10G Ethernet: More Than a Big Pipe
by Johan De Gelas on November 24, 2010 2:34 PM EST- Posted in
- IT Computing
- Networking
- 10G Ethernet
Solving the Virtualization I/O Puzzle
Step One: IOMMU, VT-d
The solution for the high CPU load, higher latency, and lower throughput comes in three steps. The first solution was to bypass the hypervisor and assign a certain NIC directly to the network intensive VM. This approach gives several advantages. The VM has direct access to a native device driver, and as such can use every hardware acceleration feature that is available. The NIC is also not shared, thus all the queues and buffers are available to one VM.
However, even though the hypervisor lets the VM directly access the native driver, a virtual machine cannot bypass the hypervisor’s memory management. The guest OS inside that VM does not have access to the real physical memory, but to a virtual memory map that is managed by the hypervisor. So when the hypervisor sends out addresses to the driver, it sends out virtual addresses instead of the expected physical ones (the white arrow).
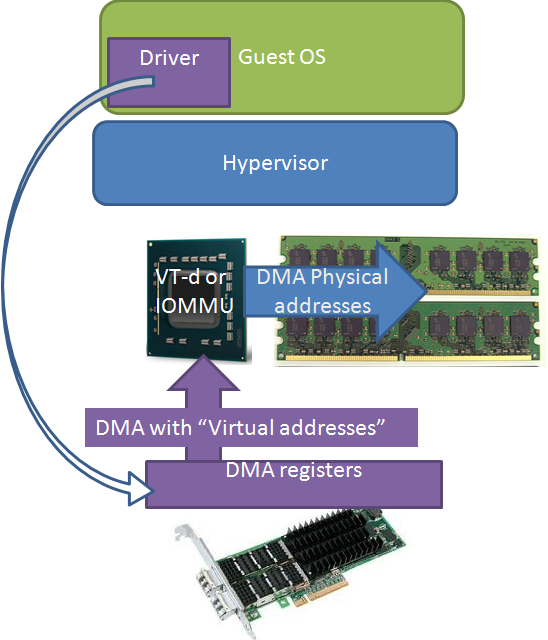
Intel solved this with VT-d, AMD with the “new” (*) IOMMU. The I/O hub translates the virtual or “guest OS fake physical” addresses (purple) into real physical addresses (blue). This new IOMMU also isolates the different I/O devices from each other by allocating different subsets of physical memory to the different devices.
Very few virtualized servers use this feature as it made virtual machine migration impossible. Instead of decoupling the virtual machine from the underlying hardware, direct assignment firmly connected the VM to the underlying hardware. So the AMD IOMMU and Intel VT-d technology is not that useful alone. It is just one of the three pieces of the I/O Virtualization puzzle.
(*) There is also an "old IOMMU" or Graphics Address Remapping Table which did address translations for letting the graphics card access the main memory.
Step Two: Multiple Queues
The next step was making the NIC a lot more powerful. Instead of letting the hypervisor sort all the received packages and send them off to the right VM, the NIC becomes a complete hardware switch that sorts all packages into multiple queues, one for each VM. This gives a lot of advantages.
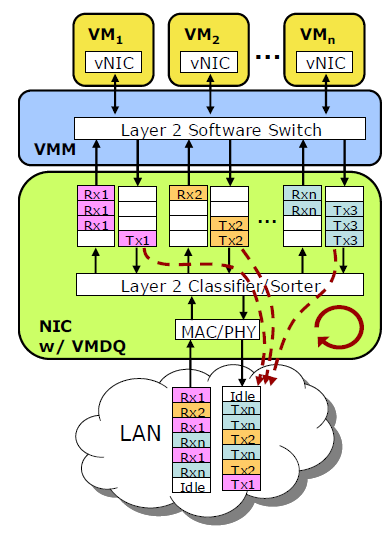
Less interrupts and CPU load. If you let the hypervisor handle the packet switching, it means that CPU 0 (which is in most cases is the one doing the hypervisor tasks) is interrupted and has to examine the received package and determine the destination VM. That destination VM and the associated CPU has to be interrupted. With a hardware switch in the NIC, the package is immediately sent into the right queue, and the right CPU is immediately interrupted to come and get the package.
