The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
MySQL OLAP Analyzed
Since threads waiting for mutex (semaphores) to complete were killing scaling on the old MySQL/Innodb, we wrote a bash script to monitor the right lines in the complex and long listing of "SHOW ENGINE INNODB STATUS \G" command. The show status commands are rather hard to interpret as they simply reveal the current status of the counters and show few ratios, so we sampled the output of the status command every second to measure the amount of spin waits per second. This gave us some very interesting data points.
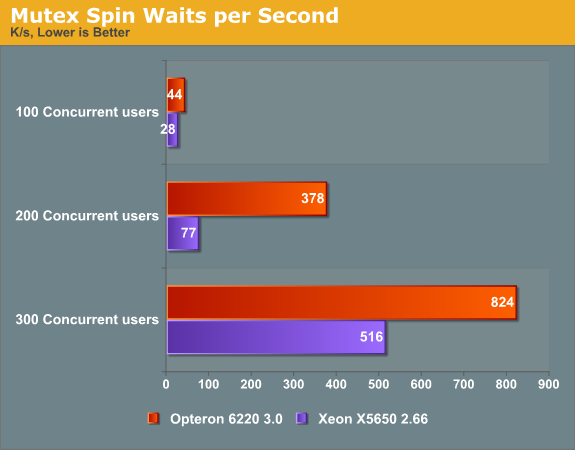
A few thousands of spin waits isn't anything to worry about, but a spin wait inherently wastes a small amount CPU cycles, and a few hundreds of thousands of them will waste a lot of CPU cycles without doing any useful computational work. At 200 concurrent users, five times (!) more spin waits are happening on the Opteron server than on the Xeon server. Since the Opteron has a slightly higher clockspeed than the Xeon (3GHz vs. 2.66GHz), chances are high that the Opteron's micro-architecture is a lot less efficient in handling the mutex. We will try to profile this and report back in our next article. But this already explains a lot: as the core count goes up, more threads are launched to take advantage of this, but more threads means that locking contention plays an increasingly important role.
A CPU that handles mutex and locking in general slowly can get an even heavier performance penalty in MySQL with rapidly increasing amounts of context switches. If the spin wait spins too many times (too many "rounds"), it is put to sleep by the OS and put in a wait array. The context switch associated with this operation allows a new thread to run on the CPU but costs tens of thousands CPU cycles. So high amount of spin wait rounds and context switches waste a lot of CPU cycles and power. The end result is that spin locks and high context switch rates are having a devastating effect on the Opteron's power consumption. We integrated the Racktivity energy monitor into our vApus stress testing client. The Opteron is the brown line, the Xeon the blue line.
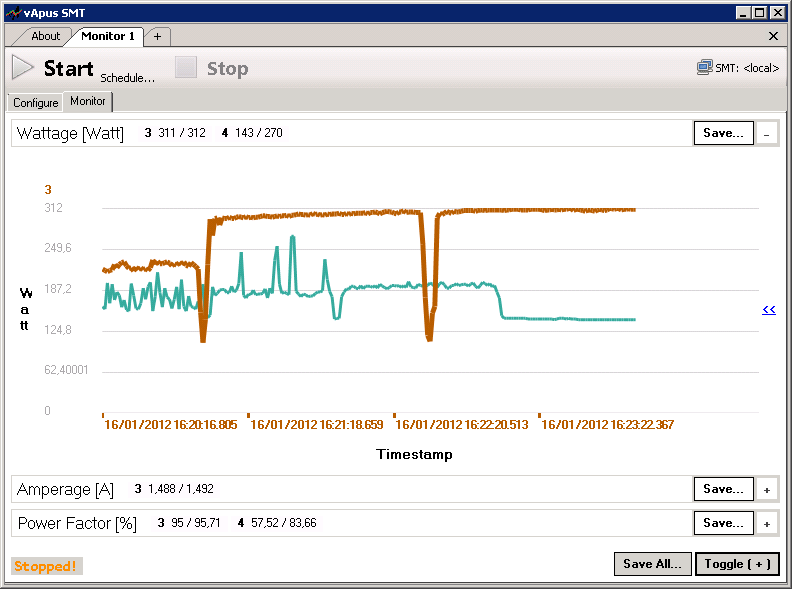
The dips are the periods between two concurrencies. The first bulge is 100 concurrent users, the second 200, and the third 300. As you can see the Opteron is running constantly at full throttle while the Xeon only spikes from time to time. The huge amount of spin locks is keeping the Opteron cores working hard, while the Xeon cores can take lots of breaks. The Opteron is running almost constantly at 311W (at 200 and 300 concurrent users) while the the Xeon runs at 190W with spikes up to 270W. The delta between the surfaces below the lines is the amount of energy consumed, which is huge.
Another way to make the issue clear is to look at the spin rounds per wait. This value shows the number of spin lock rounds per OS wait for a mutex.
