AMD's Radeon HD 6790: Coming Up Short At $150
by Ryan Smith on April 5, 2011 12:01 AM ESTCompute & Tessellation
Moving on from our look at gaming performance, we have our customary look at compute performance, bundled with a look at theoretical tessellation performance.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.
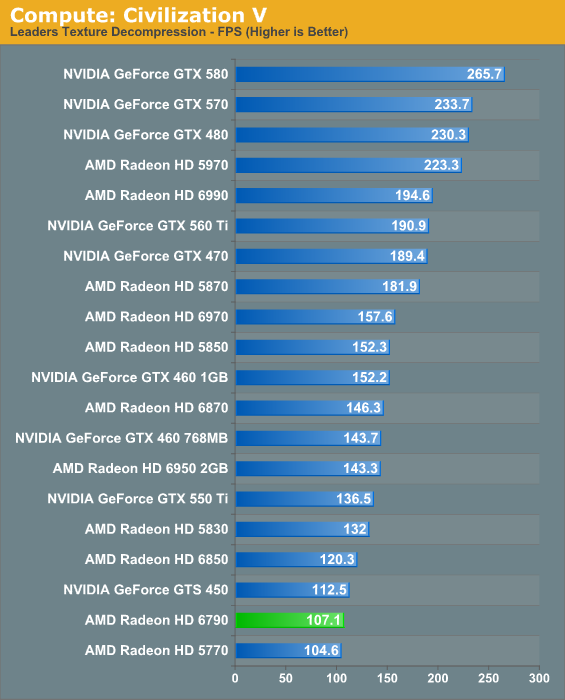
Civilization V’s compute benchmark cares little for memory bandwidth or the architectural differences between Barts and Juniper; SPs and clockspeed are what matter here. As a result the 6790 narrowly averts a tie with the 5770 of all things, and the performance relative to NVIDIA’s cards isn’t any better.
Our second GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.
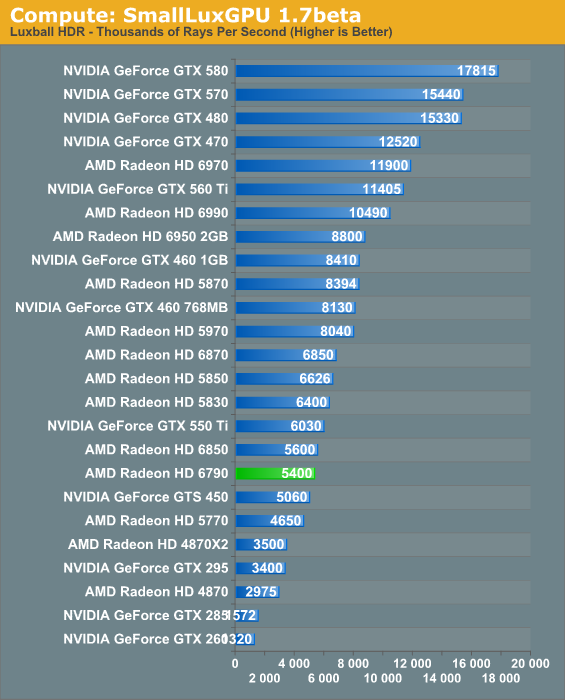
SmallLuxGPU ends up being one of the best showings for the 6790, as while it’s obviously compute bound, it definitely benefits from the architectural differences between Barts and Juniper. The 6790’s performance relative to the 6850 almost identically matches the theoretical performance difference, and in spite of the 5770 having a slight theoretical advantage of its own, the 6790 easily beats the 5770 by 16%. This opens up a small window for the 6790 as a lower-priced GPGPU product, but it’s a very small window – the program would need to excel on AMD cards and on Barts over Juniper. Otherwise we see SLG where the 6790 does well versus the 5770, but very poorly compared to NVIDIA’s cards.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. Barts’ tessellation improvements should give it an edge over the 5770, but it still has to contend with the 6800 series.
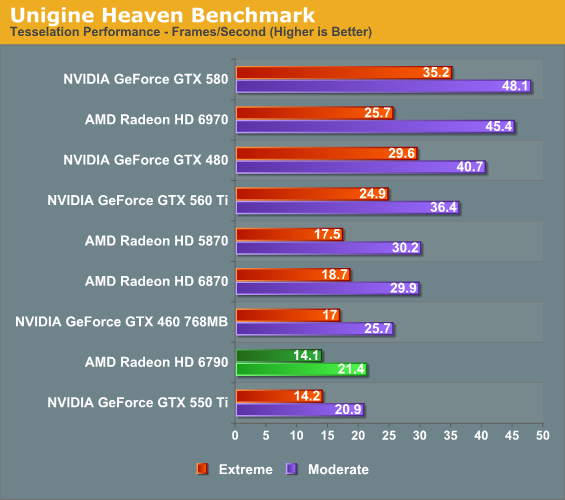

At this point in time none of our games closely match our tessellation results, which shouldn’t be a surprise given the low usage of tessellation. Although Barts isn’t a tessellation monster it could do quite well in the future if tessellation takes off in a manner similar to how these benchmarks use it, but that’s a very big if.








