AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTAnd Many Compute Units Make A GPU
While the compute unit is the fundamental unit of computation, it is not a GPU on its own. As with SIMDs in Cayman it’s a configurable building block for making a larger GPU, with a GPU implementing a suitable number of CUs in multiples of 4. Like past GPUs this will be the primary way to scale the GPU to the desired die size, but of course this isn’t the only element of the design that scales.
With a suitable number of CUs in hand, it’s time to attach the rest of units that make up a GPU. As this is a high-level overview on the part of AMD they haven’t gone into great deal on what each unit does and how it does it, but as the first GCN product gets closer to launching the picture will take on a more complete form.
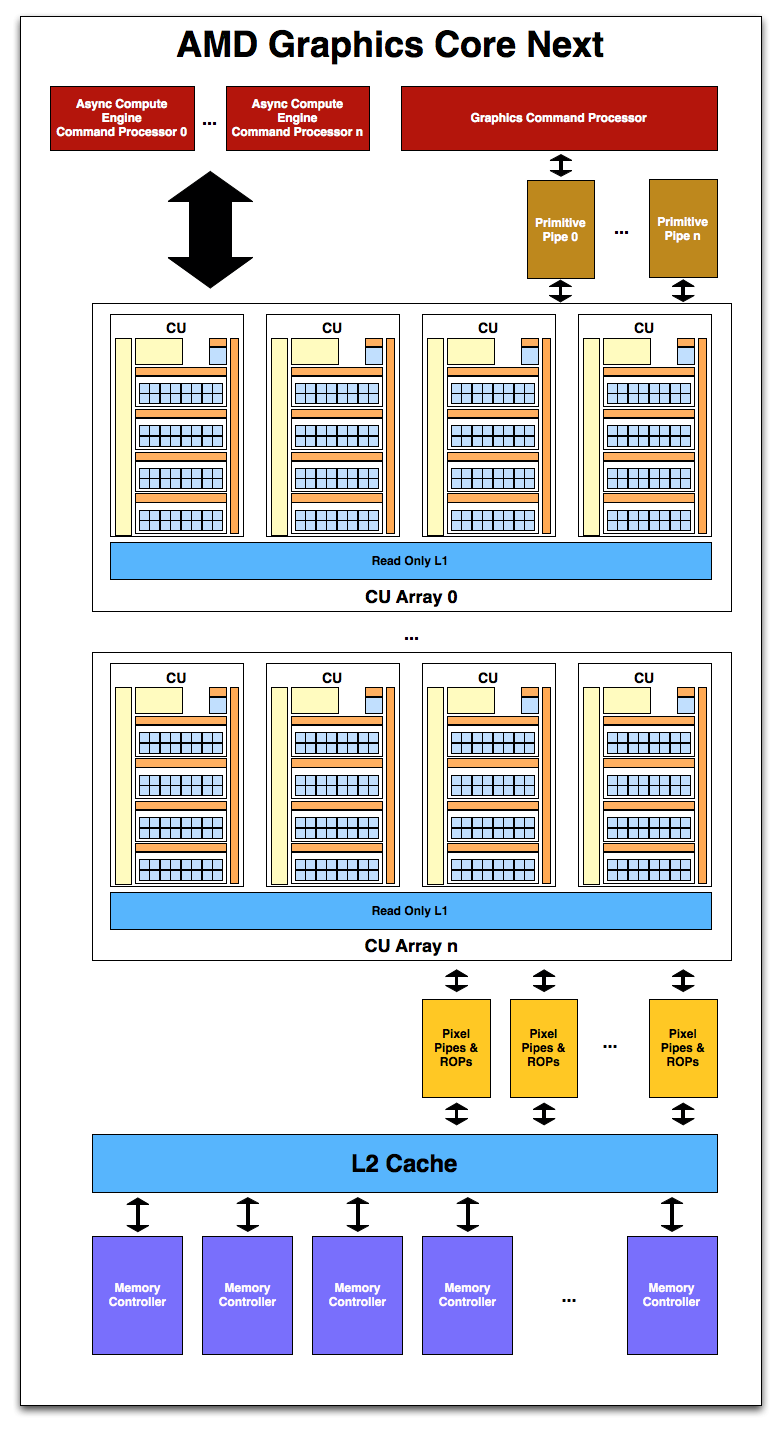
Starting with memory and cache, GCN will once more pair its L2 cache with its memory controllers. The architecture supports 64KB or 128KB of L2 cache per memory controller, and given that AMD’s memory controllers are typically 64bits each, this means a Cayman-like design would likely have 512KB of L2 cache. The L2 cache is write-back, and will be fully coherent so that all CUs will see the same data, saving expensive trips to VRAM for synchronization. CPU/GPU synchronization will also be handled at the L2 cache level, where it will be important to maintain coherency between the two in order to efficiently split up a task between the CPU and GPU. For APUs there is a dedicated high-speed bus between the two, while discrete GPUs will rely on PCIe’s coherency protocols to keep the CPU and dGPU in sync.
Meanwhile on the compute side, AMD’s new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing. As GCN is designed to concurrently work on several tasks, there can be multiple ACEs on a GPU, with the ACEs deciding on resource allocation, context switching, and task priority. AMD has not established an immediate relationship between ACEs and the number of tasks that can be worked on concurrently, so we’re not sure whether there’s a fixed 1:X relationship or whether it’s simply more efficient for the purposes of working on many tasks in parallel to have more ACEs.
