The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
MySQL OLAP Analyzed
Since threads waiting for mutex (semaphores) to complete were killing scaling on the old MySQL/Innodb, we wrote a bash script to monitor the right lines in the complex and long listing of "SHOW ENGINE INNODB STATUS \G" command. The show status commands are rather hard to interpret as they simply reveal the current status of the counters and show few ratios, so we sampled the output of the status command every second to measure the amount of spin waits per second. This gave us some very interesting data points.
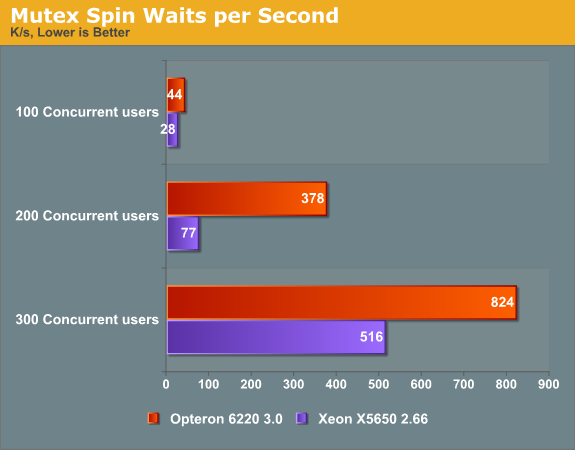
A few thousands of spin waits isn't anything to worry about, but a spin wait inherently wastes a small amount CPU cycles, and a few hundreds of thousands of them will waste a lot of CPU cycles without doing any useful computational work. At 200 concurrent users, five times (!) more spin waits are happening on the Opteron server than on the Xeon server. Since the Opteron has a slightly higher clockspeed than the Xeon (3GHz vs. 2.66GHz), chances are high that the Opteron's micro-architecture is a lot less efficient in handling the mutex. We will try to profile this and report back in our next article. But this already explains a lot: as the core count goes up, more threads are launched to take advantage of this, but more threads means that locking contention plays an increasingly important role.
A CPU that handles mutex and locking in general slowly can get an even heavier performance penalty in MySQL with rapidly increasing amounts of context switches. If the spin wait spins too many times (too many "rounds"), it is put to sleep by the OS and put in a wait array. The context switch associated with this operation allows a new thread to run on the CPU but costs tens of thousands CPU cycles. So high amount of spin wait rounds and context switches waste a lot of CPU cycles and power. The end result is that spin locks and high context switch rates are having a devastating effect on the Opteron's power consumption. We integrated the Racktivity energy monitor into our vApus stress testing client. The Opteron is the brown line, the Xeon the blue line.
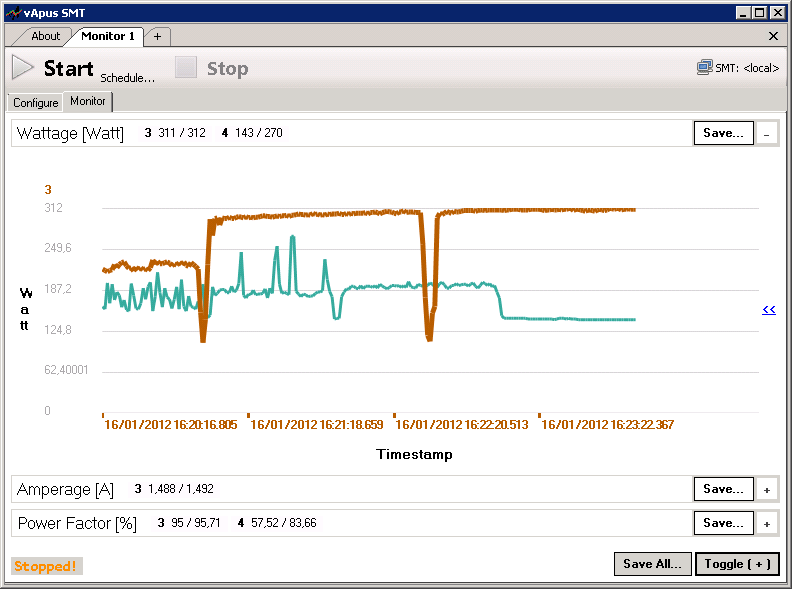
The dips are the periods between two concurrencies. The first bulge is 100 concurrent users, the second 200, and the third 300. As you can see the Opteron is running constantly at full throttle while the Xeon only spikes from time to time. The huge amount of spin locks is keeping the Opteron cores working hard, while the Xeon cores can take lots of breaks. The Opteron is running almost constantly at 311W (at 200 and 300 concurrent users) while the the Xeon runs at 190W with spikes up to 270W. The delta between the surfaces below the lines is the amount of energy consumed, which is huge.
Another way to make the issue clear is to look at the spin rounds per wait. This value shows the number of spin lock rounds per OS wait for a mutex.
