10G Ethernet: More Than a Big Pipe
by Johan De Gelas on November 24, 2010 2:34 PM EST- Posted in
- IT Computing
- Networking
- 10G Ethernet
The Final Piece of the Puzzle: SR-IOV
The final step is to add a few buffers and Rx/Tx descriptors to each queue of your multi-queued device, and a single NIC can pretend to be a collection of tens of “small” NICs. That is what PCI SIG did, and they call each small NIC a virtual function. According to the PCI SIG SR-IOV specification you can have up to 256 (!) virtual functions per NIC. (Note: the SR-IOV specification is not limited to NICs; other I/O devices can be SR-IOV capable too.)
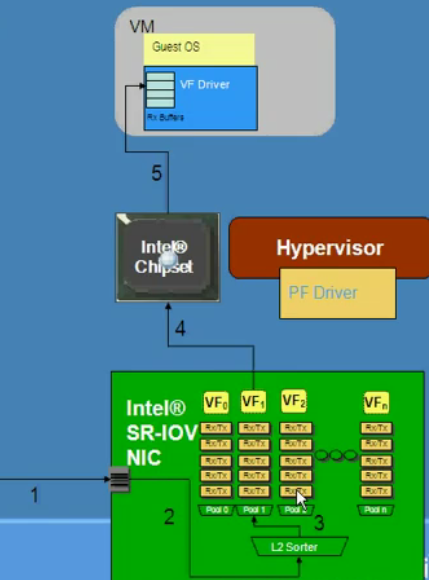
Courtesy of the excellent Youtube movie: "Intel SR-IOV"
Make sure there is a chipset with IOMMU/VT-d inside the system. The end result: each of those virtual functions can DMA packets in and out without any help of the hypervisor. That means that it is not necessary anymore for the CPU to copy the packages from the memory space of the NIC to the memory space of the VM. The VT-d/IOMMU capable chipset ensures that the DMA transfers of the virtual functions happen and do not interfere with each other. The beauty is that the VMs are connecting to these virtual functions by a standard paravirtualized driver (such as VMXnet in VMware), and as a result you should be able to migrate VMs without any trouble.
There you have it: all puzzles pieces are there. Multiple queues, virtual to physical address translation for DMA transfers, and a multi-headed NIC offer you higher throughput, lower latency, and lower CPU overhead than emulated hardware. At the same time, they offer the two advantages that made virtualized emulated hardware so popular: the ability to share one hardware device across several VMs and the ability to decouple the virtual machine from the underlying hardware.
SR-IOV Support
Of course, this is all theory until all software and hardware layers work together to support this. You need a VT-d or IOMMU chipset, the motherboard’s BIOS has to adapted to recognize all those virtual functions, and each virtual function must get memory mapped IO space like other PCI devices. A hypervisor that supports SR-IOV is also necessary. Last but not least, the NIC vendor has to provide you with an SR-IOV capable driver for the operating system and hypervisor of your choice.
With some help of mighty Intel, the opensource hypervisors (Xen, KVM) and the commercial product derivatives (Redhat, Citrix) were first to market with SR-IOV. At the end of 2009, both Xen and KVM had support for SR-IOV, more specifically for Intel 10G Ethernet 82599 controller. The Intel 82599 can offer up to 64 VFs. Citrix announced support for SR-IOV in Xenserver 5.6, so the only ones missing in action are VMware’s ESX and Microsoft’s Hyper-V.








38 Comments
View All Comments
mino - Thursday, November 25, 2010 - link
Well the main issue with 10G, especially copper, is that the medium frequencies are nowhere near FC.Then there is the protocol overhead for iSCSI, FCoE is musch better in that respect though.
That IOps measure was a reliably achievable peak - meaning generally with <4k IO operations.
10k on Gbit can be done in the lab easily, but it was not sustainable/reliable-enough to consider it for production use.
Those disk arrays have caches, today they even have SSD's etc. etc. then there is the dark fiber DR link one has to wait for ...
But yes, in a typical virtualized web-serving or SMB scenario 10G makes all the sense in the world.
All I ask is that you generally not dismiss FC without discussing its strengths.
It is a real pain explaining to a CIO why 10G will not work out when a generally reputable site AT says it is just "better" than FC.
JohanAnandtech - Thursday, November 25, 2010 - link
I do not dismiss FC. You are right that we should add FC to the mix. I'll do my best to get this is in another article. That way we can see if the total latency (= actual response times) are really worse on iSCSI than on FC.Then again, it is clear that if you (could) benefit from 8 gbit/s FC now, consolidating everything into a 10 Gbit pipe is a bad idea. I really doubt 10 GbE iSCSI is worse than 4 Gb FC, but as always, the only way to check this, is to measure.
gdahlm - Thursday, November 25, 2010 - link
The main issue is that Ethernet is designed to drop packets. This means that to be safe all iSCSI writes need to be synchronous and this means you will be hitting the disks hard or you are going to risk data loss if congestion starts dropping packets or you fill your ring buffer etc..Even with ZFS and a SSD ZIL you will be slower then ram based WriteBack Cache.
