The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
MySQL OLAP Analyzed
Since threads waiting for mutex (semaphores) to complete were killing scaling on the old MySQL/Innodb, we wrote a bash script to monitor the right lines in the complex and long listing of "SHOW ENGINE INNODB STATUS \G" command. The show status commands are rather hard to interpret as they simply reveal the current status of the counters and show few ratios, so we sampled the output of the status command every second to measure the amount of spin waits per second. This gave us some very interesting data points.
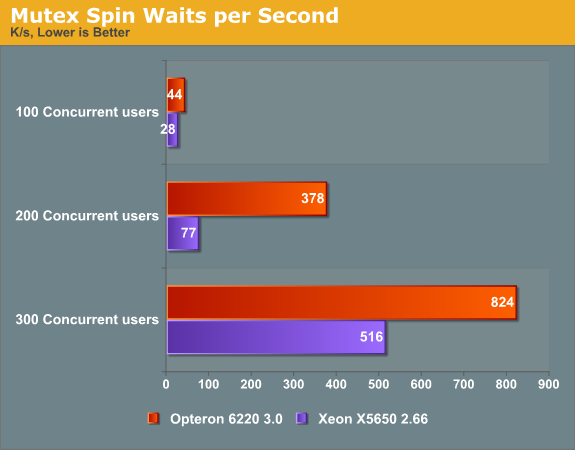
A few thousands of spin waits isn't anything to worry about, but a spin wait inherently wastes a small amount CPU cycles, and a few hundreds of thousands of them will waste a lot of CPU cycles without doing any useful computational work. At 200 concurrent users, five times (!) more spin waits are happening on the Opteron server than on the Xeon server. Since the Opteron has a slightly higher clockspeed than the Xeon (3GHz vs. 2.66GHz), chances are high that the Opteron's micro-architecture is a lot less efficient in handling the mutex. We will try to profile this and report back in our next article. But this already explains a lot: as the core count goes up, more threads are launched to take advantage of this, but more threads means that locking contention plays an increasingly important role.
A CPU that handles mutex and locking in general slowly can get an even heavier performance penalty in MySQL with rapidly increasing amounts of context switches. If the spin wait spins too many times (too many "rounds"), it is put to sleep by the OS and put in a wait array. The context switch associated with this operation allows a new thread to run on the CPU but costs tens of thousands CPU cycles. So high amount of spin wait rounds and context switches waste a lot of CPU cycles and power. The end result is that spin locks and high context switch rates are having a devastating effect on the Opteron's power consumption. We integrated the Racktivity energy monitor into our vApus stress testing client. The Opteron is the brown line, the Xeon the blue line.
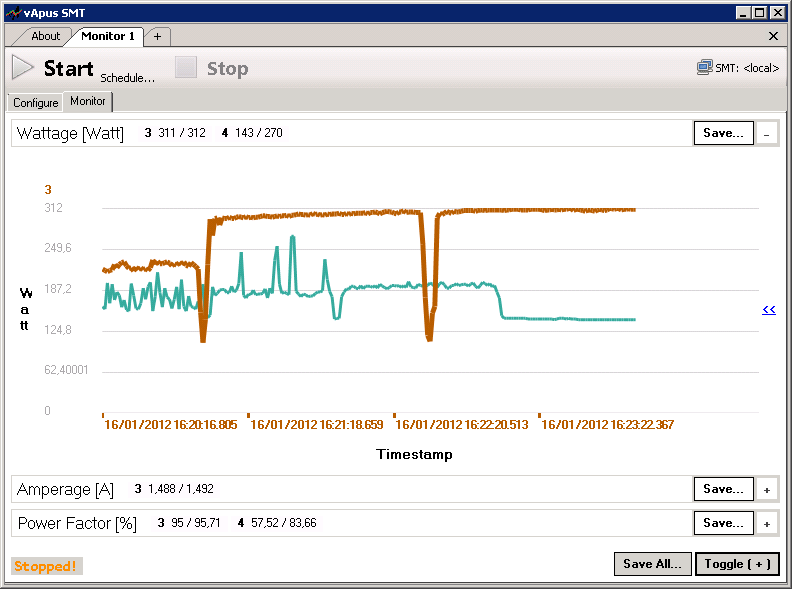
The dips are the periods between two concurrencies. The first bulge is 100 concurrent users, the second 200, and the third 300. As you can see the Opteron is running constantly at full throttle while the Xeon only spikes from time to time. The huge amount of spin locks is keeping the Opteron cores working hard, while the Xeon cores can take lots of breaks. The Opteron is running almost constantly at 311W (at 200 and 300 concurrent users) while the the Xeon runs at 190W with spikes up to 270W. The delta between the surfaces below the lines is the amount of energy consumed, which is huge.