Less latency. A single queue for multiple VMs that receive and transmit packages can get overwhelmed and drop packets. By giving each VM its own queue, throughput is higher and latency is lower.
Although Virtual Machine Devices Queues solves a lot of problems, there is still some CPU overhead left. Every time the CPU of a certain VM is interrupted, the hypervisor has to copy the data from the hypervisor space into the VM memory space.








38 Comments
View All Comments
fr500 - Wednesday, November 24, 2010 - link
I guess there is LACP or PAGP and some propietary solution.A quick google told me it's called cross-module trunking.
mlambert - Wednesday, November 24, 2010 - link
FCoE, iSCSI (*not that you would, but you could), FC, and IP all across the same link. Cisco offers VCP LACP with CNA as well. 2 links per server, 2 links per storage controller, thats not many cables.mlambert - Wednesday, November 24, 2010 - link
I meant VPC and Cisco is the only one that offers it today. I'm sure Brocade will in the near future.Zok - Friday, November 26, 2010 - link
Brocade's been doing this for a while with the Brocade 8000 (similar to the Nexus 5000), but their new new VDX series takes it a step further for FCoE.Havor - Wednesday, November 24, 2010 - link
Do these network adapters are real nice for servers, don't need a manged NIC, i just really want affordable 10Gbit over UTP ore STP.Even if its only 30~40M / 100ft because just like whit 100Mbit network in the old days my HDs are more then a little out preforming my network.
Wondering when 10Gbit will become common on mobos.
Krobar - Thursday, November 25, 2010 - link
Hi Johan,Wanted to say nice article first of all, you pretty much make the IT/Pro section what it is.
In the descriptions of the cards and conclusion you didnt mention Solarflares "Legacy" Xen netfront support. This only works for paravirt Linux VMs and requires a couple of extra options at kernal compile time but it run like a train and requires no special hardware support from the motherboard at all. None of the other brands support this.
marraco - Thursday, November 25, 2010 - link
I once made a resume of total cost of the network on the building where I work.Total cost of network cables was far larger than the cost of the equipment (at least with my country prices). Also, solving any cable related problem was a complete hell. The cables were hundreds, all entangled over the false roof.
I would happily replace all that for 2 of tree cables with cheap switches at the end. Selling the cables would pay for new equipment and even give a profit.
Each computer has his own cable to the central switch. A crazy design.
mino - Thursday, November 25, 2010 - link
IF you go 10G for cable consolidation, you better forget about cheap switches.The real saving are in the manpower, not the cables themselves.
myxiplx - Thursday, November 25, 2010 - link
If you're using a Supermicro Twin2, why don't you use the option for the on board Mellanox ConnectX-2? Supermicro have informed me that with a firmware update these will act as 10G Ethernet cards, and Mellanox's 10G Ethernet range has full support for SR-IOV:Main product page:
http://www.mellanox.com/content/pages.php?pg=produ...
Native support in XenServer 5:
http://www.mellanox.com/content/pages.php?pg=produ...
AeroWB - Thursday, November 25, 2010 - link
Nice Article,It is great to see more test around virtual environments. What surprises me a little bit is that at the start of the article you say that ESXi and Hyper-V do not support SR-IOV yet. So I was kind of expecting a test with Citrix Xenserver to show the advantages of that. Unfortunately it's not there. I hope you can do that in the near future.
I work with both Vmware ESX and Citrix XenServer we have a live setup of both. We started with ESX and later added a XenServer system, but as XenServer is getting more mature and gets more and more features we probably replace the ESX setup with XenServer (as it is much much cheaper) when maintenance runs out in about one year so I'm really interested in tests on that platform.