The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTI Keep My Cache Private
As mentioned in the original Skylake-X announcements, the new Skylake-SP cores have shaken up the cache hierarchy compared to previous generations. What used to be simple inclusive caches have now been adjusted in size, policy, latency, and efficiency, which will have a direct impact on performance. It also means that Skylake-S and Skylake-SP will have different instruction throughput efficiency levels. They could be the difference between chalk and cheese and a result, or the difference between stilton and aged stilton.
Let us start with a direct compare of Skylake-S and Skylake-SP.
| Comparison: Skylake-S and Skylake-SP Caches | ||
| Skylake-S | Features | Skylake-SP |
| 32 KB 8-way 4-cycle 4KB 64-entry 4-way TLB |
L1-D | 32 KB 8-way 4-cycle 4KB 64-entry 4-way TLB |
| 32 KB 8-way 4KB 128-entry 8-way TLB |
L1-I | 32 KB 8-way 4KB 128-entry 8-way TLB |
| 256 KB 4-way 11-cycle 4KB 1536-entry 12-way TLB Inclusive |
L2 | 1 MB 16-way 11-13 cycle 4KB 1536-entry 12-way TLB Inclusive |
| < 2 MB/core Up to 16-way 44-cycle Inclusive |
L3 | 1.375 MB/core 11-way 77-cycle Non-inclusive |
The new core keeps the same L1D and L1I cache structures, both implementing writeback 32KB 8-way caches for each. These caches have a 4-cycle access latency, but differ in their access support: Skylake-S does 2x32-byte loads and 1x32-byte store per cycle, whereas Skylake-SP offers double on both.
The big changes are with the L2 and the L3. Skylake-SP has a 1MB private L2 cache with 16-way associativity, compared to the 256KB private L2 cache with 4-way associativity in Skylake-S. The L3 changes to an 11-way non-inclusive 1.375MB/core, from a 20-way fully-inclusive 2.5MB/core arrangement.
That’s a lot to unpack, so let’s start with inclusivity:
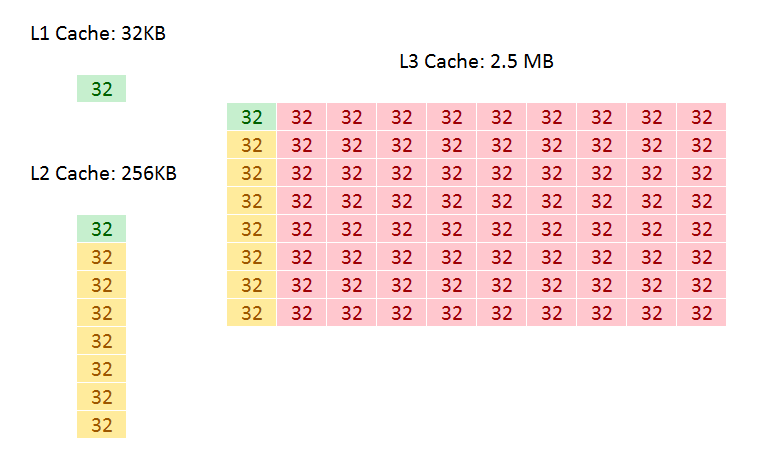
Inclusive Caching
An inclusive cache contains everything in the cache underneath it and has to be at least the same size as the cache underneath (and usually a lot bigger), compared to an exclusive cache which has none of the data in the cache underneath it. The benefit of an inclusive cache means that if a line in the lower cache is removed due it being old for other data, there should still be a copy in the cache above it which can be called upon. The downside is that the cache above it has to be huge – with Skylake-S we have a 256KB L2 and a 2.5MB/core L3, meaning that the L2 data could be replaced 10 times before a line is evicted from the L3.
A non-inclusive cache is somewhat between the two, and is different to an exclusive cache: in this context, when a data line is present in the L2, it does not immediately go into L3. If the value in L2 is modified or evicted, the data then moves into L3, storing an older copy. (The reason it is not called an exclusive cache is because the data can be re-read from L3 to L2 and still remain in the L3). This is what we usually call a victim cache, depending on if the core can prefetch data into L2 only or L2 and L3 as required. In this case, we believe the SKL-SP core cannot prefetch into L3, making the L3 a victim cache similar to what we see on Zen, or Intel’s first eDRAM parts on Broadwell. Victim caches usually have limited roles, especially when they are similar in size to the cache below it (if a line is evicted from a large L2, what are the chances you’ll need it again so soon), but some workloads that require a large reuse of recent data that spills out of L2 will see some benefit.