One effect of having the ACEs is that GCN has a limited ability to execute tasks out of order. As we mentioned previously GCN is an in-order architecture, and the instruction stream on a wavefront cannot be reodered. However the ACEs can prioritize and reprioritize tasks, allowing tasks to be completed in a different order than they’re received. This allows GCN to free up the resources those tasks were using as early as possible rather than having the task consuming resources for an extended period of time in a nearly-finished state. This is not significantly different from how modern in-order CPUs (Atom, ARM A8, etc) handle multi-tasking.
On the other side of the coin we have the graphics hardware. As with Cayman a graphics command processor sits at the top of the stack and is responsible for farming out work to the various components of the graphics subsystem. Below that Cayman’s dual graphics engines have been replaced with multiple primitive pipelines, which will serve the same general purpose of geometry and fixed-function processing. Primative pipelines will be responsible for tessellation, geometry, and high-order surface processing among other things. Whereas Cayman was limited to 2 such units, GCN will be fully scalable, so AMD will be able to handle incredibly large amounts of geometry if necessary.
After a trip through the CUs, graphics work then hits the pixel pipelines, which are home to the ROPs. As it’s customary to have a number of ROPs, there will be a scalable number of pixel pipelines in GCN; we expect this will be closely coupled with the number of memory controllers to maintain the tight ROP/L2/Memory integration that’s so critical for high ROP performance.
Unfortunately, those of you expecting any additional graphics information will have to sit tight for the time being. As was the case with NVIDIA’s early reveal of Fermi in 2009, AFDS is a development show, and GCN’s early reveal is about the compute capabilities rather than the graphics capabilities. AMD needs to prime developers for GCN now, so that when GCN appears in an APU developers are ready for it. We’ll find out more about the capabilities of the ROPs, the primitive pipelines, the texture mapping units, the display controllers and other dedicated hardware blocks farther down the line.
In the meantime AMD did throw out one graphics tidbit: partially resident textures (PRT). PRTs allow for only part of a texture to actually be loaded in memory, allowing developers to use large textures without taking the performance hit of loading the entire texture into memory if parts of it are going unused. John Carmack already does something very similar in software with his MegaTexture technology, which is used in the id Tech 4 and id Tech 5 engines. This is essentially a hardware implementation of that technology.








83 Comments
View All Comments
EJ257 - Saturday, June 18, 2011 - link
I can't believe it's been 6 years since the X360 and PS3 release. It seems like this latest generation of consoles stuck around a lot longer than previous versions did. Any speculations on what kind of hardware MS and Sony will throw into the next gen?DanNeely - Sunday, June 19, 2011 - link
They have. The big console makers, at the gave devs requests, were trying to make the current generation last a decade to allow more time to recover the work expended figuring out how to best program them. The motion capture cameras were supposed to be the thing that kept the platforms from getting too stale. I suspect however, that by planning to launch its new console early Nintendo may have blown those plans out of the water.jabber - Sunday, June 19, 2011 - link
I'm pretty sure the hardware specs for both the next Xbox and Playstation have been set in stone already.I'm still betting on a 2013 release too.
So right now GPU wise I reckon we're looking at GPUs currently sitting in the $100 range for both boxes. By 2013, the cost of these chips (suitably modified) will be down to $15 -$10 a box.
I wouldnt have thought anything higher than a 5770 or 450 would be suitable/required.
Targon - Monday, June 20, 2011 - link
It all depends on what you expect. Things feel a bit stagnant on the PC game front because consoles are not evolving, and too many companies want almost exactly the same experience on the PC version as what you have on the console.Stargrazer - Saturday, June 18, 2011 - link
Something doesn't feel right here. In itself, SIMD is about *Data* Level Parallelism, not Thread Level Parallelism. Sure, you could use SIMD units as part of some larger scheme that exploits TLP, but that's not what *SIMD* is about.
Loki726 - Saturday, June 18, 2011 - link
If you use a strict definition of a SIMD programming model, then yes, you are probably right: SIMD is a single sequence of operations executed over multiple data elements.However, over time SIMD has been used to refer to both the aforementioned programming model and the hardware used to implement it. The hardware typically consists of a single control unit that broadcasts instructions to multiple functional units. When people say "a SIMD", they typically mean that hardware implementation rather than the computing model.
If that wasn't confusing enough, in the 1980s GPUs started using that SIMD hardware to execute multiple threads as long as the threads were all executing the same instruction at the same time.
So the statement about using "a SIMD" to exploit TLP is accurate, if you take "a SIMD" to mean a processor pipeline with a single control unit that broadcasts to multiple functional units, and have some scheme for scheduling threads onto functional units.
RedemptionAD - Saturday, June 18, 2011 - link
It seems like a good thing potentially. I hope that their good intentions are followed with good execution, at least better than Fermi.Targon - Sunday, June 19, 2011 - link
It should be interesting going forward. Now that AMD is finally into the 32nm process node, standalone GPUs also stand to gain quite a bit. As long as graphics don't become an afterthought to GPGPU, AMD should be in good shape. Radeon 7970(if that is the next generation GPU) may really be a game changer.Navier - Saturday, June 18, 2011 - link
Will the GCN architecture be able to be virtualized? Can a VMWare/XEN/KVM/HyperV hypervisor create vGPUs accessible by VMs in much the same way as vCPUs are today? With GPUs being integrated within the CPU package it would be a waste of resources if it could not be virtualized.This will become a critical feature for enterprise computing beyond HPC applications. One example would be gaming in a cloud computing environment, where a company provides a service that runs a game on their compute and graphics hardware for a game and streams the output to your mobile device for you to enjoy.
hechacker1 - Saturday, June 18, 2011 - link
Yeah I'm also curious about this. Perhaps with the IOMMU and other CPU like features that the GPU now has, it would be much easier to timeshare the GPU.