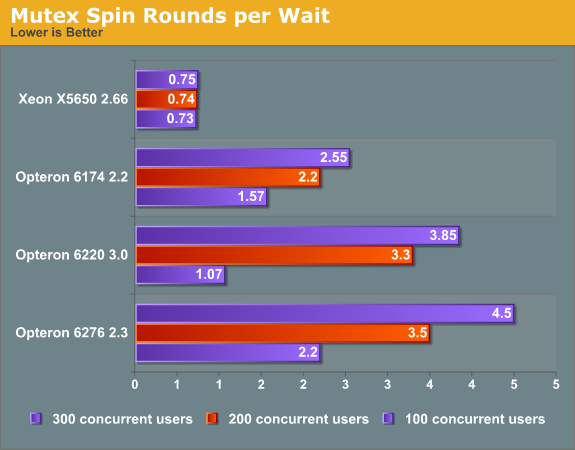
Notice that as the core count goes up and the single threaded performance goes down, the amount of spin lock grounds goes up. There is more to it than just "single threaded" performance as we can assume that a Opteron 6174 core at 2.2GHz is not faster than a Opteron 6220 core at 3GHz. In fact at low thread counts, even the Opteron 6276 edged out the Opteron 6174. So as long as the impact of locking contention is not too high, the Opteron 6200 does fine. Once locking contention is determining the performance, it is clear that even the old Magny-Cours architecture handles mutexes a lot better.
The Opteron is clearly not the only one to blame as apparantely MS SQL server has less internal contention problems than the MySQL/Innodb combination. We might also be able to tweak Innodb to lower the impact by changing the Innodb_sync_spin_loops variable and reducing the amount of threads running. However, handling semaphores quickly is important in many if not most server workloads. As long as we don't find a way around it, the Opteron 6200 is not an option for any heavily used MySQL OLAP server.








46 Comments
View All Comments
Scali - Friday, February 10, 2012 - link
No, because if you read the ENTIRE benchmark configuration page, you'd see that all the AMD systems had 2 CPUs as well.Scali - Saturday, February 11, 2012 - link
Oh, and while we're at it... the Intel system had only 48 GB of 1333 memory, where the AMDs had 64 GB of 1600 memory.(Yes, Bulldozer is THAT bad)
PixyMisa - Saturday, February 11, 2012 - link
Or rather, MySQL scales that poorly.What we can tell from this article is that if you want to run a single instance of MySQL as fast as possible and don't want to get involved with subtle performance tuning options, the Opteron 6276 is not the way to go.
For other workloads, the result can be very different.
JohanAnandtech - Saturday, February 11, 2012 - link
Feel free to send me a suggestion on how to setup another workload. We know how to tune MySQL. So far none of these settings helped. The issue discussed (spinlocks) can not be easily solved.Scali - Saturday, February 11, 2012 - link
I'm not sure if you bothered to read the entire article, because MySQL was not the only database that was tested.There were also various tests with MS SQL, and again, Interlagos failed to impress compared to both Magny Cours-based Opterons and the Xeon system.
JohanAnandtech - Saturday, February 11, 2012 - link
The clockspeed of the RAM has a small impact here. 64 vs 48 GB does not matter.Scali - Saturday, February 11, 2012 - link
Not saying it does... Just pointing out that the AMD system had more impressive specs on paper, yet failed to deliver the performance.JohanAnandtech - Saturday, February 11, 2012 - link
Again, it is not CMT that makes AMD's transistor count explode but the combination of 2x L3 caches and 4x 2M L2-caches. You can argue that AMD made poor choices concerning caches, but again it is not CMT that made the transistor count grow.I am not arguing that AMD's performance/billion transistors is great.
Scali - Saturday, February 11, 2012 - link
I think you are looking at it from the wrong direction.You are trying to compare SMT and CMT, but contrary to what AMD wants to make everyone believe, they are not very similar technologies.
You see, SMT enables two threads to run on one physical core, without adding any kind of execution units, cache or anything. It is little more than some extra logic so that the OoOE buffers can handle two thread contexts at the same time, rather than one.
So the thing with SMT is that it REDUCES the transistorcount required for running two threads. By nearly 100%.
CMT on the other hand does not reduce the transistorcount nearly as much. So if you are merely looking at an 'exposion of transistor count', you are missing the point of what SMT really does.
Other than that, your argument is still flawed. Even an 8-thread Bulldozer has a higher transistor count than the 12-thread Xeon here. It's not just cache. CMT just doesn't pack as many threads per transistor as SMT does... and to make matters worse, CMT also has a negative impact on single-threaded performance (which again, if you are looking at it from the wrong direction, may look like better scaling in threadcount... but effectively, both with low and high threadcounts, the Xeon is the better option... and this is just a midrange Xeon compared to a high-end Interlagos. The Xeon can scale to higher clockspeeds, improving both single-threaded and multithreaded performance for the same transistorcount).
So what your article says is basically this:
CMT, which is nearly the same as having full cores, especially in integer-only tasks such as databases, since you have two actual integer cores, has nearly the same scaling in threadcount as conventional multicore CPUs.
Which has a very high 'duh'-factor, since it pretty much *is* conventional multicore.
It does not reduce transistorcount, nor does it improve performance, so what's the point?
JohanAnandtech - Friday, February 10, 2012 - link
Semantics :-). I can call it a core with CMT, or a module with 2 cores. Both are valid.