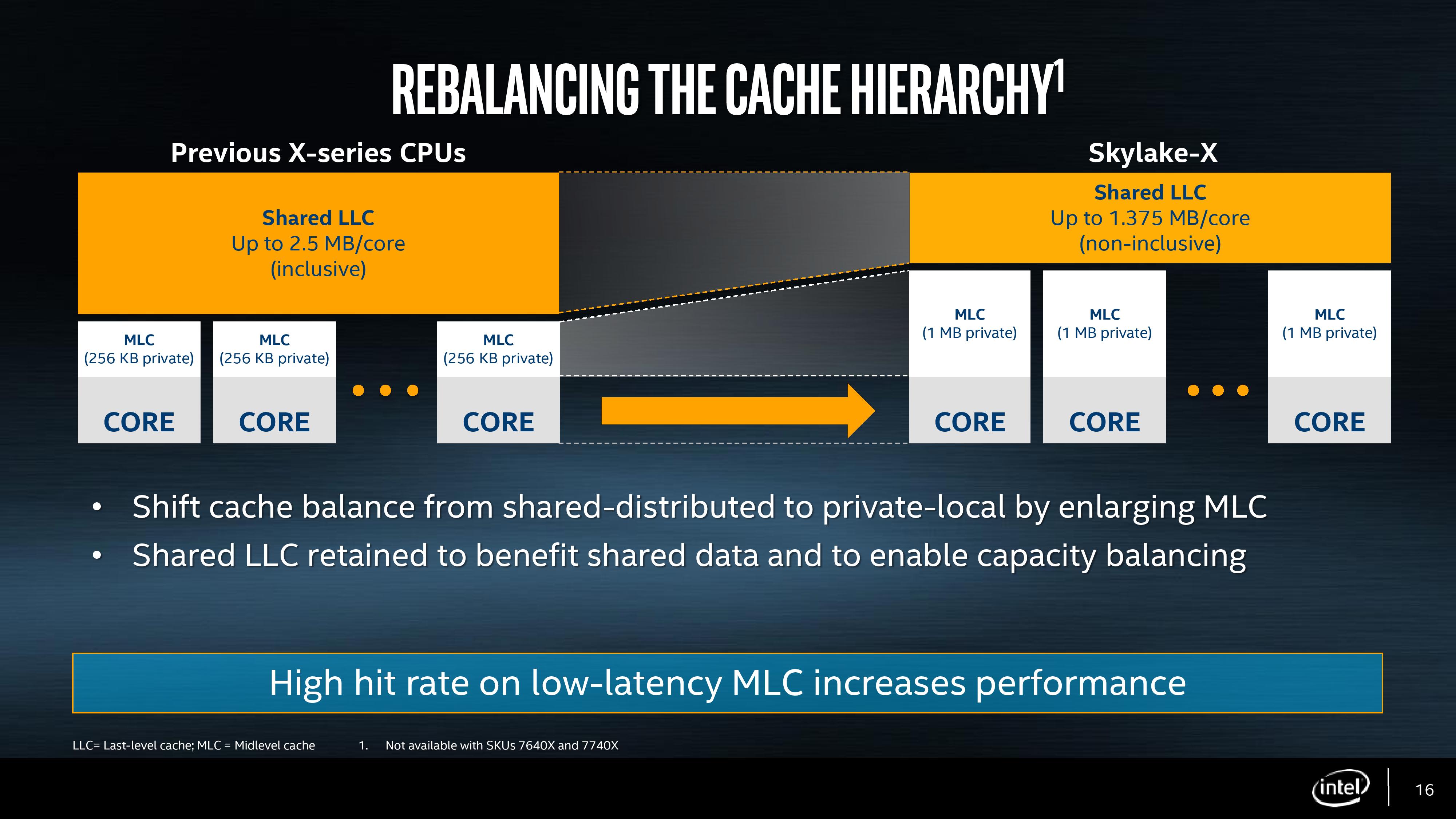
So why move to a victim cache on the L3? Intel’s goal here was the larger private L2. By moving from 256KB to 1MB, that’s a double double increase. A general rule of thumb is that a doubling of the cache increases the hit rate by 41% (square root of 2), which can be the equivalent to a 3-5% IPC uplift. By doing a double double (as well as doing the double double on the associativity), Intel is effectively halving the L2 miss rate with the same prefetch rules. Normally this benefits any L2 size sensitive workloads, which some enterprise environments such as databases can be L2 size sensitive (and we fully suspect that a larger L2 came at the request of the cloud providers).