69 Comments
View All Comments
Amoro - Tuesday, April 5, 2011 - link
I'm pretty sure that only Cayman is VLIW4.Ryan Smith - Tuesday, April 5, 2011 - link
Correct. NI is a very broad family; it doesn't definite a single architecture. Cayman is VLIW4, Barts, Turks, and Caicos are VLIW5 and are basically optimized versions of Evergreen (5000 series) hardware.http://www.anandtech.com/show/3987/amds-radeon-687...
Amoro - Tuesday, April 5, 2011 - link
If you look at some of the raw performance specifications for the two cards it seems to indicate that texture fillrate and raw processing power don't have as much of an impact on Anandtech's testing suite.Radeon HD 5830
Fillrates
12.8GP/s
44.8GT/s
Memory Bandwidth
128GB/s
GFLOPS
1792
Radeon HD 6790
Fillrates
13.4GP/s
33.6GT/s
Memory Bandwidth
134.4GB/s
GFLOPS
1344
The 6790 wins in pixel fillrate and memory bandwidth but loses horribly in raw processing power and texture fillrate yet it still manages to keep within -10% and even manages to beat the 5830 in some cases.
BoFox - Wednesday, April 6, 2011 - link
Thanks for some more of those numbers!We can see that the 5830 has far higher numbers in these areas:
44.8 GT/s
1790 GFLOPs
And the 6790 has only
33.6 GT/s
1344 GFLOPs
While the 6790 has greater pixel fillrate and memory bandwidth than the 5830.
If it were not for VLIW4, why is the 5830 only 2-3% faster than 6790 in this review here, if you look at all of the benchmarks? Why?
Another way we could find out is to see how much it affects DP performance in applications like Milkyway@home. Cards with VLIW4 should have 1/4 the FP64 output ratio to FP32 output, so I wouldn't be surprised if we see 6790's being 20% faster than the similarly spec'ed 4890.
BoFox - Thursday, April 7, 2011 - link
Ahh, your article reminded me that FP64 was disabled for Barts GPUs.. I must've forgot about it and wanted to test it to prove that it's VLIW4.But the numbers in the replies below strongly point to the 6790 being boosted by VLIW4 in order to basically match up to a 5830 with 40% more shaders and TMU's.
Any explanation for this, sir Ryan?
BoFox - Friday, April 8, 2011 - link
RE: "From a graphics point of view it's not possible to separate the performance of the ROPs from memory bandwidth. Color fill, etc are equally impacted by both. To analyze bandwidth you'd have to work from a compute point of view. However with that said I don't have any reason to believe AMD doesn't have a 256-bit; achieving identical performance with half the L2 cache will be harder though."1) If it's not possible to separate the performance from a "graphics" rather than "compute" point of view, then should not the performance be linked for all "graphics" point of views (as it is a "graphics" card to begin with)? Even the "compute" applications (FP16 and FP32 analysis at http://www.behardware.com/articles/783- ... -5830.html ) show the card to behave like as if it's 128-bit.
2) Why does Ryan not have any reason to believe.. because AMD said so? If a manufacturer of a LCD panel advertises 1ms G2G response time, but it looks like 16ms, does he still have no reason to believe it's 16ms just because the manufacturer said so?
3) If the L2 cache is cut down in proportion with the castrated shaders/TMUs/ROPs, then it should not affect performance, let alone "harder though".
Soldier1969 - Tuesday, April 5, 2011 - link
2 x 6970s FTW at 2560 x 1600 res.JimmiG - Tuesday, April 5, 2011 - link
Is it just me or is all this talk about price difference of $10 or less getting a little ridiculous? I mean, if you're prepared to spend $150 (or $160...) on something that is completely non-essential, what difference is $10 going to make? If you're so poor that $10 is a big deal, you're probably not spending your money on gaming products anyway since you need everything for stuff like food and rent.It seems the video card companies are the guilty ones, constantly trying to outmaneuver each other with new pricing schemes. I miss the old days when there was one $100 card, one $200 card, one $300 card etc. Now there can easily be a dozen different models in the range of $100 - $300.
liveonc - Tuesday, April 5, 2011 - link
This looks like a prime candidate for a mini-ITX for those who'd want a desktop replacement, but don't want to pay so damn much for something that has 30minutes of battery life, doesn't have a chance to outperform a desktop, & costs too much.lorribot - Tuesday, April 5, 2011 - link
Might be just me but since the 4000 series i dont actually understand AMDs numbering scheme anymore.There seem to be a great variety of of 6000 cards all with very similar performance and different prices.
There is the 6990 at the top then a couple more 69xx cards then some 68xx and some 67xx, all well and good but it seems the 5870 is faster card then the 6870, which is odd and not what i would have expected, indeed it has similar performance to the 5850.
The 5xxx series came in 53, 54, 55, 56, 57, 58 and 59 flavours with one, two or three sub versions in each band giving something like 15 or 16 different cards.
It seems to me that with so many variations and a numbering scheme that seems to change from version to version AMD seem to actually want to confuse the buying public.
They really need to get a handle on this, less is more in some cases.
Nvidia's numbering scheme on the whole seems to be much more sensible in recent times, apart from the odd hiccup with 460 and 465.