaming advantage whatsoever.It's a big fat zero of nothing but FUD for fanboys.
It would be nice if notional advantages actually showed up in games, and when they don't or for the life of the reviewer cannot be detected in games, that be clearly stated and the insane "advantage" declared be called what it really is, a useless talking point of deception that fools purchasers instead of enlightening them.
The biased emphasis with zero advantage is as unscientific as it gets. Worse yet, within the same area, the "perfectly round algorithm" yielded in game transition lines with the amd cards, denied by the reviewer for what, a year ? Then a race game finally convinced him, and in this 7000 series release we find another issue the "perfectly round algorithm" apparently was attached to flaw with, a "poor transition resolution" - rather crudely large instead of fine like Nvidia's which casued excessive amd shimmering in game, and we are treated to that information only now after the 7000 series "solved" the issue and brought it near or up to the GTX long time standard.
So this whole "perfectly round algorithm" has been nothing but fanboy lies for amd all along, while ignoring at least 2 large IQ issues when it was "put to use" in game. (transition shading and shimmering)
I'm certain an explanation could be given that there are other factors with differing descriptive explanation, like the fineness of textural changes as one goes toward center of the image not directly affecting roundness one way or another, used as an excuse, perhaps the self deceptive justification that allowed such misbehavior to go on for so long.
_vor_ - Saturday, March 24, 2012 - link
Will you seriously STFU already? It's hard to read this discussion with your blatant and belligerent jackassery all over it.You love NVIDIA. Great. Now STFU and stop posting.
CeriseCogburn - Saturday, March 24, 2012 - link
Great attack, did I get anything wrong at all ? I guess not.silverblue - Monday, March 26, 2012 - link
Could you provide a link to an article based on this subject, please? Not an attack; just curious.CeriseCogburn - Tuesday, March 27, 2012 - link
http://www.anandtech.com/show/5261/amd-radeon-hd-7...http://forums.anandtech.com/showpost.php?p=3152067...
" So what then is going on that made Civ V so much faster for NVIDIA? Admittedly I had to press NVIDIA for this - performance practically doubled on high-end GPUs, which is unheard of. Until they told me what exactly they did, I wasn't convinced it was real or if they had come up with a really sweet cheat. It definitely wasn't a cheat.
If you recall from our articles, I keep pointing to how we seem to be CPU limited at the time. "
(YES, SO THAT'S WHAT WE GOT, THEY'RE CHEATING IT'S FAKE WE'RE CPU LIMITED- ALL WRONG ALL LIES)
Since AMD’s latest changes are focused on reducing shimmering in motion we’ve put together a short video of the 3D Center Filter Tester running the tunnel test with the 7970, the 6970, and GTX 580. The tunnel test makes the differences between the 7970 and 6970 readily apparent, and at this point both the 7970 and GTX 580 have similarly low levels of shimmering.
with both implementing DX9 SSAA with the previous generation of GPUs, and AMD catching up to NVIDIA by implementing Enhanced Quality AA (their version of NVIDIA’s CSAA) with Cayman. Between Fermi and Cayman the only stark differences are that AMD offers their global faux-AA MLAA filter, while NVIDIA has support for true transparency and super sample anti-aliasing on DX10+ games.
(AMD FINALLY CATCHES UP IN EQAA PART, NVIDIA TRUE STANS AND SUPER SAMPLE HIGH Q STUFF, AMD CHEAT AND BLUR AND BLUR TEXT)
Thus I had expected AMD to close the gap from their end with Southern Islands by implementing DX10+ versions of Adaptive AA and SSAA, but this has not come to pass.
( AS I INTERPRETED AMD IS WAY BEHIND STILL A GAP TO CLOSE ! )
AMD has not implemented any new AA modes compared to Cayman, and as a result AAA and SSAA continue to only available in DX9 titles.
Finally, while AMD may be taking a break when it comes to anti-aliasing they’re still hard at work on tessellation
( BECAUSE THEY'RE BEHIND IN TESSELLATION TOO.)
Don't forget amd has a tessellation cheat in their 7000 series driver, so 3dmark 11 is cheated on as is unigine heaven, while Nvidia does no such thing.
---
I do have more like the race car game admission, but I think that's enough helping you doing homework .
CeriseCogburn - Tuesday, March 27, 2012 - link
So here's more mr curious .." “There’s nowhere left to go for quality beyond angle-independent filtering at the moment.”
With the launch of the 5800 series last year, I had high praise for AMD’s anisotropic filtering. AMD brought truly angle-independent filtering to gaming (and are still the only game in town), putting an end to angle-dependent deficiencies and especially AMD’s poor AF on the 4800 series. At both the 5800 series launch and the GTX 480 launch, I’ve said that I’ve been unable to find a meaningful difference or deficiency in AMD’s filtering quality, and NVIDIA was only deficienct by being not quite angle-independent. I have held – and continued to hold until last week – the opinion that there’s no practical difference between the two.
It turns out I was wrong. Whoops.
The same week as when I went down to Los Angeles for AMD’s 6800 series press event, a reader sent me a link to a couple of forum topics discussing AF quality. While I still think most of the differences are superficial, there was one shot comparing AMD and NVIDIA that caught my attention: Trackmania."
" The shot clearly shows a transition between mipmaps on the road, something filtering is supposed to resolve. In this case it’s not a superficial difference; it’s very noticeable and very annoying.
AMD appears to agree with everyone else. As it turns out their texture mapping units on the 5000 series really do have an issue with texture filtering, specifically when it comes to “noisy” textures with complex regular patterns. AMD’s texture filtering algorithm was stumbling here and not properly blending the transitions between the mipmaps of these textures, resulting in the kind of visible transitions that we saw in the above Trackmania screenshot. "
http://www.anandtech.com/show/3987/amds-radeon-687...
WE GET THIS AFTER 6000 SERIES AMD IS RELEASED, AND DENIAL UNTIL, NOW WE GET THE SAME THING ONCE 7000 SERIES IS RELEASED, AND COMPLETE DENIAL BEFORE THAT...
HERE'S THE 600 SERIES COVERUP THAT COVERS UP 5000 SERIES AFTER ADMITTING THE PROBLEM A WHOLE GENERATION LATE
" So for the 6800 series, AMD has refined their texture filtering algorithm to better handle this case. Highly regular textures are now filtered properly so that there’s no longer a visible transition between them. As was the case when AMD added angle-independent filtering we can’t test the performance impact of this since we don’t have the ability to enable/disable this new filtering algorithm, but it should be free or close to it. In any case it doesn’t compromise AMD’s existing filtering features, and goes hand-in-hand with their existing angle-independent filtering."
NOW DON'T FORGET RYAN HAS JUST ADMITTED AMD ANGLE INDEPENDENT ALGORITHM IS WORTH NOTHING IN REAL GAME- ABSOLUTELY NOTHING.