Moving to a larger cache typically increases latency. Intel is stating that the L2 latency has increased, from 11 cycles to ~13, depending on the type of access – the fastest load-to-use is expected to be 13 cycles. Adjusting the latency of the L2 cache is going to have a knock-on effect given that codes that are not L2 size sensitive might still be affected.
So if the L2 is larger and has a higher latency, does that mean the smaller L3 is lower latency? Unfortunately not, given the size of the L2 and a number of other factors – with the L3 being a victim cache, it is typically used less frequency so Intel can give the L3 less stringent requirements to remain stable. In this case the latency has increased from 44 in SKL-X to 77 in SKL-SP. That’s a sizeable difference, but again, given the utility of the victim cache it might make little difference to most software.
Moving the L3 to a non-inclusive cache will also have repercussions for some of Intel’s enterprise features. Back at the Broadwell-EP Xeon launch, one of the features provided was L3 cache partitioning, allowing limited size virtual machines to hog most of the L3 cache if it was running a mission-critical workflow. Because the L3 cache was more important, this was a good feature to add. Intel won’t say how this feature has evolved with the Skylake-SP core at this time, as we will probably have to wait until that launch to find out.
As a side note, it is worth noting here that Broadwell-E was a 256KB private L2 but 8-way, compared to Skylake-S which was a 256KB private L2 but 4-way. Intel stated that the Skylake-S base core went down in associativity for several reasons, but the main one was to make the design more modular. In this case it means the L2 in both size and associativity are 4x from Skylake-S by design, and shows that there may be 512KB 8-way variants in the future.








264 Comments
View All Comments
mat9v - Tuesday, June 20, 2017 - link
To play it safe, invest in the Core i9-7900X today.To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.
Then the conclusion should have been - wait for fixed platform. I'm not even suggesting choosing Ryzen as it performs slower but encouraging buying flawed (for now) platform?
mat9v - Tuesday, June 20, 2017 - link
Please then correct tables on 1st page comparing Ryzen and 7820X and 7800X to state that Intel has 24 lines as they leave 24 for PCIEx slots and 4 is reserved for DMI 3.0If you strip Ryzen lines to only show those available for PCIEx do so for Intel too.
Ryan Smith - Wednesday, June 21, 2017 - link
The tables are correct. The i7 7800 series have 28 PCIe lanes from the CPU for general use, and another 4 DMI lanes for the chipset.PeterCordes - Tuesday, June 20, 2017 - link
Nice article, thanks for the details on the microarchitectural changes, especially to execution units and cache. This explains memory bandwidth vs. working-set size results I observed a couple months ago on Google Compute Engine's Skylake-Xeon VMs with ~55MB of L3: The L2-L3 transition was well beyond 256kB. I had assumed Intel wouldn't use a different L3 cache design for SKX vs. SKL, but large L2 doesn't make much sense with an inclusive L3 of 2 or 2.5MB per core.Anyway, some corrections for page3: The allocation queue (IDQ) is in Skylake-S is always 64 uops, with or without HT. For example, I looked at the `lsd.uops` performance counter in a loop with 97 uops on my i7-6700k. For 97 billion counts of uops_issued.any, I got exactly 0 counts of lsd.uops, with the system otherwise idle. (And I looked at cpu_clk_unhalted.one_thread_active to make sure it was really operating in non-HT mode the majority of the time it was executing.) Also, IIRC, Intel's optimization manual explicitly states that the IDQ is always 64 entries in Skylake.
The scheduler (aka RS or Reservation Station) is 97 unfused-domain uops in Skylake, up from 60 in Haswell. The 180int / 168fp numbers you give are the int / fp register-file sizes. They are sized more like the ROB (224 fused-domain uops, up from 192 in Haswell), not the scheduler, since like the ROB, they have to hold onto values until retirement, not just until execution. See also http://blog.stuffedcow.net/2013/05/measuring-rob-c... for when the PRF size vs. the ROB is the limit on the out-of-order window. See also http://www.realworldtech.com/haswell-cpu/6/ for a nice block diagram of the whole pipeline.
SKL-S DIVPS *latency* is 11 cycles, not 3. The *throughput* is one per 3 cycles for 128-bit vectors, or one per 5 cycles for 256b vectors, according to Agner Fog's table. I forget if I've tested that myself. So are you saying that SKL-SP has one per 5 cycle throughput for 128-bit vectors? What's the throughput for 256b and 512b vectors?