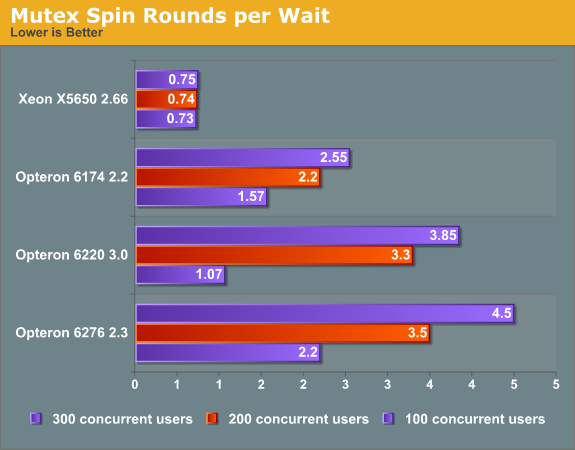
Notice that as the core count goes up and the single threaded performance goes down, the amount of spin lock grounds goes up. There is more to it than just "single threaded" performance as we can assume that a Opteron 6174 core at 2.2GHz is not faster than a Opteron 6220 core at 3GHz. In fact at low thread counts, even the Opteron 6276 edged out the Opteron 6174. So as long as the impact of locking contention is not too high, the Opteron 6200 does fine. Once locking contention is determining the performance, it is clear that even the old Magny-Cours architecture handles mutexes a lot better.
The Opteron is clearly not the only one to blame as apparantely MS SQL server has less internal contention problems than the MySQL/Innodb combination. We might also be able to tweak Innodb to lower the impact by changing the Innodb_sync_spin_loops variable and reducing the amount of threads running. However, handling semaphores quickly is important in many if not most server workloads. As long as we don't find a way around it, the Opteron 6200 is not an option for any heavily used MySQL OLAP server.








46 Comments
View All Comments
sonofgodfrey - Thursday, February 9, 2012 - link
Have you explicitly tested one socket vs. two sockets? We've found an immense increase in contention once a cache-line has to be shared between sockets on some systems.JohanAnandtech - Friday, February 10, 2012 - link
That is one suggestion I will try out next week. Thanks!Klimax - Thursday, February 9, 2012 - link
Hello.Nice tests.
However I would like to see MySQL tested on Windows Server 2008 R2
Would be interesting comparsion.
(Especially due to http://channel9.msdn.com/shows/Going+Deep/Arun-Kis... )
Klimax - Thursday, February 9, 2012 - link
Title of post is wrong... (I have deleted second thing and forgot to fix title)Scali - Thursday, February 9, 2012 - link
Unless I'm mistaken, the Xeon 5650 is a 1.17B transistor chip, where the Interlagos 6276 is a 2.4B transistor chip.In that light, doesn't that make Intel's SMT implementation a lot better than CMT?
I mean, yes CMT may give more of a performance boost when you increase the threadcount. But considering the fact that AMD spends more than twice the number of transistors on the chip... well, that's pretty obvious.
AMD might as well just have used conventional cores.
The true strength of SMT is not so much that it improves performance in multithreaded scenarios, but that it does so at virtually no extra cost in terms of transistors (and with little or no impact on the single-threaded performance either).
JohanAnandtech - Friday, February 10, 2012 - link
Interlagos is 1.2 billion chip (maybe 1.3 but anyway). Most of those transistors are spend on the L3 cache: about 0.5 billion. Only 213 million transistors are in a module and each module contains a 2 MB L2-cache, probably good for 120 million transistors. That leaves 90 million transistors to the core, and it has been stated that the second cluster added 12%. So that second cluster costs about 12 million transistors, or 48 million on the total 4 module die. That is less than 5% of the total transistor count but you get a 30-90% performance boost!So for AMD, this was clearly a great choice.
SMT is perfect for Intel, as the Intel architecture puts all instructions in one big ROB.
For very low IPC serverworkloads, I think the CMT approach gives better results. Unfortunately AMD lowered some of the CMT benefits by keeping the datacache so small and the low associativity of the Icache.
Scali - Friday, February 10, 2012 - link
Uhhh, I think you're wrong here... the 4-module Bulldozer is a 1.2B chip (Zambezi). But you tested the 8-module Interlagos (16 threads), which is TWO Zambezi dies in one package.Hence 2*1.2 = 2.4B transistors.
JohanAnandtech - Friday, February 10, 2012 - link
Ok, it is two chips of 1.2 billion. That doesn't change anything about our analyses of CMT.Scali - Friday, February 10, 2012 - link
Not in the article, because you did not factor in transistor count (which is the flaw I tried to point out in the first place... comparing two chips, where once is twice the transistor count of the other, is quite the apples-to-oranges comparison. One would expect a chip with twice the transistorcount to be considerably better in multithreading scenarios, not 'catching up' to the smaller chip).But in your above post, I think it changes everything about your analysis. All your figures have to be done times two.
Which makes it a very poor comparison, not only to Intel, but also to AMD's own previous line of CPUs.
The 6174 Magny Cours is actually beating Interlagos, with 'only' 12 threads, no kind of CMT/SMT, and 'only' 1.8B transistors.
How does that make CMT look like a great choice for AMD?
slycer.tech - Friday, February 10, 2012 - link
What i read on benchmark configuration page, Anand used 2x Intel Xeon X5650. So 2x 1.17B = 2.34B. I think it is comparable to AMD CPU used in this test. Am I right?