As an example here are some filebench oltp results from a linux based host to a zfs array over 4GB FC.
Now this is a pretty cheap array but will show the difference between a SSD backed ZIL and using the memory in writeback mode.
Host: noop elevator with Direct IO to SSD ZIL
6472: 77.657: IO Summary: 486127 ops, 8099.587 ops/s, (4040/4018 r/w), 31.6mb/s, 683us cpu/op, 48.4ms latency
Host: noop elevator with Direct IO with WB cache on the target.
18042: 73.066: IO Summary: 767336 ops, 12778.487 ops/s, (6373/6340 r/w), 50.0mb/s, 481us cpu/op, 29.6ms latency
Basic FC switches are cheap compared to 10gig switches at this point in time too.
JohanAnandtech - Friday, November 26, 2010 - link
"The main issue is that Ethernet is designed to drop packets. This means that to be safe all iSCSI writes need to be synchronous"IMHO, this only means that congestion is a worse thing for iSCSI (so you need a bit more headroom). Why would writes not be async? Once you hit the cache of your iSCSI target, the packets are in the cache, Ethernet is not involved anymore. So a smart controller can perform writes async. As matt showed with his ZFS article.
"Even with ZFS and a SSD ZIL you will be slower then ram based WriteBack Cache."
Why would write back cache not be possible with iSCSI?
"Basic FC switches are cheap compared to 10gig switches at this point in time too. "
We just bought a 10GbE switch from Dell: about $8000 for 24 ports. Lots of 24 port FC Switches are quite a bit more expensive. It is only a matter of time before 10GbE switches are much cheaper.
Also, with VLAN, the 10GbE can be used for both network as SAN traffic.
gdahlm - Friday, November 26, 2010 - link
I may be missing the part where Matt talked about async on ZFS. I only see where he was discussing using SSDs for an external ZIL. However writing to the ZIL is not an async write, it is fully committed to disk even if that commit is happening on an external log device.There are several vendors who do support async iSCSI writes using battery backed cache etc.. But to move up into the 10G performance level puts them at a price point where the costs of switches is fairly trivial.
iSCSI is obviously is a route-able protocol and thus often it is not just traversing one top of rack switch. Due to this lots of targets and initiators tend to be configured a conservative manor. COMSTAR is one such product, all COMSTAR iSCSI writes are synchronous, thus the reason you gain any advantage from an external ZIL. It appears that the developers assumed that FC storage is “reliable” and thus by default (at least in sol 11 express) zvols that are exported through COMSTAR are configured as writeback by default. You need to actually use stmfadm to specifically enable the honoring of sync writes and thus the use of the ZIL on pool or ssd.
I do agree that 10Gig Ethernet will be cheaper soon. I do not agree that it is cheaper at the moment.
Dell does have a 10GbE switch for about 8K but that is without the SFP modules. Qlogic has a 20 port 8GB switch that can be purchased for about 9K with the SFP modules.
If you have a need for policy on your network side or other advanced features the cost per port for 10GbE goes up dramatically.
I do fully expect that this cost difference will change dramatically over the next 12 months.
Ideally had SUN not been sold when they were we would probably have a usable SAS target today, but it appears that work on the driver has stopped.
This would have enabled the use of LSI's SAS switches which are dirt cheap to provide full 4 lane 6Gbs connectivity to hosts through truly inexpensive SAS HBAs.
Photubias - Friday, November 26, 2010 - link
quote "That same vendor has observed the best 1GbE solutions choke at <5k IOps..."This guy achieves 20k IOPS through 1GbE: http://www.anandtech.com/show/3963/zfs-building-te... ?
blowfish - Wednesday, November 24, 2010 - link
Trying to read this article is making my brain hurt! ;(It surprises me to see what looks like pci connectors on the NIC;s though. Are servers slower to adopt new interfaces?
Alroys - Wednesday, November 24, 2010 - link
They are not PCI, they actually are PCIe x8.blowfish - Thursday, November 25, 2010 - link
oh, thanks for the clarification!blandead - Wednesday, November 24, 2010 - link
On that note, does anyone know how to combine ports to aggregate with an extreme switch rather than a fail-over solution like as mentioned above.. combining 1GbE ports. Just a general idea of commands will point me in right direction : )Much appreciated if anyone replies!