-----
It's really confusing the way you keep saying "AVX unit" or "AVX-512 unit" when I think you mean "512b FMA unit". It sounds like vector-integer, shuffle, and pretty much everything other than FMA will have true 512b execution units. If that's correct, then video codecs like x264/x265 should run the same on LCC vs. HCC silicon (other than differences in mesh interconnect latency), because they're integer-only, not using any vector-FP multiply/add/FMA.
-------
> This should allow programmers to separate control flow from data flow...
SIMD conditional operations without AVX512 are already done branchlessly (I think that's what you mean by separate from control-flow) by masking the input and/or output. e.g. to conditionally add some elements of a vector, AND the input with a vector of all-one or all-zero elements (as produced by CMPPS or PGMPEQD, for example). Adding all-zeros is a no-op (the additive identity).
Mask registers and support for doing it as part of another operation makes it much more efficient, potentially making it a win to vectorize things that otherwise wouldn't be. But it's not a new capability; you can do the same thing with boolean vectors and SSE/AVX VPBLENDVPS.
PeterCordes - Tuesday, June 20, 2017 - link
Speed Shift / Hardware P-State is not Windows-specific, but this article kind of reads as if it is.Your article doesn't mention any other OSes, so nothing it says is actually wrong: I'm sure it did require Intel's collaboration with MS to get support into Win10. The bullet-point in the image that says "Collaboration between Intel and Microsoft specifically for W10 + Skylake" may be going too far, though. That definitely implies that it only works on Win10, which is incorrect.
Linux has supported it for a while. "HWP enabled" in your kernel log means the kernel has handed off P-state selection to the hardware. (Since Linux is open-source, Intel contributed most of the code for this through the regular channels, like they do for lots of other drivers.)
dmesg | grep intel_pstate
[ 1.040265] intel_pstate: Intel P-state driver initializing
[ 1.040924] intel_pstate: HWP enabled
The hardware exposes a knob that controls the tradeoff between power and performance, called Energy Performance Preference or EPP. Len Brown@Intel's Linux patch notes give a pretty good description of it (and how it's different from a similar knob for controlling turbo usage in previous uarches), as well as describing how to use it from Linux. https://patchwork.kernel.org/patch/9723427/.
# CPU features related to HWP, on an i7-6700k running Linux 4.11 on bare metal
fgrep -m1 flags /proc/cpuinfo | grep -o 'hwp[_a-z]*'
hwp
hwp_notify
hwp_act_window
hwp_epp
I find the simplest way to see what speed your cores are running is to just `grep MHz /proc/cpuinfo`. (It does accurately reflect the current situation; Linux finds out what the hardware is actually doing).
IDK about OS X support, but I assume Apple has got it sorted out by now, almost 2 years after SKL launch.
Arbie - Wednesday, June 21, 2017 - link
There are folks for whom every last compute cycle really matters to their job. They have to buy the technical best. If that's Intel, so be it.For those dealing more with 'want' than 'need', a lot of this debate misses an important fact. The only reason Intel is suddenly vomiting cores, defecating feature sizes, and pre-announcing more lakes than Wisonsin is... AMD. Despite its chronic financial weakness that company has, incredibly, come from waaaay behind and given us real competition again. In this ultra-high stakes investment game, can they do that twice? Maybe not. And Intel has shown us what to expect if they have no competitor. In this limited-supplier market it's not just about who has the hottest product - it's also about whom we should reward with our money, and about keeping vital players in the game.
I suggest - if you can, buy AMD. They have earned our support and it's in our best interests to do so. I've always gone with Intel but have lately come to see this bigger picture. It motivated me to buy an 1800X and I will also buy Vega.
Rabnor - Wednesday, June 21, 2017 - link
To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.You have to spend that $400+ on a good motherboard & aio cooler.
Are you sold by Intel, anandtech?
Synviks - Thursday, June 22, 2017 - link
For some extra comparison: running Cinebench R15 on my 14c 2.7ghz Haswell Xeon, with turbo to 3ghz on all cores, my score is 2010.Pretty impressive performance gain if they can shave off 4 cores and end up with higher performance.
Pri - Thursday, June 22, 2017 - link
On the first page you wrote this:Similarly, the 6-core Core i7-7820X at $599 goes up against the 8-core $499 Ryzen 7 1800X.
The Core i7 7820X was mistakenly written as a 6-core processor when it is in-fact an 8-core processor.
Kind Regards.
Gigabytes - Thursday, June 22, 2017 - link
Okay, here is what I learned from this article. Gaming performance sucks and you will be able to cook a pizza inside your case. Did I miss anything?Oh, one thing missing.
Play it SMART and wait to see the Ripper in action before buy your new Intel toaster oven.