Another way to make the issue clear is to look at the spin rounds per wait. This value shows the number of spin lock rounds per OS wait for a mutex.
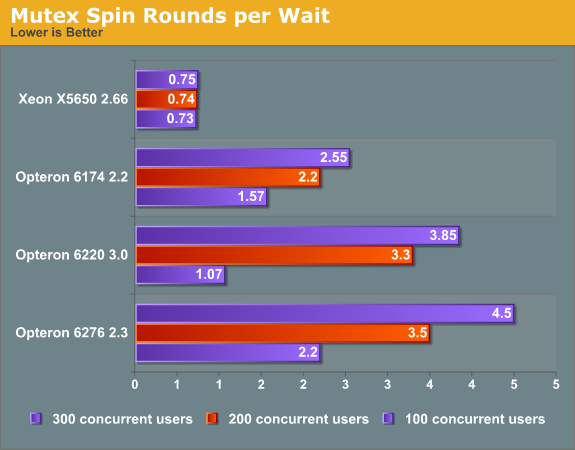
Notice that as the core count goes up and the single threaded performance goes down, the amount of spin lock grounds goes up. There is more to it than just "single threaded" performance as we can assume that a Opteron 6174 core at 2.2GHz is not faster than a Opteron 6220 core at 3GHz. In fact at low thread counts, even the Opteron 6276 edged out the Opteron 6174. So as long as the impact of locking contention is not too high, the Opteron 6200 does fine. Once locking contention is determining the performance, it is clear that even the old Magny-Cours architecture handles mutexes a lot better.
The Opteron is clearly not the only one to blame as apparantely MS SQL server has less internal contention problems than the MySQL/Innodb combination. We might also be able to tweak Innodb to lower the impact by changing the Innodb_sync_spin_loops variable and reducing the amount of threads running. However, handling semaphores quickly is important in many if not most server workloads. As long as we don't find a way around it, the Opteron 6200 is not an option for any heavily used MySQL OLAP server.








46 Comments
View All Comments
Jaguar36 - Thursday, February 9, 2012 - link
I too would love to see more HPC related benchmarks. Finite Element Analysis (FEA) or Computational Fluid Dynamic (CFD) programs scale very well with increased core count, and are something that is highly CPU dependent. I've found it very difficult to find good performance information for CPUs under this load.I'd be happy to help out developing some benchmark problems if need be.
dcollins - Thursday, February 9, 2012 - link
These would indeed be interesting benchmarks to see. These workloads are very floating point heavy so I imagine that the new Opterons will perform poorly. 16 modules won't matter when they only have 8 FPUs. Of course, I am speculating here.Going forward, these types of workloads should be moving toward GPUs rather than CPUs, but I understand the burden of legacy software.
silverblue - Friday, February 10, 2012 - link
They have 8 FPUs capable of 16x 128-bit or 8x 256-bit instructions per clock. On that level, it shouldn't be at a disadvantage.bnolsen - Sunday, February 12, 2012 - link
GPUs are pretty poor for general purpose HPC. If someone wants to fork out tons of $$$ to hack their problem onto a gpu (or they get lucky and somehow their problem fits a gpu well) that's fine but not really smart considering how short release cycles are, etc.I have access to a quad socket magny cours built mid last year. In december I put together a sandy-e 3930k portable demo system. Needless to say the 3930k had at least 10% more throughput on heavy processing tasks (enabling all intel sse dropped in another 15%). It also handily beat our dual xeon nehalem development system as well. With mixed IO and cpu heavy loads the advantage dropped but was still there.
I'd love to be able to test these new amds just to see but its been much easier telling customers to stick with intel, especially with this new amd cpu.
MySchizoBuddy - Friday, March 9, 2012 - link
"GPUs are pretty poor for general purpose HPC."tell that to the #2, #4 and #5 most powerful supercomputers in the world. I'm sure no one told them.
hooflung - Thursday, February 9, 2012 - link
I think I'd rather see some benchmarks based around Java EE6 and an appropriate container such as Jboss AS 7. I'd also like to see some Java 7 application benchmarks ( server oriented ).I'd also like to see some custom Java benchmarks using Akka library so we can see some Software transactional memory benchmarks. Possibly a node.js benchmark as well to see if these new technologies can scale.
What I've seen here is that the enterprise circa 2006 has a love hate relationship with AMD. I'd also like to see some benchmarks of the Intel vs AMD vs SPARC T4 in both virtualized and non virtualized J2EE environments. But this article does have some really interesting data.
jibberegg - Thursday, February 9, 2012 - link
Thanks for the great and informative article! Minor typo for you..."Using a PDU for accurate power measurements might same pretty insane"
should be
"Using a PDU for accurate power measurements might seem pretty insane"
phoenix_rizzen - Thursday, February 9, 2012 - link
MySQL has to be the absolute worst possible choice for testing multi-core CPUs (as evidenced in this review). It just doesn't scale beyond 4-8 cores, depending on CPU choice and MySQL version.A much better choice for "alternative SQL database" would be PostgreSQL. That at least scales to 32 cores (possibly more, but I've never seen a benchmark beyond 32). Not to mention it's a much better RDBMS than MySQL.
MySQL really is only a toy. The fact that many large websites run on top of MySQL doesn't change that fact.
PixyMisa - Friday, February 10, 2012 - link
This is a very good point. While it can be done, it's very fiddly to get MySQL to scale to many CPUs, much simpler to just shard the database and run multiple instances of MySQL. (And replication is single-threaded anyway, so if you manage to get one MySQL instance running with very high inserts/updates, you'll find replication can't keep up.)Same goes for MongoDB and, of course, Redis, which is single-threaded.
We have ten large Opteron servers running CentOS 6, five 32-core and five 48-core, and all our applications are sharded and virtualised at a point where the individual nodes still have room to scale. Since our applications are too large to run un-sharded anyway, and the e7 Xeons cost an absolute fortune, the Opteron was the way to go.
The only back-end software we've found that scales smoothly to large numbers of CPUs is written in Erlang - RabbitMQ, CouchDB, and Riak. We love RabbitMQ and use it everywhere; unfortunately, while CouchDB and Riak scale very nicely, they start out pretty darn slow.
We actually ran a couple of 40-core e7 Xeon systems for a few months, and they had some pretty serious performance problems for certain workloads too - where the same workload worked fine on either a dual X5670 or a quad Opteron. Working out why things don't scale is often more work than just fixing them so that they do; sometimes the only practical thing to do is know what platform works for what workload, and use the right hardware for the task at hand.
Having said all that, the MySQL results are still disappointing.
JohanAnandtech - Friday, February 10, 2012 - link
"It just doesn't scale beyond 4-8 cores, depending on CPU choice and MySQL version."You missed something: it does scale beyond 12 Xeon cores, and I estimate that scaling won't be bad until you go beyond 24 cores. I don't see why the current implementation of MySQL should be called a toy.
PostgreSQL: interesting several readers have told me this too. I hope it is true, because last time we test PostgreSQL was worse than the current MySQL.